Today, I dove into the quirky and ambitious world of Dinosaur Choir, a NIME 2023 paper by Brown, Dudgeon, and Gajewski. Yes – you read that right. It’s about playing music with dinosaur skulls. Well, replicas, but still! The idea? Reconstruct hadrosaur skulls (those duck-billed dinosaurs with dramatic nasal crests) to recreate their vocalizations through breath-powered instruments. It’s part speculative science, part interactive sound art, and part paleo-fan dream.
First impressions? It’s wild – in a good way. The concept of turning ancient anatomy into playable sound interfaces is not just fascinating but also incredibly poetic. You’re literally breathing life into extinct creatures. The goal isn’t only musical performance – it’s also science communication and education. As someone interested in design for mental well-being, I’m always drawn to tactile, embodied experiences. This feels like an emotional connection to the distant past, which is unexpectedly calming and awe-inducing.
Some things I really appreciated:
The use of CT scan data and iterative digital modelling (with tools like Blender and 3D Slicer) shows a commitment to scientific integrity.
They address accessibility and hygiene, especially post-COVID, by swapping out direct breath tubes for breath-activated microphones – smart move!
The project is also intentionally speculative, acknowledging that no one can truly know how a hadrosaur sounded, but instead allowing users to explore different hypotheses through interactive sound.
But here’s where my inner critic perks up. While the project is undeniably cool, it feels like it’s trying to be everything at once: a scientific model, an artistic instrument, a museum exhibit, and an educational tool. That multiplicity is exciting, but also a bit scattered. I wonder if it might benefit from more intentional “mode-switching” -like, a toggle between “science mode” (where only plausible vocalizations are allowed) and “experimental mode” (go wild with dino-DJing). Right now, the boundaries seem a bit blurry.
Also, one half of my brain (the one I made up for this blog post 😄) was thinking about how this might connect with more emotional, inner experiences. What if, instead of performing music, someone used this as a way to reflect on loss? Extinction isn’t just scientific – it’s emotional. Could the dinosaur choir be part of a meditative installation about disappearance, transformation, and the long arc of time?
All in all, I love it. It’s weird, fun, surprisingly moving, and technically impressive. The Dinosaur Choir might not be the most conventional music interface, but it’s got soul. Or at least… breath.
Tests on automated audio file search via freesound.org api:
For further use in the automated audio file search of the recognized objects I tested the freesound.org api and programmed the first interface for testing purposes. The first thing I had to do was request an API-Key by freesound.org. After that I noticed an interesting point to think about using it in my project: it is open for 5000 requests per year, but I will research on possibilities for using it more. For the testing 5000 is more than enough.
The current code already searches with a few testing tags and gives possibilities to filter the searches by samplerate, duration, licence and file type. There might be added more filter possibilities next like rating, bit depth, and maybe the possibility of random file selection so it won’t be always the same for each tag.
Next steps would also include to either download the file or just play it automatically. Then there will be tests on using the tags of the AI image recognition code for this automated search. And later in the process I have to figure out the playback of multiple files, volume staging and filtering or EQing methods for masking effects etc…
Test gui for automated sound searching via freesounds.org API
This is a review on dB: A Web-based Drummer Bot for Finger-Tapping, a project done by Çağrı Erdem, and Carsten Griwodz. You can find more info about the project here and also, a link to the paper can be found here.
This paper introduces dB, a really cool web-based tool that lets you create drum grooves just by tapping on your computer keyboard. Think of it as a drummer bot powered by artificial intelligence that takes your simple finger taps and turns them into more complex rhythms. The idea is to make music creation more accessible to everyone, even if you don’t have a musical background.
What I find particularly interesting about dB is its focus on how our bodies are involved in music. The researchers recognize that music isn’t just in our heads; it’s something we feel and move to. By using finger-tapping as the main way to interact with the AI, they’re exploring this connection in a simple way. The paper also highlights the importance of “groove,” that irresistible urge to move with the music, and how dB tries to tap into that.
Another great aspect of this project is the effort put into understanding how people actually use and feel about the system. The researchers conducted a user study to see if people felt bored, happy, in control, or tired while using dB. They found that when the AI introduced more randomness and variation into the drum patterns, users tended to be more engaged and less bored. This suggests that a bit of surprise can make the music-making experience more fun. Plus, the fact that they’ve made the code and the music data they used publicly available is a big win for open research.
However, like any project, there are some areas that could be looked at more closely. One thing that stands out is the reliance on just finger-tapping on a computer keyboard. While this makes it very accessible, one participant in the study mentioned the lack of “high-resolution” in the interaction. You can imagine that tapping a spacebar might not give you the same nuanced control as playing actual drums or even a more specialized musical interface. The paper itself acknowledges this “bottleneck” and its potential impact on the feeling of control.
Also, the AI model was trained on a specific type of music: eight-note beats common in rock and heavy metal, in a 4/4 time signature. While this was a deliberate choice for the study, it might mean that dB is better at generating certain kinds of grooves than others. It would be interesting to see how it performs with different musical styles and time signatures.
The paper also mentions that there aren’t great ways to really measure how “good” the AI-generated music is in a way that humans perceive it. They used mathematical calculations to train the model, but understanding how these calculations relate to what sounds good to our ears is still a challenge in AI music research.
Finally, the study found that many users didn’t feel particularly “skillful” while using dB. This might point to a need to find a better balance between the AI’s surprises and the user’s sense of ownership and control over the musical output.
Overall, the dB project is a fascinating exploration into making music creation more accessible through AI and simple bodily interactions. The user study provides valuable insights into what makes these kinds of interfaces engaging. While there are limitations, particularly in the interaction method and the scope of musical styles, dB lays a solid foundation for future research in human-AI musical collaboration. It makes you think about how even simple actions can be transformed into something musically interesting with the help of intelligent systems.
Sound Meets the City: Nadine Schütz’s Promenade Sonore Transforms a Footbridge into a Living Instrument
We first encountered Nadine Schütz’s fascinating work during her presentation at the IRCAM Forum Workshops 2025, where she introduced her project Promenade Sonore: Vent, Soleil, Pluie (“Wind, Sun, Rain”). The talk offered deep insights into her creative process and the technical and ecological thinking behind the installation.
In the heart of Saint-Denis, just north of Paris, Swiss sound artist Nadine Schütz has reimagined the way we move through and experience urban space. Her project Promenade Sonore: Vent, Soleil, Pluie (“Wind, Sun, Rain”) is not just a public art installation—it’s a multi-sensory experience that turns an ordinary walk across a footbridge into an acoustic encounter with the environment.
Commissioned by Plaine Commune and developed in close collaboration with architect-engineer Marc Mimram, the installation is located on the Pleyel footbridge, a key link between the neighborhoods of Pleyel and La Plaine. Rather than adding passive sound or music, Schütz has embedded three sculptural sound instruments directly into the architecture of the bridge, each one activated by a different natural element: wind, sun, and rain.
These instruments aren’t just symbolic; they actually respond to the environment in real time. Wind passes through a metal structure that produces soft, organ-like tones. When sunlight hits specific points, it activates solar-powered chimes or sound emitters. During rainfall, the structure becomes percussive, resonating with the rhythm of droplets. The bridge becomes a living, breathing instrument that reacts to weather conditions, turning nature into both performer and composer.
What makes Promenade Sonore truly compelling is how seamlessly it blends technology, ecology, and design. It’s not loud or intrusive—it doesn’t drown out the urban soundscape. Instead, it subtly enhances the auditory experience of the city, encouraging passersby to slow down and listen. It transforms a utilitarian space into a space of poetic reflection.
Schütz’s work is rooted in the idea that sound can deepen our connection to place. In this project, she brings attention to the sonic qualities of weather and architecture—things we often overlook in our fast-paced, screen-driven lives. The soundscape is never the same twice: it shifts with the wind, the angle of the sun, or the mood of the rain. Every walk across the bridge is a unique composition.
More than just an artistic gesture, Promenade Sonore is part of a broader vision of “land-sound” design—a practice Schütz has pioneered that treats sound as an essential component of landscape and urban planning. In doing so, she challenges traditional boundaries between art, science, and infrastructure.
Visit of the pleyel bridge
We had the chance to visit the Pleyel footbridge ourselves—and it was a one-of-a-kind experience. Walking across the bridge, immersed in the subtle interplay of environmental sound and sculptural form, was both meditative and inspiring. While on site, we also conducted our own field recordings to capture the dynamic soundscape as it unfolded in real time. Listening through headphones, the bridge became even more alive—each gust of wind, each shifting light pattern, each ambient tone weaving into a delicate, ever-changing composition.
From 26 to 28th of March, we (the sound design master, second semester) had the incredible opportunity to visit IRCAM (Institut de Recherche et Coordination Acoustique/Musique) in Paris as part of a student excursion. For anyone passionate about sound, music technology, and AI, IRCAM is like stepping into new fields of research, discussion and seeing prototypes in action. One of my personal highlights was learning about the ACIDS team (Artificial Creatiive Intelligence and Data Science) and their research projects—RAVE (Real-time Audio Variational autoEncoder) and AFTER (Audio Features Transfer and Exploration in Real-time
ACIDS – Team
The ACIDS team is a multidisciplinary group of researchers working at the intersection of machine learning, sound synthesis, and real-time audio processing. Their name stands for Audio, Communication, Information, Data, and Sound, reflecting their broad focus on computational audio research. During our visit, they gave us an inside look at their latest developments, including demonstrations from the IRCAM Forum Workshop (March 26–28, 2025), where they showcased some of their most exciting advancements. Beside their really good and catchy (also a bit funny) presentation I want to showcase two projects.
RAVE (Real-Time Neural Audio Synthesis)
One of the most impressive projects we explored was RAVE (Real-time Audio Variational autoEncoder), a deep learning model for high-quality audio synthesis and transformation. Unlike traditional digital signal processing, RAVE uses a latent space representation of sound, allowing for intuitive and expressive real-time manipulation.
Overall architecture of the proposed approach. Blocks in blue are the only ones optimized, while blocks in grey are fixed or frozen operations.
Key Innovations
Two-Stage Training:
Stage 1: Learns compact latent representations using a spectral loss.
Stage 2: Fine-tunes the decoder with adversarial training for ultra-realistic audio.
Blazing Speed:
Runs 20× faster than real-time on a laptop CPU, thanks to a multi-band decomposition technique.
Precision Control:
Post-training latent space analysis balances reconstruction quality vs. compactness.
Enables timbre transfer and signal compression (2048:1 ratio).
Performance
Outperforms NSynth and SING in audio quality (MOS: 3.01 vs. 2.68/1.15) with fewer parameters (17.6M).
Handles polyphonic music and speech, unlike many restricted models.
You can explore RAVE’s code and research on their GitHub repository and learn more about its applications on the IRCAM website.
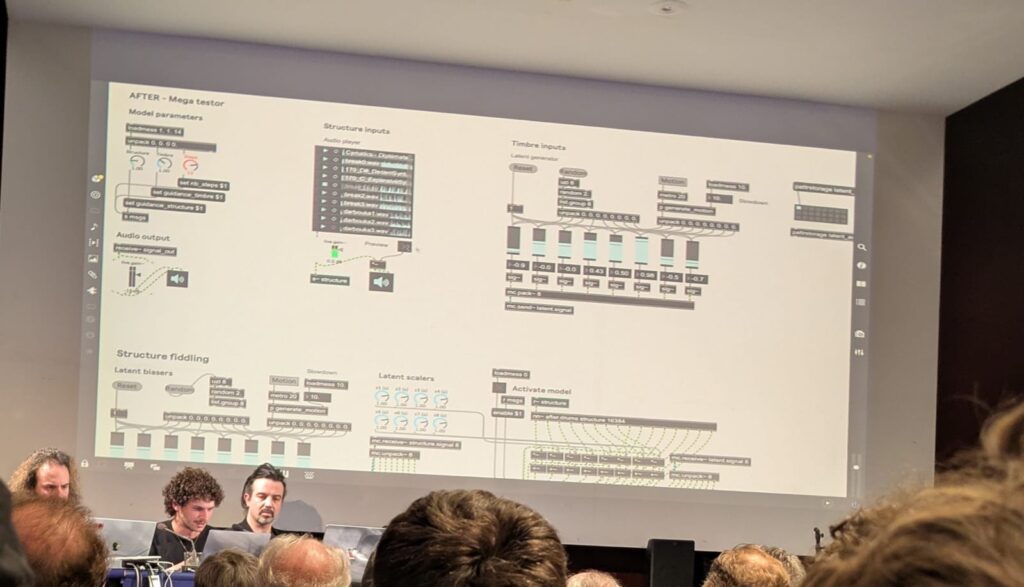
AFTER
While many AI audio tools focus on raw sound generation, what sets AFTER (Audio Foundation Transformer) apart is its sophisticated control mechanisms—a priority highlighted in recent research from the ACIDS team. As their paper states:
“Deep generative models now synthesize high-quality audio signals, shifting the critical challenge from audio quality to control capabilities. While text-to-music generation is popular, explicit control and example-based style transfer better capture the intents of artists.”
How AFTER Achieves Precision
The team’s breakthrough lies in separating local and global audio information:
Global (timbre/style): Captured from a reference sound (e.g., a vintage synth’s character).
Local (structure): Controlled via MIDI, text prompts, or another audio’s rhythm/melody.
This is enabled by a diffusion autoencoder that builds two disentangled representation spaces, enforced through:
Adversarial training to prevent overlap between timbre and structure.
A two-stage training strategy for stability.
Detailed overview of our method. Input signal(s) are passed to structure and timbre encoders, which provides semantic encodings that are further disentangled through confusion maximization. These are used to condition a latent diffusion model to generate the output signal. Input signals are identical during training and but distinct at inference.
Why Musicians Care
In tests, AFTER outperformed existing models in:
One-shot timbre transfer (e.g., making a piano piece sound like a harp).
MIDI-to-audio generation with precise stylistic control.
Full “cover version” generation—transforming a classical piece into jazz while preserving its melody.
Caillon, Antoine, and Philippe Esling. “RAVE: A Variational Autoencoder for Fast and High-Quality Neural Audio Synthesis.” arXiv preprint arXiv:2111.05011 (2021). https://arxiv.org/abs/2111.05011.
Demerle, Nils, Philippe Esling, Guillaume Doras, and David Genova. “Combining Audio Control and Style Transfer Using Latent Diffusion.”
Expanded research on sonification of images / video material and different approaches:
Yeo and Berger (2005) write in “A Framework for Designing Image Sonification Methods” about the challenge of mapping static, time-independent data like images into the time-dependent auditory domain. They introduce two main concepts: scanning and probing. Scanning follows a fixed, pre-determined order of sonification, whereas probing allows for arbitrary, user-controlled exploration. The paper also discusses the importance of pointers and paths in defining how data is mapped to sound. Several sonification techniques are analyzed, including inverse spectrogram mapping and the method of raster scanning (which already was explained in the Prototyping I – Blog entry), with examples illustrating their effectiveness. The authors suggest that combining scanning and probing offers a more comprehensive approach to image sonification, allowing for both global context and local feature exploration. Future work includes extending the framework to model human image perception for more intuitive sonification methods.
Time on “perpendicular” axis. (Yeo, Berger, 2005)Raster scanning method (Yeo, Berger, 2005)Pointers in different shapes: (a) single point, (b) line/curve, (c) area, and (d) set of distributed points. (Yeo, Berger, 2005)Inverse spectrogram scanning (Yeo, Berger, 2005)
Sharma et al. (2017) explore action recognition in still images using Natural Language Processing (NLP) techniques in “Action Recognition in Still Images Using Word Embeddings from Natural Language Descriptions.” Rather than training visual action detectors, they propose detecting prominent objects in an image and inferring actions based on object relationships. The Object-Verb-Object (OVO) triplet model predicts verbs using object co-occurrence, while word2vec captures semantic relationships between objects and actions. Experimental results show that this approach reliably detects actions without computationally intensive visual action detectors. The authors highlight the potential of this method in resource-constrained environments, such as mobile devices, and suggest future work incorporating spatial relationships and global scene context.
Iovino et al. (1997) discuss developments in Modalys, a physical modeling synthesizer based on modal synthesis, in “Recent Work Around Modalys and Modal Synthesis.” Modalys allows users to create virtual instruments by defining physical structures (objects), their interactions (connections), and control parameters (controllers). The authors explore the musical possibilities of Modalys, emphasizing its flexibility and the challenges of controlling complex synthesis parameters. They propose applications such as virtual instrument construction, simulation of instrumental gestures, and convergence of signal and physical modeling synthesis. The paper also introduces single-point objects, which allow for spectral control of sound, bridging the gap between signal synthesis and physical modeling. Real-time control and expressivity are emphasized, with future work focused on integrating Modalys with real-time platforms.
McGee et al. (2012) describe Voice of Sisyphus, a multimedia installation that sonifies a black-and-white image using raster scanning and frequency domain filtering in “Voice of Sisyphus: An Image Sonification Multimedia Installation.” Unlike traditional spectrograph-based sonification methods, this project focuses on probing different image regions to create a dynamic audio-visual composition. Custom software enables real-time manipulation of image regions, polyphonic sound generation, and spatialization. The installation cycles through eight phrases, each with distinct visual and auditory characteristics, creating a continuous, evolving experience. The authors discuss balancing visual and auditory aesthetics, noting that visually coherent images often produce noisy sounds, while abstract images yield clearer tones. The project draws inspiration from early experiments in image sonification and aims to create a synchronized audio-visual experience engaging viewers on multiple levels.
Software Interface for Voice of Sisyphus (McGee et al., 2012)
Roodaki et al. (2017) introduce SonifEye, a system that uses physical modeling sound synthesis to convey visual information in high-precision tasks, in “SonifEye: Sonification of Visual Information Using Physical Modeling Sound Synthesis.” They propose three sonification mechanisms: touch, pressure, and angle of approach, each mapped to sounds generated by physical models (e.g., tapping on a wooden plate or plucking a string). The system aims to reduce cognitive load and avoid alarm fatigue by using intuitive, natural sounds. Two experiments compare the effectiveness of visual, auditory, and combined feedback in high-precision tasks. Results show that auditory feedback alone can improve task performance, particularly in scenarios where visual feedback may be distracting. The authors suggest applications in medical procedures and other fields requiring precise manual tasks.
Dubus and Bresin review mapping strategies for the sonification of physical quantities in “A Systematic Review of Mapping Strategies for the Sonification of Physical Quantities.” Their study analyzes 179 publications to identify trends and best practices in sonification. The authors find that pitch is the most commonly used auditory dimension, while spatial auditory mapping is primarily applied to kinematic data. They also highlight the lack of standardized evaluation methods for sonification efficiency. The paper proposes a mapping-based framework for characterizing sonification and suggests future work in refining mapping strategies to enhance usability.
References
Yeo, Woon Seung, and Jonathan Berger. 2005. “A Framework for Designing Image Sonification Methods.” In Proceedings of ICAD 05-Eleventh Meeting of the International Conference on Auditory Display, Limerick, Ireland, July 6-9, 2005.
Sharma, Karan, Arun CS Kumar, and Suchendra M. Bhandarkar. 2017. “Action Recognition in Still Images Using Word Embeddings from Natural Language Descriptions.” In 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), 978-1-5090-4941-7/17. DOI: 10.1109/WACVW.2017.17.
Iovino, Francisco, Rene Causse, and Richard Dudas. 1997. “Recent Work Around Modalys and Modal Synthesis.” In Proceedings of the International Computer Music Conference (ICMC).
McGee, Ryan, Joshua Dickinson, and George Legrady. 2012. “Voice of Sisyphus: An Image Sonification Multimedia Installation.” In Proceedings of the 18th International Conference on Auditory Display (ICAD-2012), Atlanta, USA, June 18–22, 2012.
Roodaki, Hessam, Navid Navab, Abouzar Eslami, Christopher Stapleton, and Nassir Navab. 2017. “SonifEye: Sonification of Visual Information Using Physical Modeling Sound Synthesis.” IEEE Transactions on Visualization and Computer Graphics 23, no. 11: 2366–2371. DOI: 10.1109/TVCG.2017.2734320.
Dubus, Gaël, and Roberto Bresin. 2013. “A Systematic Review of Mapping Strategies for the Sonification of Physical Quantities.” PLoS ONE 8(12): e82491. DOI: 10.1371/journal.pone.0082491.
Music is often seen as a one-directional experience—composers create, performers interpret, and audiences listen. However, what if listeners could play a more active role in shaping the music they hear?
Movement as a Musical Element
In conventional concerts, the audience remains stationary while sound moves towards them. In contrast, this project leverages the open public space of the Joanneum Quarter to allow the audience to move through different acoustic environments, making movement an essential part of the musical experience.
This already begins with the Joanneum Quarters being an open public space, people cross during there everyday-life. There is no literal gate-keeping, which allows people to enter end leave the place and therefore the musical piece, whenever they like or stumble upon it.
Further the architectural design of the Joanneum Quarter introduces natural delays and phasing shifts as sound waves bounce off its curved glass structures as well as from the surrounding walls. This means that a e.g. melody played in one location may sound different depending on where a listener is standing. And because of time delays the layering of melodies result differently at different locations. As audience members walk through the space, their perception of the music changes, creating a dynamic and personal auditory experience.
Creating immersion via interfaces
Beyond the organic interaction caused by movement, the project considers additional ways to involve audiences directly in the performance. One may be the installation of interfaces:
By incorporating technical solutions such as speaker controls or digital interfaces, visitors can influence the composition itself. Simple adjustments—such as modifying the volume of different speakers—allow participants to shape their own experience. A more complex approach could involve digital interfaces, such as iPads placed around the space, where participants can select different musical elements for each acoustic funnel, effectively curating their own version of the performance.
Reimagining Concert Spaces: The Acoustic Landscape of Joanneum Quarter
Music and spaces have always shared a deep and inextricable relationship. The way sound interacts with space transforms the listening experience. By playing with it consciously we are creating an immersive experience that goes beyond traditional concert settings. This is the core idea behind the “Sounds of the Joanneum Quarters Graz” project—an innovative approach to ambient music and concert formats that redefines how audiences engage with sound.
The Vision: Transforming Public Spaces into Concert Venues
The project explores how the spatial dynamics of the Joanneum Quarter in Graz can shape a unique musical experience. Unlike conventional concert halls with fixed seating and predictable acoustics, this public space presents a lively environment where sound can evolve organically. The goal is to break down barriers associated with classical concert settings by offering an open, interactive listening experience that invites both intentional audiences and casual passersby.
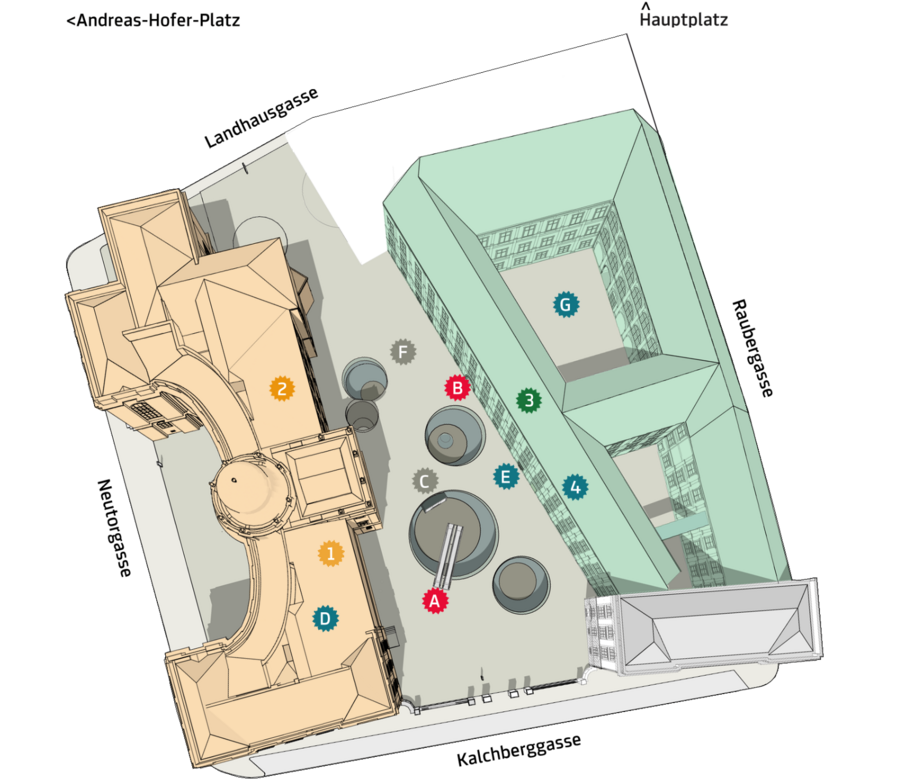
Architectural Influence on Sound
A key element of this project is the relationship between sound and architecture. The Joanneum Quarter is defined by its distinct conical funnels, made of curved glass with a silk-screen print that filters light. These architectural features create natural acoustic properties that influence how sound behaves within this space. By treating these funnels as integral instruments, the composition can interact with the environment rather than simply existing within it.
There are two primary compositional approaches considered:
Treating each funnel as an individual instrument, crafting site-specific musical material that resonates with the unique properties of each space.
Creating soundscapes that work across all funnels, allowing listeners to move through the space and experience varied auditory perspectives.
Embodied Resonance is an experimental audio performance that investigates the interplay between trauma, physiological responses, and immersive sound. By integrating biofeedback sensors with spatial sound, this project translates the body’s real-time emotional states into an evolving sonic landscape. Through this process, Embodied Resonance aims to create an intimate and immersive experience that bridges personal narrative with universal themes of emotional resilience and healing.
Reference Works
Inspiration for this project draws heavily from groundbreaking works in biofeedback art. For instance, Tobias Grewenig’s Emotion’s Defibrillator (2005) inspired me to explore how visual imagery can serve as emotional triggers, sparking physiological responses that drive sound. Grewenig’s project combines sensory input with dynamic visual feedback, using breathing, pulse, and skin sensors to create a powerful interactive experience. His exploration of binaural beats and synchronized visuals provided a foundation for my use of AR imagery and biofeedback systems.
Another profound influence is the project BODY ECHOES, which integrates EMG sensors, breathing monitors, and sound design to capture inner bodily movements and translate them into a spatialized audio experience. This project highlights how subtle physiological states, such as changes in muscle tension or breathing rhythms, can form the basis of a compelling sonic narrative. It has inspired my approach to using EMG and respiratory sensors as key components for translating physical states into sound.
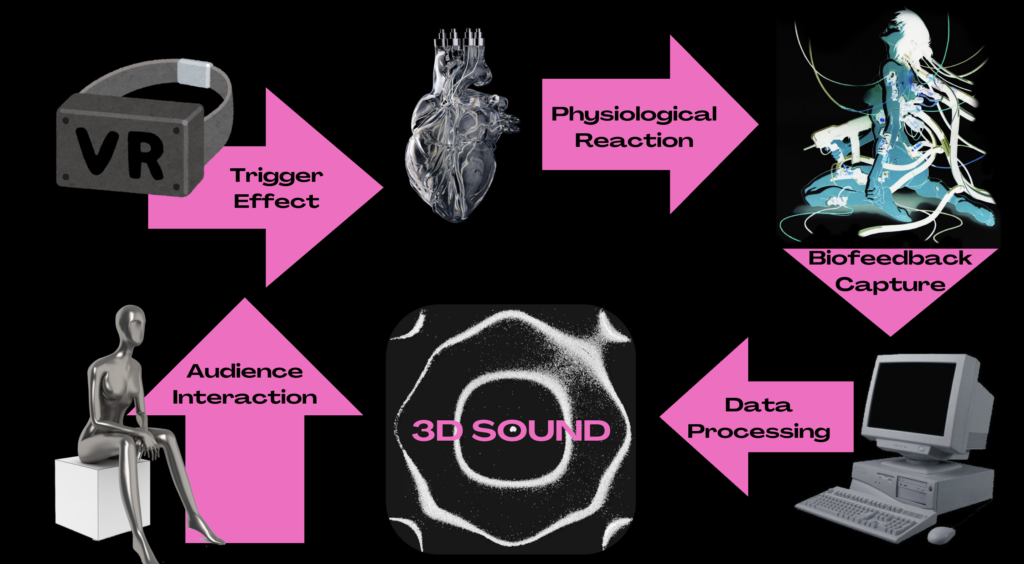
How Does It Work?
The performance involves the use of biofeedback sensors to capture physiological data such as:
Electromyography (EMG) to measure muscle tension
Electrodermal Activity (EDA/GSR) to track stress levels via skin conductivity
Heart Rate (ECG/PPG) to monitor pulse fluctuations and emotional arousal
Respiratory Sensors to analyze breath patterns
This real-time data is processed using software like Max/MSP and Ableton Live, which maps physiological changes to dynamic sound elements. Emotional triggers, such as augmented reality (AR) images chosen by the audience, influence the performer’s physiological responses, which in turn shape the sonic environment.
Core Components of the Project
Emotional Triggers and Biofeedback: The audience plays an active role by selecting AR-displayed imagery, which elicits emotional and physiological responses from the performer.
Sound Mapping and Generation: Physiological changes dynamically alter elements of the soundscape.
Spatial Audio and Immersion: An Ambisonic sound system enhances the experience, surrounding the audience in a three-dimensional sonic space.
Interactive Performance Structure: The performer’s emotional and physical state directly influences the performance, creating a unique, real-time interaction between artist and audience.
Why is This Project Important?
Embodied Resonance is an innovative approach to understanding how trauma manifests in the body and how it can be externalized through sound. This project:
Explores the intersection of biofeedback technology, music, and performance art
Provides a new medium for emotional processing and healing through immersive sound
Pushes the boundaries of interactive performance, inviting the audience into a participatory experience
Challenges conventional notions of musical composition by integrating the human body as an instrument
Why Do I Want to Work on It?
As a sound producer, performer, and music editor, I have always been fascinated by the connections between sound, emotion, and the body. My personal journey with trauma and healing has shaped my artistic explorations, driving me to create a performance that not only expresses these experiences but also fosters a shared space for reflection and empathy. By combining my technical skills with deep personal storytelling, I aim to push the boundaries of sonic expression.
How Will I Realize This Project?
Methods & Techniques
Research: Studying trauma, somatic therapy, and the physiological markers of emotional states.
Technology: Utilizing biofeedback sensors and signal processing tools to create real-time sound mapping.
Performance Development: Experimenting with gesture analysis and embodied interaction.
Audience Engagement: Exploring ways to integrate audience input via AR-triggered imagery.
Necessary Skills & Resources
Sound Design & Synthesis: Proficiency in Ableton Live, Max/MSP, and Envelop for Live.
Sensor Technology: Understanding EMG, ECG, and GSR sensor integration.
Spatial Audio Engineering: Knowledge of Ambisonic techniques for immersive soundscapes.
Programming: Implementing interactive elements using coding languages and software.
Theoretical Research: Studying literature on biofeedback art, music therapy, and embodied cognition.
Challenges and Anticipated Difficulties
Spatial Audio Optimization: Achieving an immersive sound experience that maintains clarity and emotional depth.
Technical Complexity: Ensuring seamless integration of biofeedback data into real-time sound processing requires rigorous calibration and testing.
Emotional Vulnerability: The deeply personal nature of the performance may present emotional challenges, requiring careful preparation.
Audience Interaction: Designing a system that effectively incorporates audience input without disrupting the emotional flow.