Dynamic Audio Balancing Through Visual Importance Mapping
This development phase introduces sophisticated volume control based on visual importance analysis, creating audio mixes that dynamically reflect the compositional hierarchy of the original image. Where previous systems ensured semantic accuracy, we now ensure proportional acoustic representation.
The core advancement lies in importance-based volume scaling. Each detected object’s importance value (0-1 scale from visual analysis) now directly determines its loudness level within a configurable range (-30 dBFS to -20 dBFS). Visually dominant elements receive higher volume placement, while background objects maintain subtle presence.
Key enhancements include:
– Linear importance-to-volume mapping creating natural acoustic hierarchies
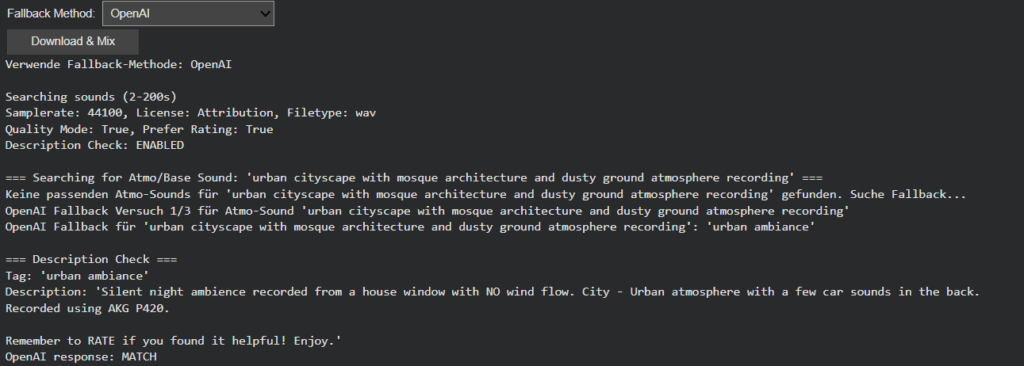
The system now distinguishes between foreground emphasis and background ambiance, producing mixes where a visually central “car” (importance 0.9) sounds appropriately prominent compared to a distant “tree” (importance 0.2), while “urban street atmo” provides unwavering environmental foundation.
This represents a significant evolution from flat audio layering to dynamically balanced soundscapes that respect visual composition through intelligent volume distribution.
Adomas Palekas’s master’s thesis, entitled Microbiophonic Emergences, could be described as an interdisciplinary mixture of artistic reflection, philosophical speculation, and experimental sound practice. Combining ecological thought and artistic research, the text examines the relationship between sound, life, and perception. Drawing upon the Gaia hypothesis and Goethean science, the author advances a more sensitive and ethical mode of listening wherein the boundaries between the art and scientific observation are dissolved.
Overall, the presentation of the work is considerate and visually well-structured, though it significantly deviates from academic conventions. A clearly defined research question, hypothesis, or structured methodology is lacking. Instead, the text comes across as a long essay on listening, nature, and non-human agency. Its first half is dedicated to theoretical reflections on sound as a living force, while the second half introduces a series of artistic experiments and installations entitled Kwass Fermenter, Microbial Music I–III (On Bread, Compost and Haze, Aerials), Rehydration, Infection, Spectrum of Mutations: Myosin III and Kwassic Motion. According to the author, these works constitute a coherent artistic ecosystem in which microorganisms and sonic feedback interact.
More conceptually, this framing of sonification as bi-directional means that sound should not just be generated from biological data but is also to be sent back into the system and used to affect it. Conceptually, this approach seeks to transform sonification into a dialogue rather than a representation. This claim of originality, however, feels somewhat overstated: bi-directional or feedback-based sonification has been explored conceptually and practically by many artists and researchers before him, mostly within the frames of bio-art and ecological sound practices. Palekas himself mentions only one precedent when, in fact, there exists a wide range of comparable works dealing with translating biological activity into sound and then re-introducing it into the same system. His treatment of the topic is therefore limited and without deep contextual awareness, giving the impression of a rediscovery of ideas that are well conceptualized in the discipline.
The artistic independence of the thesis and a strong, personal vision are explicit. Palekas’s voice is consistent; his writing also reflects genuine curiosity and sensitivity. But it is this very independence that alienates his research from the broader academic and artistic discourse. One misses the dialogue with other practitioners or with theoretical perspectives, except for the few philosophical sources mentioned above. The limited literature review weakens the credibility of his theoretical framework and makes it difficult to situate the work within contemporary sound studies or bio-art research.
The structuring of the thesis is much closer to a philosophical narrative than to a scientific report. The chapters are more intuitively than logically connected. Because explicit methodological framing is absent, the reader has to reconstruct the logic of the experiments from poetic descriptions. For example, the sonification tests with fermentation are told in narrative terms, sometimes mentioning sensors, mappings, and feedback without providing detailed diagrams, lists of parameters, or reproducible data.
From a communicational point of view, the thesis is well-written and easy to read. Palekas’s prose is expressive and reflective; his philosophical passages are a pleasure to read. At the same time, this lyricism too often supplants analytical clarity. The experimental results remain fuzzy; the measurements are given “by ear,” not through numerical analysis, and the reader cannot tell whether the effects observed are significant or only subjective impressions.
In scope and depth, the thesis is ambitious but uneven. It tries to combine philosophy, biology, and sound art, but the practical documentation remains superficial. The experiments are deficient in calibration and control conditions, as well as in quantitative evidence. The author himself recognizes that fermentation is hardly predictable and thus difficult to reproduce. But this admission only underlines the fragility of his conclusions. Without a presentation of clear data or even replicable protocols, the whole project remains conceptual rather than empirical.
Partial accuracy and attention to detail: the author provides some information about equipment and process – for example, relative calibration among the CO₂ sensors, use of Arduino, Pure Data, but no consistent system is provided for reporting values, frequencies, and time spans. References made to appendices and videos are incomplete, and none of the referred sound recordings and codes are available. The result is that the project cannot be scientifically evaluated or reproduced.
The section on literature review reflects selectivity: In situating his thought within broader ecological and philosophical frameworks, Palekas barely engages the rich corpus of research on bio-sonification, microbial sensing, and feedback sound systems. The lack of these sources increases the effect of isolation: the thesis feels self-contained rather than in conversation with a field.
This gap between theory and documentation is where the quality of the artifact is questioned. The installations and performances he describes conceptually are incompletely and poorly documented. It is not clear if the works were created for this thesis or collated from previous projects. Without recordings, schematics, or step-by-step documentation available, one cannot evaluate any artistic or technical outcomes. Put differently, Microbiophonic Emergences is a strong artistic and philosophical statement, but it is only a partially successful academic thesis. Its conceptual strength comes from the ethical rethinking of listening, the poetic vision of sound as life, and the attempt to dissolve the hierarchy between observer and observed.
The work unfortunately lacks in methodological rigor, detailed evidence, and sufficient contextual grounding. While Palekas seeks to establish a dialogue between humans and microbes, the outcome is just speculative and remains unverified. This invention of bi-directional sonification is not really new; moreover, the thesis overlooks the numerous past projects that have already elaborated on a similar feedback relationship between sound and living systems. Overall, the work is successful as a reflective, imaginative exploration of sound and ecology but fails as a systematically researched academic document. While the work evokes curiosity and wonder, it requires far stronger methodological and contextual grounding to meet the standards of a master’s thesis.
Ist man, wie ich, eher ein visueller Lerner und sucht deshalb vorrangig nach Lerninhalten in Videoform (und hat eine ausgeprägte Youtube-Sucht), so wird man für fast alle Filmthemen wohl keinen besseren Lehrer als Patrick O Sullivan (den Wandering DP) finden, der in der gesamten Szene in etwa den Status eines Halbgottes hat. Einziges Problem dabei ist, dass bei über 500 (meist mehr als einstündigen) Podcastfolgen und circa ebenso vielen Youtube-Videos die Auswahl meist etwas schwerer fällt. Umso lustiger fand ich daher, dass ich heute über ein Video gestolpert bin, in dem dieses Problem einfach gelöst wird. Für “The Easy Way to Not Suck at Lighting” hat Forsyth nämlich kurzerhand bei O Sullivan selbst nachgefragt und ihn mehr oder weniger seine 500 Podcastfolgen ganz schnell für Beginner zusammenfassen lassen. Im Anschluss hat er dann diese Ratschläge in einem echten Setup umgesetzt. Hier also was ich davon lernen konnte.
Essenzielles Setup
Bei der Erklärung was für O Sullivan das essenziellste Setup ist, mit dem er auf einen Dreh fahren würde, hat er die Fragestellung, in der es hieß “ohne ein Vermögen dafür auszugeben”, glaube ich ziemlich ernst genommen, denn auch wenns kein Vermögen ist, ists schon ziemlich viel Kohle´´. Dennoch aber sind einige interessante Gedanken hängen geblieben: Oft heisst es ja, je stärker das Licht desto besser, und mehr Energie sei nie schlecht. O Sullivan jedoch empfiehlt lieber mehr kleine, als wenige große Lichter, um das Bild besser formen zu können. So hat er in seinem essenziellen Setup nur ein einziges klassisches COB Licht als Key, dafür aber haufenweise negative fill und diffundierende Stoffe. Zusätzlich benutzt er noch weitere kleine LED´s, meist mit Fresnel oder drop-in Filtern, um das Licht zu formen und dem Hintergrund Struktur geben zu können.
Herangehensweise
Auch seine Herangehensweise ist sehr interessant, denn er startet nicht klassisch mit dem Key, sondern beginnt eigentlich mit dem Ambient light. Dies hat für ihn mehrere Vorteile, hauptsächlich kann es einem so nicht passieren das Key Light falsch (also aus einer unmotivierten Richtung, aus der es in der Umgebung auf natürliche Weise nie kommen könnte) aufzustellen, oder die Szene überzubelichten. Er holt also als ersten Schritt alle natürlichen Lichtquellen in den Frame und schaltet auch alle Practicals an, dann exposed er für diese und sieht sich an aus welcher Richtung das Key natürlicherweise kommen sollte. Dann stellt er das Key auf. Im nächsten Schritt den negative fill, der seiner Meinung nach wichtiger ist als jedes Licht (Zitat: “ich hätte lieber unendlich negative fill und kein Licht als unendlich Licht und kein negative fill”) und wenn er quasi die Beleuchtung des Subjekts abgeschlossen hat, kommt der Hintergrund dran. Heißt: Er versucht so viele Kontraste zwischen hell und dunkel wie möglich ins Bild zu bekommen, meist dann eben über Lichter mit Filtern oder Linse, die er auf einzelne Merkmale im Hintergrund fokussiert, um diese hervorzuheben. Manchmal aber auch mit so klassischen Mini LEDs wie den Aputure MCs.
Fazit
Seine Ansicht darüber was man eigentlich wirklich braucht, hat mich auch dahingehend, was der Black Friday bei mir ins Haus spülen wird, etwas beeinflusst. Ich finde die Idee mit vielen einzelnen Lichtern echt interessant, und seine Frames sprechen definitiv für sich. Auch im Umgang mit negative fill, für noch stärkere Kontraste, werde ich mich in meinem Filmgenre noch öfter auseinandersetzen, denke ich.
Semantic Sound Validation & Ensuring Acoustic Relevance Through AI-Powered Verification
Building upon the intelligent fallback systems developed in Phase III, this week’s development addressed a more subtle yet critical challenge in audio generation: ensuring that retrieved sounds semantically match their visual counterparts. While the fallback system successfully handled missing sounds, I discovered that even when sounds were technically available, they didn’t always represent the intended objects accurately. This phase introduces a sophisticated description verification layer and flexible filtering system that transforms sound retrieval from a mechanical matching process to a semantically intelligent selection.
The newly implemented description verification system addresses this through OpenAI-powered semantic analysis. Each retrieved sound’s description is now evaluated against the original visual tag to determine if it represents the actual object or just references it contextually. This ensures that when Image Extender layers “car” sounds into a mix, they’re authentic engine recordings rather than musical tributes.
Intelligent Filter Architecture: Balancing Precision and Flexibility
Recognizing that overly restrictive filtering could eliminate viable sounds, we redesigned the filtering system with adaptive “any” options across all parameters. The Bit-Depth filter got removed because it resulted in search errors which is also mentioned in the documentation of the freesound.org api.
Scene-Aware Audio Composition: Atmo Sounds as Acoustic Foundation
A significant architectural improvement involves intelligent base track selection. The system now distinguishes between foreground objects and background atmosphere:
Atmo-First Composition: Background sounds are prioritized as the foundational layer
Stereo Preservation: Atmo/ambience sounds retain their stereo imaging for immersive soundscapes
Object Layering: Foreground sounds are positioned spatially based on visual detection coordinates
This creates mixes where environmental sounds form a coherent base while individual objects occupy their proper spatial positions, resulting in professionally layered audio compositions.
Dual-Mode Object Detection with Scene Understanding
OpenAI GPT-4.1 Vision: Provides comprehensive scene analysis including:
Object identification with spatial positioning
Environmental context extraction
Mood and atmosphere assessment
Structured semantic output for precise sound matching
The fallback system evolved into a sophisticated multi-stage process:
Atmo Sound Prioritization: Scene_and_location tags are searched first as base layer
Object Search: query with user-configured filters
Description Verification: AI-powered semantic validation of each result
Quality Tiering: Progressive relaxation of rating and download thresholds
Pagination Support: Multiple result pages when initial matches fail verification
Controlled Fallback: Limited OpenAI tag regeneration with automatic timeout
This structured approach prevents infinite loops while maximizing the chances of finding appropriate sounds. The system now intelligently gives up after reasonable attempts, preventing computational waste while maintaining output quality.
Toward Contextually Intelligent Audio Generation
This week’s enhancements represent a significant leap from simple sound retrieval to contextually intelligent audio selection. The combination of semantic verification, adaptive filtering and scene-aware composition creates a system that doesn’t just find sounds, it finds the right sounds and arranges them intelligently.
My third Impulse is about our meeting with Daniel Bauer, which turned out to be much more insightful than I expected. From the moment we started talking, it was clear that he had a very good sense of what makes a story emotionally engaging and how certain narrative decisions can shape the way an audience connects to a film. One of the first things he recommended was reaching out to Yue-Shin Lin, especially in relation to our topic of discrimination. He felt that her expertise could add depth to our project and help us approach the subject with more nuance. I immediately understood what he meant, because the topic is sensitive and it requires perspectives from people who are professionally and personally involved in that field.
After that, Daniel talked a lot about what makes characters and stories relatable. He explained that relatability is not just a stylistic choice, but something that is strongly connected to psychological principles. He mentioned empathy, cognitive fluency, social comparison processes, context shifts and narrative transportation. At first, these terms sounded quite academic, but the way he explained them made them very accessible. Empathy, for example, is about whether we emotionally understand or feel with a character. Cognitive fluency basically describes how easy or difficult it is for viewers to process what they see. Social comparison happens automatically, because people tend to compare themselves to characters on screen. Context shifts can open up fresh ways of looking at familiar topics, and narrative transportation is what happens when a story pulls us in so deeply that we forget the world around us.
What I found interesting was how naturally Daniel linked these ideas to filmmaking. He made it clear that these psychological processes are not abstract theories but actually influence how people respond to films. He used the example of the film Adolescence, which he said resonated strongly with him. Hearing him talk about it helped me understand how important emotional honesty and clarity are. A film does not need to be overly complicated or full of dramatic twists to work. It needs to create a feeling that stays with the audience, something they can relate to or recognise in themselves.
For me, one of the biggest takeaways from the meeting was the idea of really knowing the target audience. Daniel said that if you want your film to have an impact, you need to know who you are speaking to and what kind of emotional experience you want to create for them. This means thinking beyond the story itself and considering how every decision supports the atmosphere, the tone and the overall message. It also means being intentional about how the viewer should feel at certain moments and how the film guides them through that emotional journey.
Overall, the meeting reminded me that filmmaking is not only about visuals or structure. It is also about psychology, emotion and understanding how people experience stories. Daniel helped me see that these aspects are not separate from the creative process but a fundamental part of it. I left the conversation with a much clearer idea of what matters in our project and how we can shape the film so that it truly resonates with the people who watch it.
Passend zu einer der großen Fragen, die Daniel Bauer in der Feedback Runde aufgeworfen hat, möchte ich heute mit der Zusammenfassung des ersten Papers starten, um einen profunden Überblick über den state-of-the-art Research zum Thema Leuchttechniken in Horrorfilmen zu bekommen.
Die Grundhypothesen des zugrunde liegenden Papers lauteten zu beweisen, dass auch Lichtkonzepte, die generell für die Darstellung positiver Szenen, Filme oder Charaktere verwendet werden, in Horrorfilmen funktionieren können. Dies wurde an insgesamt vier großen Beispielen festgemacht.
Das Brechen mit klassischen Lichtstrukturen: Ammer gibt an, dass mit klassischen Lichtkonzepten, wie low-key und high contrast, einfallendem Licht aus Fenstern oder schwachen, unsaturierten Farben, die üblicherweise für Horrorfilme benutzt werden, gebrochen werden kann, um die wirklich furchteinflößenden Szenen hervorzuheben. Als Beispiel gibt er an, dass “gute” Vampire, also jene die nur Tierblut trinken um Menschen nicht zu verletzen, in den Twilight-Filmen stets softer geleuchtet sind als ihre blutrünstigen Kollegen, um denen nicht den Spuk zu nehmen.
Intensität des Keys und Key-to-Fill-Ratio: Auch hier argumentiert Ammer, dass ein höherer Kontrast im Gesicht, wie er eigentlich genutzt wird um Charaktere, düsterer zu machen, nicht immer der richtige Weg ist. Er argumentiert, dass in Shining etwa, in der Szene als Jack Nicholson sich endgültig dem Bösen zuwendet, er durchgehend mit einem Frontlight beleuchtet ist. Also einer Methode, bei der das gesamte Gesicht gleichmäßig ausgeleuchtet ist und die eigentlich allerhöchstens in Beauty-Kampagnen vorkommt, nicht aber im Kino und schon gar nicht im Horror. Dies soll es laut Ammer möglich gemacht haben jegliche Mimik von Nicholson während seiner Verwandlung nachzuvollziehen.
High-Key-Lighting: Außerdem streicht er heraus, dass Schlüsselszenen in Horrorfilmen manchmal ganz bewusst nicht dunkel und kontrastreich, sondern hell und kontrastarm dargestellt sind, obwohl man diese Gestaltung eher in Feelgood-Filmen erwarten würde. Als Beispiele nennt er die Duschszene in Psycho und das Folterlabor in Saw. Damit möchte der DP laut Ammer erreichen, dass man auch wirklich alles vom schrecklichen Horror sieht und nichts in der Dunkelheit verschwindet.
Die Wirkung von Farben: Zu guter Letzte streicht Ammer heraus, dass verschiedene Farben in verschiedenen Situation auch andere Bedeutungen haben können, was mich sehr an den Kuleschow-Effekt erinnert hat. Orange etwa, ist eigentlich die Farbe eines warmen Sonnenuntergangs, wirkt in Zusammenhang mit einer Leiche aber giftig.
Fazit
Das Paper war spannend und hat definitiv den Punkt unterstrichen, den auch Daniel Bauer aufgebracht hat. Aus diesem Grund werde ich die Bibliographie auch stärker an das Horrorthema anpassen und für die folgenden Blogposts versuchen, klassischere Lichttheorien in Horrorfilmen mitsamt ihren jeweiligen Wirkungen herauszuarbeiten.
vgl. Ammer, Sawsan Mohammed Ezzat Ibrahim: Content Analysis of Lighting and Color in the Embodiment of Fear Concept in Horror Movies: A Semiotic Approach. In: Information Sciences Letters 2020, Volume 9, Issue 2, http://dx.doi.org/10.18576/isl/090210.
Die heutige Session mit Daniel Bauer war extrem ergebnisreich, weshalb ich mich dazu entschlossen habe, mir gleich alle Ideen und Inputs von der Seele zu schreiben. Auch, weil zwar viele Fragen beantwortet wurden, aber dafür noch mehr neu entstanden sind, die ich dann noch mit dir Roman (ja du wirst auch hier wieder der einzige sein der das liest) besprechen muss.
Input 1: DIE Lichttechnik für Horrorfilme werde ich auch in 500 Standardwerken nicht finden, da Filme hauptsächlich von zwei Dingen geprägt werden: Einerseits der Zeit in der sie gedreht werden und andererseits dem DP der sie shootet. Genau daraus könnte man aber dafür eine Forschungsfrage ableiten. Etwa wie sich die Lichtsetzung in Horrorfilmen über die Zeit verändert hat, angefangen bei Nosferatu in den 20ern über erste richtige Splasher-Filme bis hin zu neuen Horrorfilmen der 2010er und 2020er Jahre. Auch könnte man einzelne DP´s, die sich sehr im Horrorgenre vertieft haben herauspicken und analysieren.
Input 2: Nicht zu viele Standardwerke nehmen. In meiner aktuellen Bibliographie finden sich einige Standardwerke zum Thema Lichtsetzung. Daniel meint die werden mich alle nicht schlauer machen, und nicht weiter an das heranbringen was mich interessiert. Viel besser wäre es vielleicht ein einziges Standardwerk zu haben und in der weiteren Literatur dann viel stärker einzugrenzen und die Auswahl wirklich auf Quellen zu beschränken in denen es strikt um Leuchttechniken für Horrorfilme geht, nicht für Film generell.
Input 3: Wie sehr muss die Entstehung des Kurzfilms Teil der Masterarbeit sein? Muss jeder Schritt, von der Ideenfindung, des Script writing, shotlisten, location scouten, storyboarden etc. vollumfänglich im Theorieteil der Masterarbeit dokumentiert werden, und mit Quellen belegt werden? A la für das script wurde das Buch “Save the Cat” verwendet mit diesen und jenen Frameworks und dann die Storybeats auflisten usw, und das für jeden Schritt? Falls ja, und da hat Daniel Recht, übernehm ich mich mit der Arbeit um circa 270%.
Grundsätzlich hat Daniel schon angezweifelt ob ich überhaupt mit dem Theorieteil dann einen wirklich zusammenhängenden Kurzfilm produzieren muss, oder ob es etwa nicht reicht die 4-5 Schlüsselszenen herauszunehmen und sich mit diesen dann wirklich tagelang beschäftigen und diese komplett perfekt zu leuchten. Sodass, das Werkstück am Ende dann aus mehreren “perfekten” Stills, oder Shots besteht. (Als Inspiration dazu: Gregory Crewdson.) Das würde den Workload natürlich extrem verkleinern und machbarerer gestalten. Womit ich ihm grundsätzlich vollkommen zustimme, wohlwissend, dass ich halt einfach unfassbar gern den gesamten Kurzfilm drehen würde.
Daher nun die Gretchenfrage: Reicht es sich im Theorieteil ausschließlich mit dem eigenen Thema, in meinem Fall eben Lichttheorien in Horrorfilmen auseinanderzusetzen, dann einen Horrorfilm nach dieser Theorie zu drehen und am Ende einfach Stills aus dem Film in den schriftlichen Teil aufzunehmen und zu erklären warum man in dieser oder jener Situation so geleuchtet hat. Oder muss der gesamte Entstehungsprozess des Films auch dokumentiert und wissenschaftlich belegt werden? Denn sonst halte ich mich wahrscheinlich einfach zu lange mit anderen Dingen auf, die aber eigentlich gar nicht mein Hauptthema, nämlich Licht, sind.
Input 4: Jakob Slavicek wäre ein Adresse, die ich mir so oder so unbedingt genauer ansehen sollte. Daniel kennt ihn als Oberbeleuchter und weiß, dass er immer wieder Praktikanten auf Drehs mitnimmt. Vielleicht könnte ich mit einer netten Mail versuchen, einfach mal bei einem Spielfilm Dreh, bei dem er als Gaffer arbeitet, als Volo mitkommen, und mir Dinge abschauen. Außerdem betreibt er einen Verleih, der spätestens für meinen echten Dreh dann interessant wird, wenn die 600er Aputure von der FH an ihre Grenzen kommen.
Um gleich nahtlos an den ersten Impuls anzuschließen, möchte ich mit einem ganz neuen Video von Mark Bone fortfahren, das erst vor wenigen Stunden veröffentlicht wurde und gleich meine Aufmerksamkeit erlangte.
Anders als Luc Ung ist Mark Bone mehr der klassische Film-Content-Creator auf Youtube, der aber mit seinem Online-Kurs “Art of Documentary” doch recht große Berühmtheit erlangt hat. Durch den hohen Preis habe ich mich aber leider nie drüber getraut mir diesen auch wirklich zu kaufen. Dennoch verfolge ich Bone gerne, da er im Gegensatz zu anderen auch wirklich selbst noch als Filmemacher an großen Projekten arbeitet. Die Doku über CBum zum Beispiel, die er in vielen seiner letzten Videos als B-Roll immer wieder anteasert, sieht nämlich brutal aus und ist, soweit ich weiß, eine Produktion für Prime Video, also der Mann weiß schon was er tut. Gerade deshalb hat mich interessiert ob sich sein “System” inhaltlich wirklich groß von dem unterscheidet was ich mir in Impuls 1 angeschaut habe. Deshalb werde ich dieses kurz zusammenfassen und erklären und danach einordnen.
Mark Bone´s System
1. Track the Sun: Als ersten Schritt, wenn man in einen Raum bekommt, empfiehlt Bone die Sonne abzuchecken und mit Apps wie dem klassischen Kompass oder Sunseeker etc. die Ausrichtung der vorhandenen Fenster herauszufinden. Dies entscheidet wie man dann mit den Fenstern umgeht. Ob man sie also als Key oder Kicker verwenden kann, oder vielleicht ganz ausblockt und nur künstlich belichtet, weil sich die Sonne während der Zeit des Interviews zu viel bewegen würde. Als Merksatz: Fenster Richtung Süden geben hartes Licht, Fenster nach Norden weiches Licht.
Control the variables: Als zweites empfiehlt Bone die ganze Szene einmal zu “deaktivieren”, alle Rollos runter, alle Lichter aus. Und dann Stück für Stück mit Absicht das wieder zu aktivieren, was für die Szene Sinn macht.
Define the Motivation: Finde heraus wo in deiner Szene auf natürliche Art und Weise das meiste Licht kommen würde. Im Normalfall wäre das ein Fenster oder die stärkste Lampe im Raum. Diese Quelle bestimmt die Seite von deinem Fill, die du dann mit einer Softbox etc. verstärken kannst. Bone empfiehlt die Originalquelle als Practical oder als Anschnitt im Frame zu lassen, um dem Zuschauer zu erklären wo das Licht herkommt.
Choose Quality of Light: Entscheide ob du hartes oder softes Licht haben willst. Bone empfiehlt dabei immer die Quality der Motivation zu imitieren, um den natürlichsten Look zu erhalten. Ist die Motivation im Frame eine Tischlampe, wird das Key z.B. eher hart.
Place your subject: Mit der Motivation und dem Key fix aufgestellt, empfiehlt Bone jetzt den Shot quasi zu locken und das Subjekt final zu platzieren. Dafür empfiehlt er, dass die Person den dreifachen Abstand zu nächsten Wand im Hintergrund hat, im Vergleich zum Abstand zwischen Person und Kamera, um genug Tiefe zu kreieren.
Choose the Lens: Wenn das Subjekt sitzt stellt Bone die Kamera final auf und wählt die Linse. Dafür nimmt er fast immer eine 35er, um genug Hintergrund ins Bild zu bekommen und noch Raum für eine engere zweite Einstellung zu lassen.
Shape the contrast: Jetzt bestimmt Bone das lighting ratio des Subjekts. Grundsätzlich empfiehlt er nur dann ein Fill light zu verwenden wenn es wirklich nötig ist und lässt dieses oft ganz weg oder benutzt natürlich negative fill. Für ein nettes Gespräch empfiehlt er 2:1, für ernste Themen 4:1.
Build the background: Jetz wo Key, Kamera und Subjekt stehen, baut er noch den Hintergrund für maximale dreidimensionale Wirkung. Dafür fügt er nach und nach noch practicals im Hintergrund hinzu (gerne in anderen Temperaturen als das key) oder beleuchtet diesen von außerhalb ohne aber das Subjekt zu überstrahlen. Alternativ kann der Separation auch klassisch mit einem Kicker light erfolgen, er ist aber nicht wirklich Fan davon, weil es dann laut ihm zu sehr nach einem Studio aussieht und nicht mehr als wäre man wirklich bei der Person zu Hause.
Expose and Balance Color: Jetzt stellt Bone erst die Belichtung und den Weißabgleich in der Kamera ein. Dabei gleicht er nicht automatisch key und Kamera Farbtemperatur miteinander an, sondern wählt die Temperatur in der Kamera je nach Look: Kühler für seriöse Interviews (corporate style), wärmer für emotionale Interviews.
Stresstest: Zu allerletzt, lässt er das Subjekt sprechen und sich bewegen. Bewegt es sich aus dem Licht? Sind Handgesten nicht im Frame etc? Er macht das Setup bulletproof, um nicht erst danach etwaige Fehler zu bemerken und nimmt ein Testvideo auf.
Fazit
Ich fand Bone´s Herangehensweise extrem interessant, da ich selbst schon sehr oft klassische Interviews oder Talking Head Szenen gefilmt habe und auch mein nächster Auftrag genau daraus bestehen wird. Neu und aufschlussreich war dabei für mich wie er mit der Sonne arbeitet, wie er lighting motivation findet, um den Frame natürlich wirken zu lassen, und wie er entscheidet wie weit sich das Subjekt von der Wand entfernt. Das sind finde ich sind sehr einfache und leicht umzusetzende Guidelines.
Im Verglech zu Luc Ung ist die Abfolge der essenziellen Schritte des Beleuchtens eigentlich sehr gleich: Zuerst findet er die Motivation und passt dann Richtung, Härte und Farbe dementsprechend an. Dann bestimmt er die Stärke des Lichts bei der Wahl des Kontrastverhältnisses und wenn man so will ist das was Luc Ung als letztes macht, nämlich das Licht noch zu formen um ungewollte light spills zu verhindern, auch das worauf Bone im Stresstest am Schluss noch einmal achtet.
Ich finde beide Systeme daher unglaublich hilfreich, Bone´s für klassische Interview Szenarien und Ung´s im klassischen narrativen Filmmaking.
Intelligent Sound Fallback Systems – Enhancing Audio Generation with AI-Powered Semantic Recovery
After refining Image Extender’s sound layering and spectral processing engine, this week’s development shifted focus to one of the system’s most practical yet creatively crucial challenges: ensuring that the generation process never fails silently. In previous iterations, when a detected visual object had no directly corresponding sound file in the Freesound database, the result was often an incomplete or muted soundscape. The goal of this phase was to build an intelligent fallback architecture—one capable of preserving meaning and continuity even in the absence of perfect data.
Closing the Gap Between Visual Recognition and Audio Availability
During testing, it became clear that visual recognition is often more detailed and specific than what current sound libraries can support. Object detection models might identify entities like “Golden Retriever,” “Ceramic Cup,” or “Lighthouse,” but audio datasets tend to contain more general or differently labeled entries. This mismatch created a semantic gap between what the system understands and what it can express acoustically.
The newly introduced fallback framework bridges this gap, allowing Image Extender to adapt gracefully. Instead of stopping when a sound is missing, the system now follows a set of intelligent recovery paths that preserve the intent and tone of the visual analysis while maintaining creative consistency. The result is a more resilient, contextually aware sonic generation process—one that doesn’t just survive missing data, but thrives within it.
Dual Strategy: Structured Hierarchies and AI-Powered Adaptation
Two complementary fallback strategies were introduced this week: one grounded in structured logic, and another driven by semantic intelligence.
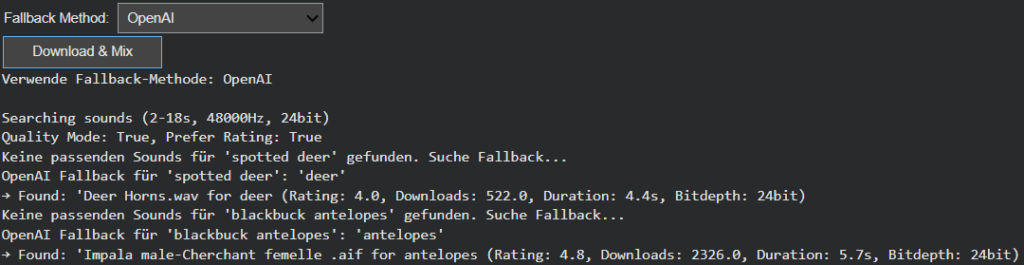
The CSV-based fallback system builds on the ontology work from the previous phase. Using the tag_hierarchy.csv file, each sound tag is part of a parent–child chain, creating predictable fallback paths. For example, if “tiger” fails, the system ascends to “jungle,” and then “nature.” This rule-based approach guarantees reliability and zero additional computational cost, making it ideal for large-scale batch operations or offline workflows.
In contrast, the AI-powered semantic fallback uses GPT-based reasoning to dynamically generate alternative tags. When the CSV offers no viable route, the model proposes conceptually similar or thematically related categories. A specific bird species might lead to the broader concept of “bird sounds,” or an abstract object like “smartphone” could redirect to “digital notification” or “button click.” This layer of intelligence brings flexibility to unfamiliar or novel recognition results, extending the system’s creative reach beyond its predefined hierarchies.
User-Controlled Adaptation
Recognizing that different projects require different balances between cost, control, and creativity, the fallback mode is now user-configurable. Through a simple dropdown menu, users can switch between CSV Mode and AI Mode.
CSV Mode favors consistency, predictability, and cost-efficiency—perfect for common, well-defined categories.
AI Mode prioritizes adaptability and creative expansion, ideal for complex visual inputs or unique scenes.
This configurability not only empowers users but also represents a deeper design philosophy: that AI systems should be tools for choice, not fixed solutions.
Toward Adaptive and Resilient Multimodal Systems
This week’s progress marks a pivotal evolution from static, database-bound sound generation to a hybrid model that merges structured logic with adaptive intelligence. The dual fallback system doesn’t just fill gaps, it embodies the philosophy of resilient multimodal AI, where structure and adaptability coexist in balance.
The CSV hierarchy ensures reliability, grounding the system in defined categories, while the AI layer provides flexibility and creativity, ensuring the output remains expressive even when the data isn’t. Together, they form a powerful, future-proof foundation for Image Extender’s ongoing mission: transforming visual perception into sound not as a mechanical translation, but as a living, interpretive process.
Mein erster Impuls für die diessemestrige Blogserie ist ein Youtube-Video, das mich gleichzeitig auch überhaupt erst auf die Idee für meine Masterarbeit gebracht hat und das ich einfach unfassbar hilfreich gefunden habe.
Grundsätzlich habe ich das Thema Licht bisher in diesem Master extrem stiefmütterlich behandelt. Natürlich kann man als kompletter Quereinsteiger nicht alles können, weshalb ich mich anfangs extrem in die camera operation vertieft habe und versucht habe meinen Kopf in das unendlich tiefe Rabbit Hole verschiedener Kamerasensoren, Belichtungsmethoden, Rigs, Cameramovements, Gear etc. zu stecken. Für das, was ich jetzt als Event/Sportvideograph so mache, ist das natürlich auch die Basis, immerhin kann ich schwer eine 1200er Aputure mit auf den Fußballplatz oder auf den Altar bei einer Hochzeit nehmen. Dabei ist mir aber (und so rede ich erst seit ich exakt dieses Youtube-Video gesehen habe und das nächste Rabbit-Hole aufgegangen ist) unfassbar viel entgangen. Denn spannend wird filmmaking erst wenn du nicht gezwungen bist mit dem zu arbeiten was da ist, sondern wenn du dein Bild meisseln kannst wie ein Bildhauer seine Skulptur. Und da kommt Licht ins Spiel.
Da es einfach so ein unfassbar großes Thema ist habe ich mich aber lang nicht getraut einfach mittendrin anzufangen ohne genau zu wissen, ob ich jetzt grad irgendwo in den Basics stecke oder mir grade extrem fortgeschrittene Techniken anschaue. Lange habe ich mir daher erhofft im Curriculum noch ein paar Basiskurse zu finden, außer einen einzigen eintägigen Workshop kam da aber leider genau gar nichts daher, weshalb ich noch viel froher darüber bin, dass mir der Youtube-Algorithmus genau dieses Video auf meine For-You gespielt hat und mich in nur 27 Minuten – Achtung – erleuchtet hat. Aber jetzt medias in res.
Who the fuck is Luc Ung
Luc Ung ist ein (mir bis dato unbekannter) DP aus LA, dessen Werke schon auf diversen Fim Festivals dieser Welt gescreened wurden und meiner Meinung nach unfassbar aussehen. Einen Eindruck davon könnt ihr euch auf seiner Homepage (https://www.lucung.com/) verschaffen. Statt wie bei anderen klassischen Youtube Erklärbären, die alle 3 Tage ein Video mit dem neuen besten Trick allerzeiten veröffentlichen, der dann eigentlich gar nicht so neu und auch gar nicht so gut ist, hat Luc Ung nur ein einziges Video auf seinem Kanal, nämlich dieses. Und das auch nur, weil er so oft darum gebeten worden sei, sein Wissen für immer festzuhalten, meint er zumindest. Fand ich anfangs ganz witzig, konnte ich 27 Minuten später aber ziemlich gut nachvollziehen.
Im kommenden fasse ich, das grundlegende Konzept mit dem er an Licht herangeht kurz zusammen. Ich glaube nicht, dass sich genau diese Vorgehensweise, genau diese Begriffe oder ähnliches auch in anderen (gedruckten) Standardwerken wiederfinden lassen – ob das so ist wird sich spätestens mit Ende dieses Blogs im Jänner herausstellen, wenn ich diese auch gelesen habe. Trotzdem hat mir sein System den Einstieg in die Welt des Lichts unfassbar vereinfacht und deshalb teile ich sie auch mit euch. (Wohlwissend, dass niemand außer du Roman diese Worte jemals lesen wird. Liebe Grüße an der Stelle an dich!)
Ung´s System
Grundsätzlich beschreibt Ung Licht mit insgesamt fünf verschiedenen Charakteristiken: Richtung, Härte, Farbe, Stärke und Form. Dabei sind aber nicht nur die fünf Charakteristiken an sich wichtig, sondern auch ihre Reihenfolge, da er beim Beleuchten einer Szene in genau dieser Reihenfolge vorgeht und sein Licht dementsprechend anpasst. Grundsätzlich versucht Ung in jeder Einstellung soviele Kontraste zwischen Hell und Dunkel zu erzeugen wie möglich (chiaroscuro). Nicht nur im Gesicht, sondern im gesamten Frame. Je öfter ein Bild, wenn man es von links nach rechts liest, zwischen hell und dunkel wechselt, desto interessanter wirke der Shot auch, da er mehr Dimension bekommt. Immerhin muss man eine dreidimensionale Welt auf einer zweidimensionalen Leinwand abbilden.
1. Richtung
Frontlight: Beim Frontlicht, stehen Licht und Kamera in einer Achse zur Szene. Dies hat zwei entscheidende Nachteile. Einerseits geht natürlich der gesamte Kontrast im Gesicht verloren, da es komplett ausgeleuchtet ist, andererseits ist aber natürlich auch fast unmöglich nicht gleichzeitig auch den Hintergrund mit auszuleuchten. Dadurch geht noch eine weitere Kontrastebene verloren.
Butterfly light: Das Butterfly light ist quasi eine Erweiterung des Frontlight. Möchte man sein Subjekt unbedingt aus derselben Richtung leuchten wie die Kamera, so macht es Sinn, dies aus großer Höhe und mit starkem Winkel zu machen. Dies umgeht die Nachteile des Frontlights. Statt einem komplett ausgeleuchteten Gesicht werfen Elemente wie Wangen und die Nase Schatten nach unten (wie ein Schmetterling) und erzeugen so Kontrast. Außerdem umgeht man so auch den Hintergrund komplett mit auszuleuchten. Das Butterfly light sieht nicht zwingend schön aus und kann sogar stören, wenn etwa ein markantes Gesicht extrem starke Schatten wirft. Daher könnte es in meiner Arbeit für böse Charaktere interessant sein.
Rembrandt light: Der Klassiker aller Klassiker. Dabei wird die Lichtquelle ca 45 Grad entfernt Eyeline und aus ca 45 Grad Höhe aufgestellt und leuchtet eine Gesichtshälfte aus. Der Nasenschatten erzeugt dabei unter dem Auge der anderen Seite ein helles Dreieck (Rembrandt Dreieck). Diese Richtung ist die am öftesten genutzte und erzeugt angenehme, dreidimensionale Ergebnisse.
Side Light: Beim Side light, wandert das Licht weitere 45 Grad von der Eyeline des Subjekts weg und steht damit im rechten Winkel (oder ca 80 Grad). So wird eine Gesichtshälfte gar nicht belichtet und die andere voll.
Kicker (Edge Light): Dabei wandert das Licht hinter das Subjekt und strahlt dieses aus ca 15-45 Grad hinter dem rechten Winkel des Sidelights an. Beleuchtet werden dabei die Kopfkonturen und die Schulter. Während es auch für sich alleine stehen kann wird es meistens natürlich gepaart. Der Kicker ist die beste Variante um eine weitere Abwechslung zwischen Hell und Dunkel zu ermöglichen und das Subjekt dreidimensionaler wirken zu lassen.
Backlight: Genau das Gegenteil des Frontlights, bei dem das Licht also direkt hinter der Eyeline des Subjekts steht. Der Unterschied zum Kicker ist, dass der Kicker auch das Kinn trifft, während das Backlight wirklich nur die Konturen des Kopfes und der Schulter trifft. Anwendungsgebiete sind gleich. Tipp: Muss von oben kommen, um lens flares zu vermeiden.
Zusatz: Ung sieht beim Wählen der Lichtrichtung die Wirkung wichtiger als die Realität, gerade wenn practicals im Shot sind. Er beweist dies mit einer Szene aus Herr der Ringe in der zwei Charaktere im Freien miteinander reden und in ihren einzelnen Close-Ups haben beide die Sonne als Backlight, was physikalisch wohl nur auf Mittelerde möglich ist, in der Bildwirkung aber Sinn macht, da beide gleich fühlen.
2. Härte
Lichthärte beschreibt wie diffus oder direkt Licht auf das Subjekt trifft. Das entscheidet ob die entstehenden Schatten harte Kanten haben, oder weiche Verläufe.
Die Härte des Lichts entsteht dabei im relativen Verhältnis zwischen der Größe des Lichts und der Größe des Subjekts. Je größer die Lichtquelle, desto weicher das Licht. Auch eine große Lichtquelle kann aber hartes Licht produzieren, wenn sie weit genug entfernt ist, da sie in Relation dann wieder klein erscheint. Die besten Beispiele hierfür sind eine Soft Box und die Sonne. Die Soft Box vergrößert die Lichtquelle von einem kleinen Punkt auf eine metergroße Box und macht so hartes Licht weich. Die Sonne hingegen, obwohl sie die wohl größte Lichtquelle ist, die man finden kann, produziert hartes Licht, weil sie durch die große Entfernung so klein erscheint. Will ich am Set softeres Licht, muss ich also die Lichtquelle vergößern (SoftBox, Diffusion sheet etc) und/oder das Licht näher ans Subjekt bringen und vice versa.
Farbe
In Sachen Farbe geht Ung nur auf die klassische Farbtemperatur ein, also die Calvin Range von 2500-7000K. Grundsätzlich empfiehlt Ung die Farbtemperatur der Kamera und jenes des wichtigsten Lichts (also meistens des Key Lights, aber vielleicht auch der Sonne etc.) miteinander abzustimmen. Um Gefühle zu transportieren (etwas eine kalte Winternacht, oder den Sommer deines Lebens) kann es aber natürlich von Vorteil sein die Kamera absichtlich wärmer und kälter einzustellen als das Key. Essenziell dafür ist aber natürlich zu wissen wieviel Kelvin die Lichtquelle hat. Was ich aus Ung´s Erklärung nicht ganz herausfinden konnte, war ob es egal ist welchen der beiden Parameter ich verändere, also ob es das gleiche Bild erzeugt, wenn ich die Kamera absichtlich kälter oder das Licht absichtlich wärmer einstelle.
Intensität
Da Richtung, Härte und Farbe direkt auch bestimmen wieviel Licht nun auf das Subjekt trifft, macht es laut Ung überhaupt keinen Sinn die Intensität vor diesen anzupassen. Heißt: Zuerst zufrieden mit Richtung, Härte und Farbe sein und dann um die Intensität kümmern.
Die für die Intensität des Lichts zentrale Metrik sind laut Ung die Verhältnisse, also lighting ratios. Einerseits das Verhältnis innerhalb des Gesichts (key to fill) und das Verhältnis zwischen Vor- und Hintergrund (also in den meisten Fällen zwischen Subjekt und Hintergrund).
Das ratio an sich kann man dabei über zwei Arten angeben, entweder in stops oder als klassisches Verhältnis. Ein 2:1 Verhältnis, bei dem der helle Teil doppelt so hell ist wie der dunkle, wäre dabei ein 1 stop ratio, 4:1 sind 2 stops usw.
Um sich sinnvoll Gedanken über das Verhältnis machen zu können empfiehlt Ung gerade bei key to fill, zuerst das key light so einzustellen, dass die Exposure technisch in der Kamera passt und dann nicht mehr anzugreifen. Stattdessen wird dann nur mehr über die Intensität des Fills, das Verhältnis bestimmt, wobei “Fill” hierbei natürlich auch negative Fill sein kann, sollte die Umgebung bereits so hell sein, dass durch das Key alleine schon ein zu schwaches Verhältnis entsteht.
Beim Verhältnis zwischen Subjekt und Hintergrund empfiehlt Ung standardmäßig 1 bis 1,5 stops Unterschied, da der Charakter sich so am natürlichsten und schönsten vom Hintergrund abhebt. Mehr oder weniger ist als kreative choice natürlich trotzdem möglich. Am besten sind die Lichter, die den Vordergrund, und jene die den Hintergrund, beleuchten daher individuell ansteuerbar, um das Verhältnis zu kontrollieren.
Außerdem ist es natürlich wichtig das blocking bereits vorher zu wissen um zu vermeiden, dass sich der Charakter in einem Shot zu einem zu hellen oder zu dunklen Hintergrund bewegt. Hilfreich ist es auch grundsätzlich nichts und niemanden nah an einer Wand zu platzieren, da es sonst kaum möglich ist, den Vordergrund alleine auszuleuchten, ohne den Hintergrund mitzunehmen.
Form
Als allerletzten Schritt empfiehlt Ung das Licht zu formen, und etwa ungewollte “light spills” zu verhindern. Dies geschieht hauptsächlich durch flags, also Stoffe die Licht blockieren, oder andere Systeme mit ähnlichem Sinn, wie barn doors etc. Beim Umgang mit flags rät Ung, mit der flag so nah wie möglich an das Subjekt ranzugehen, um so viel ausbrechendes Licht wie möglich einzufangen.
Fazit
Ich habe noch nie ein Framework gesehen, das so logisch, so unmissverständlich und so klar ist wie dieses. Erst dieses Video hat mir klar gemacht wieviel eigentlich möglich ist, wenn man leuchten kann. Wieviel davon common sense ist und welche, für eine Masterarbeit relevanteren, anderen Quellen es dafür gibt, wird in den kommenden Blogs erörtert.
Achja, und den Link zum Video bin ich euch (also eigentlich wieder nur dir Roman) auch noch schuldig: