Growing up as a shy kid, I often wished that people, whether peers, teachers, or other adults, would just let me process things in my own way and on my own time, but that rarely happened. Because of this, I’ve become interested in exploring topics for my thesis, like anxiety and social anxiety, which feel closely connected to who I am and how I move through the world. It also makes me wonder: how might playful interactive experiences help ease feelings of anxiety or make social situations feel safer?
For this blog post, I wanted to expand on the previous impulse about inclusivity. So I listened to three episodes of the podcast Speaking of Psychology, which broadly explore the topic of anxiety.
Here are my thoughts:
Episode: “Why are some kids shy? with Dr. Koraly Pérez-Edgar” In the episode, Koraly Pérez‑Edgar explains that shyness is a natural temperament that shows up early in life and affects how kids interact with the world. Shyness isn’t something that needs to be fixed; it’s just a different way of engaging with people and activities.
Episode: “Anxiety and Teen Girls with Dr. Lisa Damour” In the episode, the conversation questions the way society frames anxiety: as something abnormal or in need of fixing. Dr. Damour emphasizes that anxiety is a natural part of being human, yet the growing expectations placed on girls today can turn it into something harmful. Many feel pressured to excel academically, maintain a perfect appearance, and stay kind and composed, while social media intensifies those expectations.
Episode: “How to help with math anxiety, with Dr. Molly Jameson” In this episode, Dr. Molly Jameson talks about math anxiety, a common fear that affects how people feel and perform when doing math. It often begins with negative school experiences or strict teaching methods that make students associate math with embarrassment or failure. Over time, this fear can block people from accessing knowledge they already have, and it’s sometimes reinforced by cultural stereotypes like “boys are better at math.
My Reflection Listening to these episodes made me think about how deeply anxiety connects to the environments we grow up and learn in. It isn’t always about the person themselves, but often about how expectations, pressure, or fear of judgment shape how we act and feel. That makes me wonder: if anxiety is such a natural part of being human, what would it mean to design for it rather than against it? Could design create spaces that accept anxiety instead of trying to remove it?
For my thesis, I’m curious about how play might offer a way to do that. What if playful experiences could make social or learning situations feel safer: less about performing and more about exploring? How could interaction design give people permission to engage at their own pace, to choose how visible they want to be, or to participate quietly without pressure? Maybe play can become a tool for inclusion, helping people connect and express themselves in ways that feel natural to them.
AI was used for corrections, better wording, and enhancements.
Die heutige Session mit Daniel Bauer war extrem ergebnisreich, weshalb ich mich dazu entschlossen habe, mir gleich alle Ideen und Inputs von der Seele zu schreiben. Auch, weil zwar viele Fragen beantwortet wurden, aber dafür noch mehr neu entstanden sind, die ich dann noch mit dir Roman (ja du wirst auch hier wieder der einzige sein der das liest) besprechen muss.
Input 1: DIE Lichttechnik für Horrorfilme werde ich auch in 500 Standardwerken nicht finden, da Filme hauptsächlich von zwei Dingen geprägt werden: Einerseits der Zeit in der sie gedreht werden und andererseits dem DP der sie shootet. Genau daraus könnte man aber dafür eine Forschungsfrage ableiten. Etwa wie sich die Lichtsetzung in Horrorfilmen über die Zeit verändert hat, angefangen bei Nosferatu in den 20ern über erste richtige Splasher-Filme bis hin zu neuen Horrorfilmen der 2010er und 2020er Jahre. Auch könnte man einzelne DP´s, die sich sehr im Horrorgenre vertieft haben herauspicken und analysieren.
Input 2: Nicht zu viele Standardwerke nehmen. In meiner aktuellen Bibliographie finden sich einige Standardwerke zum Thema Lichtsetzung. Daniel meint die werden mich alle nicht schlauer machen, und nicht weiter an das heranbringen was mich interessiert. Viel besser wäre es vielleicht ein einziges Standardwerk zu haben und in der weiteren Literatur dann viel stärker einzugrenzen und die Auswahl wirklich auf Quellen zu beschränken in denen es strikt um Leuchttechniken für Horrorfilme geht, nicht für Film generell.
Input 3: Wie sehr muss die Entstehung des Kurzfilms Teil der Masterarbeit sein? Muss jeder Schritt, von der Ideenfindung, des Script writing, shotlisten, location scouten, storyboarden etc. vollumfänglich im Theorieteil der Masterarbeit dokumentiert werden, und mit Quellen belegt werden? A la für das script wurde das Buch “Save the Cat” verwendet mit diesen und jenen Frameworks und dann die Storybeats auflisten usw, und das für jeden Schritt? Falls ja, und da hat Daniel Recht, übernehm ich mich mit der Arbeit um circa 270%.
Grundsätzlich hat Daniel schon angezweifelt ob ich überhaupt mit dem Theorieteil dann einen wirklich zusammenhängenden Kurzfilm produzieren muss, oder ob es etwa nicht reicht die 4-5 Schlüsselszenen herauszunehmen und sich mit diesen dann wirklich tagelang beschäftigen und diese komplett perfekt zu leuchten. Sodass, das Werkstück am Ende dann aus mehreren “perfekten” Stills, oder Shots besteht. (Als Inspiration dazu: Gregory Crewdson.) Das würde den Workload natürlich extrem verkleinern und machbarerer gestalten. Womit ich ihm grundsätzlich vollkommen zustimme, wohlwissend, dass ich halt einfach unfassbar gern den gesamten Kurzfilm drehen würde.
Daher nun die Gretchenfrage: Reicht es sich im Theorieteil ausschließlich mit dem eigenen Thema, in meinem Fall eben Lichttheorien in Horrorfilmen auseinanderzusetzen, dann einen Horrorfilm nach dieser Theorie zu drehen und am Ende einfach Stills aus dem Film in den schriftlichen Teil aufzunehmen und zu erklären warum man in dieser oder jener Situation so geleuchtet hat. Oder muss der gesamte Entstehungsprozess des Films auch dokumentiert und wissenschaftlich belegt werden? Denn sonst halte ich mich wahrscheinlich einfach zu lange mit anderen Dingen auf, die aber eigentlich gar nicht mein Hauptthema, nämlich Licht, sind.
Input 4: Jakob Slavicek wäre ein Adresse, die ich mir so oder so unbedingt genauer ansehen sollte. Daniel kennt ihn als Oberbeleuchter und weiß, dass er immer wieder Praktikanten auf Drehs mitnimmt. Vielleicht könnte ich mit einer netten Mail versuchen, einfach mal bei einem Spielfilm Dreh, bei dem er als Gaffer arbeitet, als Volo mitkommen, und mir Dinge abschauen. Außerdem betreibt er einen Verleih, der spätestens für meinen echten Dreh dann interessant wird, wenn die 600er Aputure von der FH an ihre Grenzen kommen.
Um gleich nahtlos an den ersten Impuls anzuschließen, möchte ich mit einem ganz neuen Video von Mark Bone fortfahren, das erst vor wenigen Stunden veröffentlicht wurde und gleich meine Aufmerksamkeit erlangte.
Anders als Luc Ung ist Mark Bone mehr der klassische Film-Content-Creator auf Youtube, der aber mit seinem Online-Kurs “Art of Documentary” doch recht große Berühmtheit erlangt hat. Durch den hohen Preis habe ich mich aber leider nie drüber getraut mir diesen auch wirklich zu kaufen. Dennoch verfolge ich Bone gerne, da er im Gegensatz zu anderen auch wirklich selbst noch als Filmemacher an großen Projekten arbeitet. Die Doku über CBum zum Beispiel, die er in vielen seiner letzten Videos als B-Roll immer wieder anteasert, sieht nämlich brutal aus und ist, soweit ich weiß, eine Produktion für Prime Video, also der Mann weiß schon was er tut. Gerade deshalb hat mich interessiert ob sich sein “System” inhaltlich wirklich groß von dem unterscheidet was ich mir in Impuls 1 angeschaut habe. Deshalb werde ich dieses kurz zusammenfassen und erklären und danach einordnen.
Mark Bone´s System
1. Track the Sun: Als ersten Schritt, wenn man in einen Raum bekommt, empfiehlt Bone die Sonne abzuchecken und mit Apps wie dem klassischen Kompass oder Sunseeker etc. die Ausrichtung der vorhandenen Fenster herauszufinden. Dies entscheidet wie man dann mit den Fenstern umgeht. Ob man sie also als Key oder Kicker verwenden kann, oder vielleicht ganz ausblockt und nur künstlich belichtet, weil sich die Sonne während der Zeit des Interviews zu viel bewegen würde. Als Merksatz: Fenster Richtung Süden geben hartes Licht, Fenster nach Norden weiches Licht.
Control the variables: Als zweites empfiehlt Bone die ganze Szene einmal zu “deaktivieren”, alle Rollos runter, alle Lichter aus. Und dann Stück für Stück mit Absicht das wieder zu aktivieren, was für die Szene Sinn macht.
Define the Motivation: Finde heraus wo in deiner Szene auf natürliche Art und Weise das meiste Licht kommen würde. Im Normalfall wäre das ein Fenster oder die stärkste Lampe im Raum. Diese Quelle bestimmt die Seite von deinem Fill, die du dann mit einer Softbox etc. verstärken kannst. Bone empfiehlt die Originalquelle als Practical oder als Anschnitt im Frame zu lassen, um dem Zuschauer zu erklären wo das Licht herkommt.
Choose Quality of Light: Entscheide ob du hartes oder softes Licht haben willst. Bone empfiehlt dabei immer die Quality der Motivation zu imitieren, um den natürlichsten Look zu erhalten. Ist die Motivation im Frame eine Tischlampe, wird das Key z.B. eher hart.
Place your subject: Mit der Motivation und dem Key fix aufgestellt, empfiehlt Bone jetzt den Shot quasi zu locken und das Subjekt final zu platzieren. Dafür empfiehlt er, dass die Person den dreifachen Abstand zu nächsten Wand im Hintergrund hat, im Vergleich zum Abstand zwischen Person und Kamera, um genug Tiefe zu kreieren.
Choose the Lens: Wenn das Subjekt sitzt stellt Bone die Kamera final auf und wählt die Linse. Dafür nimmt er fast immer eine 35er, um genug Hintergrund ins Bild zu bekommen und noch Raum für eine engere zweite Einstellung zu lassen.
Shape the contrast: Jetzt bestimmt Bone das lighting ratio des Subjekts. Grundsätzlich empfiehlt er nur dann ein Fill light zu verwenden wenn es wirklich nötig ist und lässt dieses oft ganz weg oder benutzt natürlich negative fill. Für ein nettes Gespräch empfiehlt er 2:1, für ernste Themen 4:1.
Build the background: Jetz wo Key, Kamera und Subjekt stehen, baut er noch den Hintergrund für maximale dreidimensionale Wirkung. Dafür fügt er nach und nach noch practicals im Hintergrund hinzu (gerne in anderen Temperaturen als das key) oder beleuchtet diesen von außerhalb ohne aber das Subjekt zu überstrahlen. Alternativ kann der Separation auch klassisch mit einem Kicker light erfolgen, er ist aber nicht wirklich Fan davon, weil es dann laut ihm zu sehr nach einem Studio aussieht und nicht mehr als wäre man wirklich bei der Person zu Hause.
Expose and Balance Color: Jetzt stellt Bone erst die Belichtung und den Weißabgleich in der Kamera ein. Dabei gleicht er nicht automatisch key und Kamera Farbtemperatur miteinander an, sondern wählt die Temperatur in der Kamera je nach Look: Kühler für seriöse Interviews (corporate style), wärmer für emotionale Interviews.
Stresstest: Zu allerletzt, lässt er das Subjekt sprechen und sich bewegen. Bewegt es sich aus dem Licht? Sind Handgesten nicht im Frame etc? Er macht das Setup bulletproof, um nicht erst danach etwaige Fehler zu bemerken und nimmt ein Testvideo auf.
Fazit
Ich fand Bone´s Herangehensweise extrem interessant, da ich selbst schon sehr oft klassische Interviews oder Talking Head Szenen gefilmt habe und auch mein nächster Auftrag genau daraus bestehen wird. Neu und aufschlussreich war dabei für mich wie er mit der Sonne arbeitet, wie er lighting motivation findet, um den Frame natürlich wirken zu lassen, und wie er entscheidet wie weit sich das Subjekt von der Wand entfernt. Das sind finde ich sind sehr einfache und leicht umzusetzende Guidelines.
Im Verglech zu Luc Ung ist die Abfolge der essenziellen Schritte des Beleuchtens eigentlich sehr gleich: Zuerst findet er die Motivation und passt dann Richtung, Härte und Farbe dementsprechend an. Dann bestimmt er die Stärke des Lichts bei der Wahl des Kontrastverhältnisses und wenn man so will ist das was Luc Ung als letztes macht, nämlich das Licht noch zu formen um ungewollte light spills zu verhindern, auch das worauf Bone im Stresstest am Schluss noch einmal achtet.
Ich finde beide Systeme daher unglaublich hilfreich, Bone´s für klassische Interview Szenarien und Ung´s im klassischen narrativen Filmmaking.
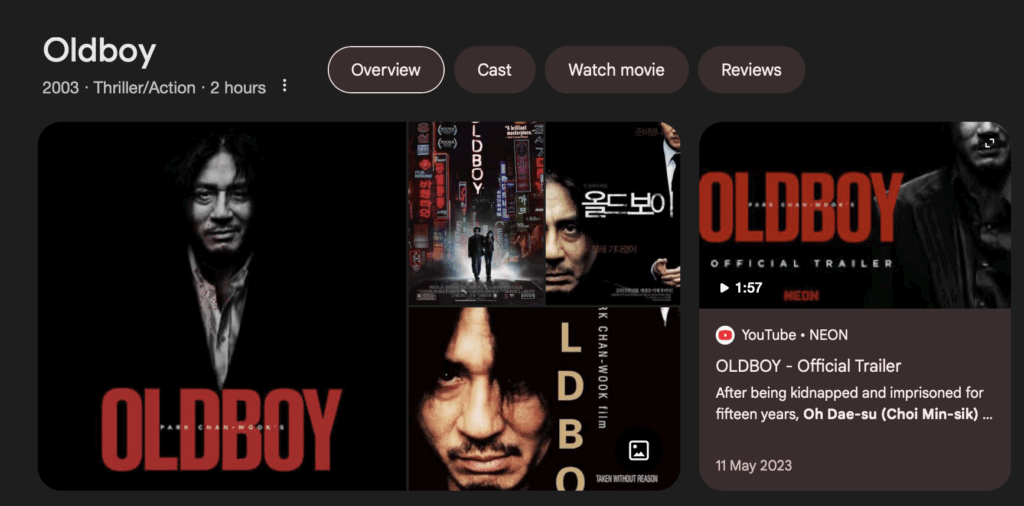
In one of our ChatGPT tips classes, we learned how to use AI to get creative ideas and ask better questions. For fun, I asked ChatGPT to recommend a movie that would fit my mood — something emotional, with a strong story and a big plot twist. It suggested “Oldboy”, a South Korean movie from 2003 directed by Park Chan-wook. I dont usually watch Korean films, more accurate would be to say that its not my style but i decided to watch it, and it honestly surprised me in every possite way.
From the first few minutes, the film caught my attention because of how it’s designed visually. The lighting, colors, camera angles everything feels very alive. It’s not just telling a story; it’s creating an experience. Some scenes are quiet and slow, others feel chaotic and close, and it all builds up this weird mix of curiosity and tension.
Now here comes the big part — the plot twist (Spoiler warning for anyone who hasn’t seen it!) Everything Dae-su went through — being locked up, being released, meeting a young woman who helps him — was actually part of someone’s long, cruel revenge plan. The shocking reveal is that the woman he falls in love with is his own daughter, and the villain set it all up to make him suffer. It’s a hard twist to process, but it completely changes how you see the story.
I started thinking about it from a media design point of view. The movie doesn’t just surprise the viewer it builds that surprise carefully through design. Also had an elements of hints all around the movie little ones. In “Oldboy,” both the character and the audience are trapped inside a story they don’t fully understand until the end. In a way, that’s similar to how designers shape user experiences in digital spaces — users think they’re exploring freely, but in reality, everything has been planned to create a certain feeling or reaction.
Watching this film after getting it from ChatGPT also showed me how AI can actually help in creative research. I wouldn’t have picked this movie myself, but it matched exactly what I asked for something emotional and complex. so at the end I was really happy with my “film of choice”
“Oldboy” gave me a strong impulse for my Ai generated film. That why I also wanted to do something with plot twists. the same kind of engagement I want to create through AR design in retail.
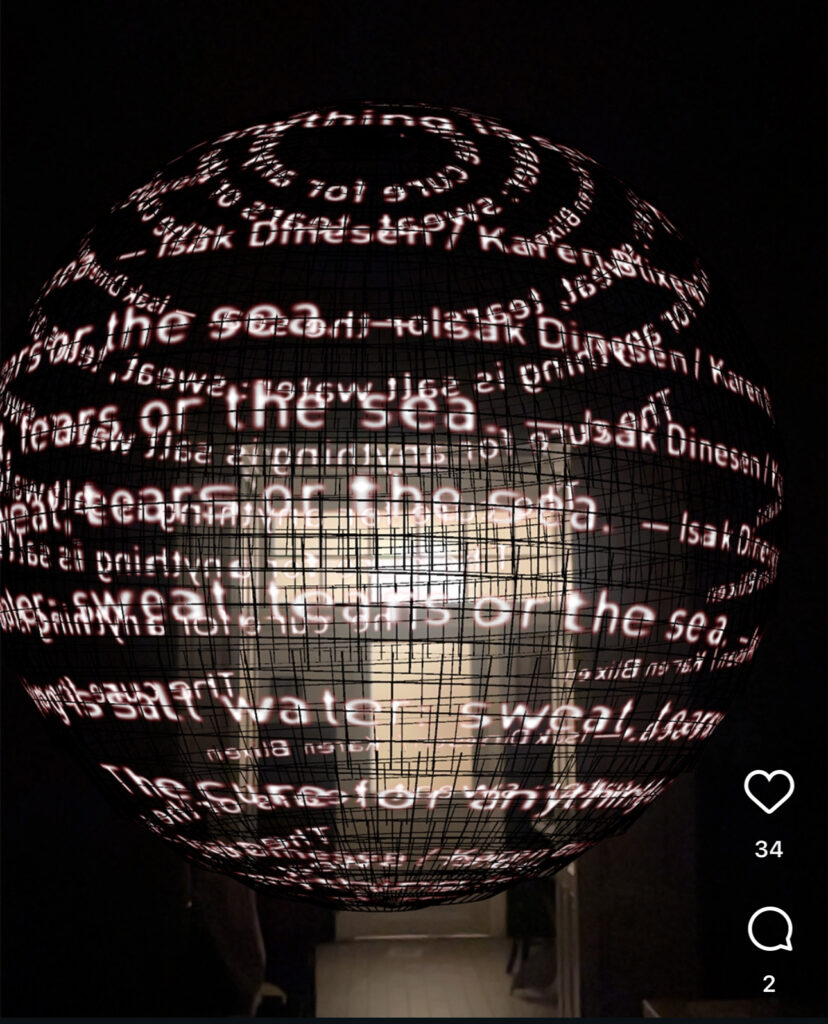
During the Klanglicht Festival in Graz, I visited the installation “SPHÄREN” at the Graz Museum Schlossberg. It was made up of three big glowing spheres that people could walk into. Each one had floating light texts around it with different mood some were poetic, some philosophical talking about things like space, perception, and so on. The main part of it was AR set up that was making it possible to see the instillation.
At first, I wasn’t really sure what people were doing there or what the idea behind it was. But after watching for a bit seeing people having fun and enjoying their time , it started to make sense. it turned out to be really impressive. The light, the sound, and the way people moved through the spheres created not only fun but also calm atmosphere. I
This experience gave me even more inspiration for my master’s thesis: “Designing Immersive Retail Experiences: How Design in AR/VR Environments Shapes Consumer Engagement” The installation showed me how AR design can change people mood and be fun. I clearly saw that it guided people emotionally and made them explore, even without clear instructions. Also after figuring out app and how it works turn out it was not that complicated after all.
Thinking about it from an AR design point of view, the night setting played a big role in how the installation felt. The darkness made the glowing spheres and text stand out much more, almost like how digital elements appear on a phone screen in low light. so contrast and environment are really important for visibility in AR. The lighting created focus and made every interaction clearer something I definitely want to consider..
Even though Klanglicht is an art event, it reminded me how immersive media design can change how people behave and feel in a space. It’s not just about technology it’s about new way of showing your product and changing people experiences. That’s exactly what I want to explore in my own project.
Intelligent Sound Fallback Systems – Enhancing Audio Generation with AI-Powered Semantic Recovery
After refining Image Extender’s sound layering and spectral processing engine, this week’s development shifted focus to one of the system’s most practical yet creatively crucial challenges: ensuring that the generation process never fails silently. In previous iterations, when a detected visual object had no directly corresponding sound file in the Freesound database, the result was often an incomplete or muted soundscape. The goal of this phase was to build an intelligent fallback architecture—one capable of preserving meaning and continuity even in the absence of perfect data.
Closing the Gap Between Visual Recognition and Audio Availability
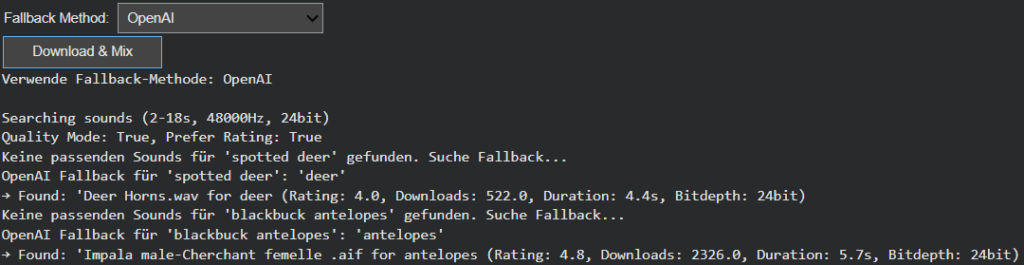
During testing, it became clear that visual recognition is often more detailed and specific than what current sound libraries can support. Object detection models might identify entities like “Golden Retriever,” “Ceramic Cup,” or “Lighthouse,” but audio datasets tend to contain more general or differently labeled entries. This mismatch created a semantic gap between what the system understands and what it can express acoustically.
The newly introduced fallback framework bridges this gap, allowing Image Extender to adapt gracefully. Instead of stopping when a sound is missing, the system now follows a set of intelligent recovery paths that preserve the intent and tone of the visual analysis while maintaining creative consistency. The result is a more resilient, contextually aware sonic generation process—one that doesn’t just survive missing data, but thrives within it.
Dual Strategy: Structured Hierarchies and AI-Powered Adaptation
Two complementary fallback strategies were introduced this week: one grounded in structured logic, and another driven by semantic intelligence.
The CSV-based fallback system builds on the ontology work from the previous phase. Using the tag_hierarchy.csv file, each sound tag is part of a parent–child chain, creating predictable fallback paths. For example, if “tiger” fails, the system ascends to “jungle,” and then “nature.” This rule-based approach guarantees reliability and zero additional computational cost, making it ideal for large-scale batch operations or offline workflows.
In contrast, the AI-powered semantic fallback uses GPT-based reasoning to dynamically generate alternative tags. When the CSV offers no viable route, the model proposes conceptually similar or thematically related categories. A specific bird species might lead to the broader concept of “bird sounds,” or an abstract object like “smartphone” could redirect to “digital notification” or “button click.” This layer of intelligence brings flexibility to unfamiliar or novel recognition results, extending the system’s creative reach beyond its predefined hierarchies.
User-Controlled Adaptation
Recognizing that different projects require different balances between cost, control, and creativity, the fallback mode is now user-configurable. Through a simple dropdown menu, users can switch between CSV Mode and AI Mode.
CSV Mode favors consistency, predictability, and cost-efficiency—perfect for common, well-defined categories.
AI Mode prioritizes adaptability and creative expansion, ideal for complex visual inputs or unique scenes.
This configurability not only empowers users but also represents a deeper design philosophy: that AI systems should be tools for choice, not fixed solutions.
Toward Adaptive and Resilient Multimodal Systems
This week’s progress marks a pivotal evolution from static, database-bound sound generation to a hybrid model that merges structured logic with adaptive intelligence. The dual fallback system doesn’t just fill gaps, it embodies the philosophy of resilient multimodal AI, where structure and adaptability coexist in balance.
The CSV hierarchy ensures reliability, grounding the system in defined categories, while the AI layer provides flexibility and creativity, ensuring the output remains expressive even when the data isn’t. Together, they form a powerful, future-proof foundation for Image Extender’s ongoing mission: transforming visual perception into sound not as a mechanical translation, but as a living, interpretive process.
Mein erster Impuls für die diessemestrige Blogserie ist ein Youtube-Video, das mich gleichzeitig auch überhaupt erst auf die Idee für meine Masterarbeit gebracht hat und das ich einfach unfassbar hilfreich gefunden habe.
Grundsätzlich habe ich das Thema Licht bisher in diesem Master extrem stiefmütterlich behandelt. Natürlich kann man als kompletter Quereinsteiger nicht alles können, weshalb ich mich anfangs extrem in die camera operation vertieft habe und versucht habe meinen Kopf in das unendlich tiefe Rabbit Hole verschiedener Kamerasensoren, Belichtungsmethoden, Rigs, Cameramovements, Gear etc. zu stecken. Für das, was ich jetzt als Event/Sportvideograph so mache, ist das natürlich auch die Basis, immerhin kann ich schwer eine 1200er Aputure mit auf den Fußballplatz oder auf den Altar bei einer Hochzeit nehmen. Dabei ist mir aber (und so rede ich erst seit ich exakt dieses Youtube-Video gesehen habe und das nächste Rabbit-Hole aufgegangen ist) unfassbar viel entgangen. Denn spannend wird filmmaking erst wenn du nicht gezwungen bist mit dem zu arbeiten was da ist, sondern wenn du dein Bild meisseln kannst wie ein Bildhauer seine Skulptur. Und da kommt Licht ins Spiel.
Da es einfach so ein unfassbar großes Thema ist habe ich mich aber lang nicht getraut einfach mittendrin anzufangen ohne genau zu wissen, ob ich jetzt grad irgendwo in den Basics stecke oder mir grade extrem fortgeschrittene Techniken anschaue. Lange habe ich mir daher erhofft im Curriculum noch ein paar Basiskurse zu finden, außer einen einzigen eintägigen Workshop kam da aber leider genau gar nichts daher, weshalb ich noch viel froher darüber bin, dass mir der Youtube-Algorithmus genau dieses Video auf meine For-You gespielt hat und mich in nur 27 Minuten – Achtung – erleuchtet hat. Aber jetzt medias in res.
Who the fuck is Luc Ung
Luc Ung ist ein (mir bis dato unbekannter) DP aus LA, dessen Werke schon auf diversen Fim Festivals dieser Welt gescreened wurden und meiner Meinung nach unfassbar aussehen. Einen Eindruck davon könnt ihr euch auf seiner Homepage (https://www.lucung.com/) verschaffen. Statt wie bei anderen klassischen Youtube Erklärbären, die alle 3 Tage ein Video mit dem neuen besten Trick allerzeiten veröffentlichen, der dann eigentlich gar nicht so neu und auch gar nicht so gut ist, hat Luc Ung nur ein einziges Video auf seinem Kanal, nämlich dieses. Und das auch nur, weil er so oft darum gebeten worden sei, sein Wissen für immer festzuhalten, meint er zumindest. Fand ich anfangs ganz witzig, konnte ich 27 Minuten später aber ziemlich gut nachvollziehen.
Im kommenden fasse ich, das grundlegende Konzept mit dem er an Licht herangeht kurz zusammen. Ich glaube nicht, dass sich genau diese Vorgehensweise, genau diese Begriffe oder ähnliches auch in anderen (gedruckten) Standardwerken wiederfinden lassen – ob das so ist wird sich spätestens mit Ende dieses Blogs im Jänner herausstellen, wenn ich diese auch gelesen habe. Trotzdem hat mir sein System den Einstieg in die Welt des Lichts unfassbar vereinfacht und deshalb teile ich sie auch mit euch. (Wohlwissend, dass niemand außer du Roman diese Worte jemals lesen wird. Liebe Grüße an der Stelle an dich!)
Ung´s System
Grundsätzlich beschreibt Ung Licht mit insgesamt fünf verschiedenen Charakteristiken: Richtung, Härte, Farbe, Stärke und Form. Dabei sind aber nicht nur die fünf Charakteristiken an sich wichtig, sondern auch ihre Reihenfolge, da er beim Beleuchten einer Szene in genau dieser Reihenfolge vorgeht und sein Licht dementsprechend anpasst. Grundsätzlich versucht Ung in jeder Einstellung soviele Kontraste zwischen Hell und Dunkel zu erzeugen wie möglich (chiaroscuro). Nicht nur im Gesicht, sondern im gesamten Frame. Je öfter ein Bild, wenn man es von links nach rechts liest, zwischen hell und dunkel wechselt, desto interessanter wirke der Shot auch, da er mehr Dimension bekommt. Immerhin muss man eine dreidimensionale Welt auf einer zweidimensionalen Leinwand abbilden.
1. Richtung
Frontlight: Beim Frontlicht, stehen Licht und Kamera in einer Achse zur Szene. Dies hat zwei entscheidende Nachteile. Einerseits geht natürlich der gesamte Kontrast im Gesicht verloren, da es komplett ausgeleuchtet ist, andererseits ist aber natürlich auch fast unmöglich nicht gleichzeitig auch den Hintergrund mit auszuleuchten. Dadurch geht noch eine weitere Kontrastebene verloren.
Butterfly light: Das Butterfly light ist quasi eine Erweiterung des Frontlight. Möchte man sein Subjekt unbedingt aus derselben Richtung leuchten wie die Kamera, so macht es Sinn, dies aus großer Höhe und mit starkem Winkel zu machen. Dies umgeht die Nachteile des Frontlights. Statt einem komplett ausgeleuchteten Gesicht werfen Elemente wie Wangen und die Nase Schatten nach unten (wie ein Schmetterling) und erzeugen so Kontrast. Außerdem umgeht man so auch den Hintergrund komplett mit auszuleuchten. Das Butterfly light sieht nicht zwingend schön aus und kann sogar stören, wenn etwa ein markantes Gesicht extrem starke Schatten wirft. Daher könnte es in meiner Arbeit für böse Charaktere interessant sein.
Rembrandt light: Der Klassiker aller Klassiker. Dabei wird die Lichtquelle ca 45 Grad entfernt Eyeline und aus ca 45 Grad Höhe aufgestellt und leuchtet eine Gesichtshälfte aus. Der Nasenschatten erzeugt dabei unter dem Auge der anderen Seite ein helles Dreieck (Rembrandt Dreieck). Diese Richtung ist die am öftesten genutzte und erzeugt angenehme, dreidimensionale Ergebnisse.
Side Light: Beim Side light, wandert das Licht weitere 45 Grad von der Eyeline des Subjekts weg und steht damit im rechten Winkel (oder ca 80 Grad). So wird eine Gesichtshälfte gar nicht belichtet und die andere voll.
Kicker (Edge Light): Dabei wandert das Licht hinter das Subjekt und strahlt dieses aus ca 15-45 Grad hinter dem rechten Winkel des Sidelights an. Beleuchtet werden dabei die Kopfkonturen und die Schulter. Während es auch für sich alleine stehen kann wird es meistens natürlich gepaart. Der Kicker ist die beste Variante um eine weitere Abwechslung zwischen Hell und Dunkel zu ermöglichen und das Subjekt dreidimensionaler wirken zu lassen.
Backlight: Genau das Gegenteil des Frontlights, bei dem das Licht also direkt hinter der Eyeline des Subjekts steht. Der Unterschied zum Kicker ist, dass der Kicker auch das Kinn trifft, während das Backlight wirklich nur die Konturen des Kopfes und der Schulter trifft. Anwendungsgebiete sind gleich. Tipp: Muss von oben kommen, um lens flares zu vermeiden.
Zusatz: Ung sieht beim Wählen der Lichtrichtung die Wirkung wichtiger als die Realität, gerade wenn practicals im Shot sind. Er beweist dies mit einer Szene aus Herr der Ringe in der zwei Charaktere im Freien miteinander reden und in ihren einzelnen Close-Ups haben beide die Sonne als Backlight, was physikalisch wohl nur auf Mittelerde möglich ist, in der Bildwirkung aber Sinn macht, da beide gleich fühlen.
2. Härte
Lichthärte beschreibt wie diffus oder direkt Licht auf das Subjekt trifft. Das entscheidet ob die entstehenden Schatten harte Kanten haben, oder weiche Verläufe.
Die Härte des Lichts entsteht dabei im relativen Verhältnis zwischen der Größe des Lichts und der Größe des Subjekts. Je größer die Lichtquelle, desto weicher das Licht. Auch eine große Lichtquelle kann aber hartes Licht produzieren, wenn sie weit genug entfernt ist, da sie in Relation dann wieder klein erscheint. Die besten Beispiele hierfür sind eine Soft Box und die Sonne. Die Soft Box vergrößert die Lichtquelle von einem kleinen Punkt auf eine metergroße Box und macht so hartes Licht weich. Die Sonne hingegen, obwohl sie die wohl größte Lichtquelle ist, die man finden kann, produziert hartes Licht, weil sie durch die große Entfernung so klein erscheint. Will ich am Set softeres Licht, muss ich also die Lichtquelle vergößern (SoftBox, Diffusion sheet etc) und/oder das Licht näher ans Subjekt bringen und vice versa.
Farbe
In Sachen Farbe geht Ung nur auf die klassische Farbtemperatur ein, also die Calvin Range von 2500-7000K. Grundsätzlich empfiehlt Ung die Farbtemperatur der Kamera und jenes des wichtigsten Lichts (also meistens des Key Lights, aber vielleicht auch der Sonne etc.) miteinander abzustimmen. Um Gefühle zu transportieren (etwas eine kalte Winternacht, oder den Sommer deines Lebens) kann es aber natürlich von Vorteil sein die Kamera absichtlich wärmer und kälter einzustellen als das Key. Essenziell dafür ist aber natürlich zu wissen wieviel Kelvin die Lichtquelle hat. Was ich aus Ung´s Erklärung nicht ganz herausfinden konnte, war ob es egal ist welchen der beiden Parameter ich verändere, also ob es das gleiche Bild erzeugt, wenn ich die Kamera absichtlich kälter oder das Licht absichtlich wärmer einstelle.
Intensität
Da Richtung, Härte und Farbe direkt auch bestimmen wieviel Licht nun auf das Subjekt trifft, macht es laut Ung überhaupt keinen Sinn die Intensität vor diesen anzupassen. Heißt: Zuerst zufrieden mit Richtung, Härte und Farbe sein und dann um die Intensität kümmern.
Die für die Intensität des Lichts zentrale Metrik sind laut Ung die Verhältnisse, also lighting ratios. Einerseits das Verhältnis innerhalb des Gesichts (key to fill) und das Verhältnis zwischen Vor- und Hintergrund (also in den meisten Fällen zwischen Subjekt und Hintergrund).
Das ratio an sich kann man dabei über zwei Arten angeben, entweder in stops oder als klassisches Verhältnis. Ein 2:1 Verhältnis, bei dem der helle Teil doppelt so hell ist wie der dunkle, wäre dabei ein 1 stop ratio, 4:1 sind 2 stops usw.
Um sich sinnvoll Gedanken über das Verhältnis machen zu können empfiehlt Ung gerade bei key to fill, zuerst das key light so einzustellen, dass die Exposure technisch in der Kamera passt und dann nicht mehr anzugreifen. Stattdessen wird dann nur mehr über die Intensität des Fills, das Verhältnis bestimmt, wobei “Fill” hierbei natürlich auch negative Fill sein kann, sollte die Umgebung bereits so hell sein, dass durch das Key alleine schon ein zu schwaches Verhältnis entsteht.
Beim Verhältnis zwischen Subjekt und Hintergrund empfiehlt Ung standardmäßig 1 bis 1,5 stops Unterschied, da der Charakter sich so am natürlichsten und schönsten vom Hintergrund abhebt. Mehr oder weniger ist als kreative choice natürlich trotzdem möglich. Am besten sind die Lichter, die den Vordergrund, und jene die den Hintergrund, beleuchten daher individuell ansteuerbar, um das Verhältnis zu kontrollieren.
Außerdem ist es natürlich wichtig das blocking bereits vorher zu wissen um zu vermeiden, dass sich der Charakter in einem Shot zu einem zu hellen oder zu dunklen Hintergrund bewegt. Hilfreich ist es auch grundsätzlich nichts und niemanden nah an einer Wand zu platzieren, da es sonst kaum möglich ist, den Vordergrund alleine auszuleuchten, ohne den Hintergrund mitzunehmen.
Form
Als allerletzten Schritt empfiehlt Ung das Licht zu formen, und etwa ungewollte “light spills” zu verhindern. Dies geschieht hauptsächlich durch flags, also Stoffe die Licht blockieren, oder andere Systeme mit ähnlichem Sinn, wie barn doors etc. Beim Umgang mit flags rät Ung, mit der flag so nah wie möglich an das Subjekt ranzugehen, um so viel ausbrechendes Licht wie möglich einzufangen.
Fazit
Ich habe noch nie ein Framework gesehen, das so logisch, so unmissverständlich und so klar ist wie dieses. Erst dieses Video hat mir klar gemacht wieviel eigentlich möglich ist, wenn man leuchten kann. Wieviel davon common sense ist und welche, für eine Masterarbeit relevanteren, anderen Quellen es dafür gibt, wird in den kommenden Blogs erörtert.
Achja, und den Link zum Video bin ich euch (also eigentlich wieder nur dir Roman) auch noch schuldig:
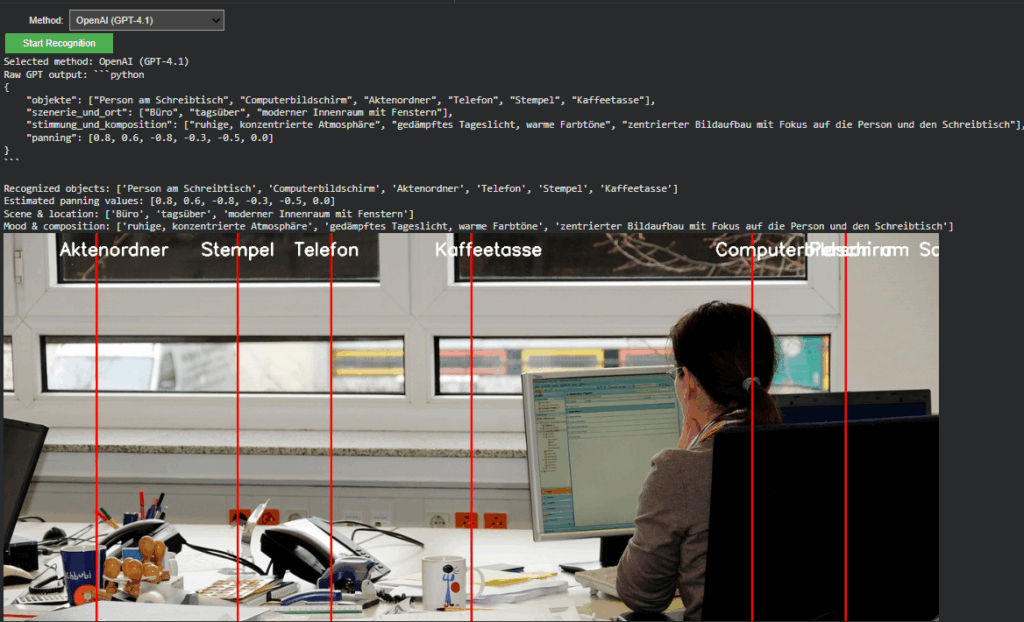
Following the foundational phase of last week, where the OpenAI API Image Analyzer established a structured evaluation framework for multimodal image analysis, the project has now reached a significant new milestone. The second release integrates both OpenAI’s GPT-4.1-based vision models and Google’s Gemini (MediaPipe) inference pipeline into a unified, adaptive system inside the Image Extender environment.
Unified Recognition Interface
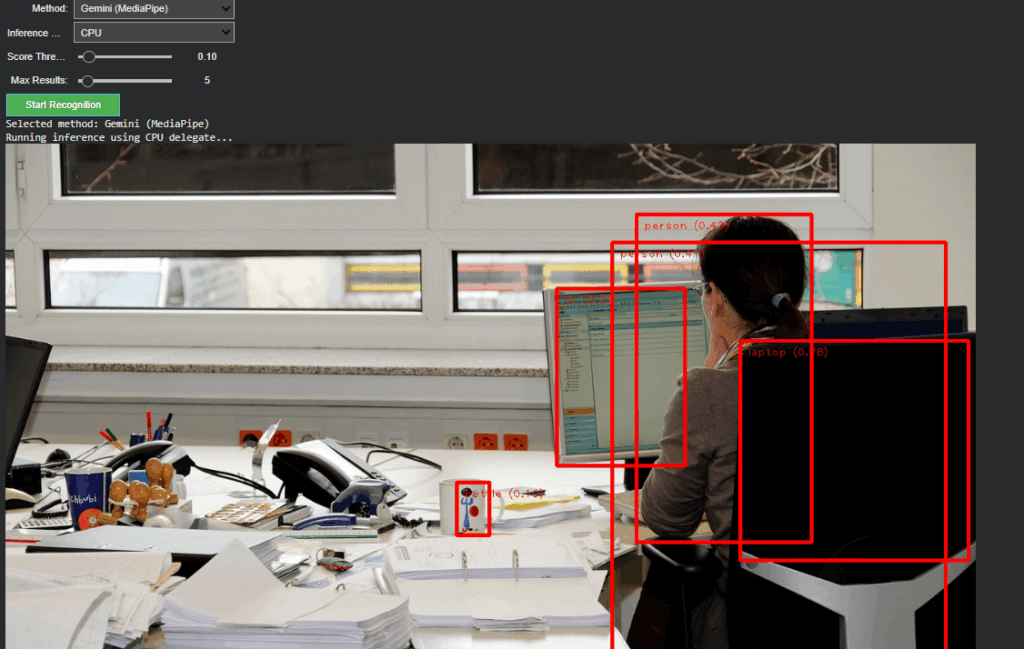
In The current version, the recognition logic has been completely refactored to support runtime model switching. A dropdown-based control in Google Colab enables instant selection between:
Gemini (MediaPipe) – for efficient, on-device object detection and panning estimation
OpenAI (GPT-4.1 / GPT-4.1-mini) – for high-level semantic and compositional interpretation
Non-relevant parameters such as score threshold or delegate type dynamically hide when OpenAI mode is active, keeping the interface clean and focused. Switching back to Gemini restores all MediaPipe-related controls. This creates a smooth dual-inference workflow where both engines can operate independently yet share the same image context and visualization logic.
Architecture Overview
The system is divided into two self-contained modules:
Image Upload Block – handles external image input and maintains a global IMAGE_FILE reference for both inference paths.
Recognition Block – manages model selection, executes inference, parses structured outputs, and handles visualization.
This modular split keeps the code reusable, reduces side effects between branches, and simplifies later expansion toward GUI-based or cloud-integrated applications.
OpenAI Integration
The OpenAI branch extends directly from Last week but now operates within the full environment. It converts uploaded images into Base64 and sends a multimodal request to gpt-4.1 or gpt-4.1-mini. The model returns a structured Python dictionary, typically using the following schema:
{
“objects”: […],
“scene_and_location”: […],
“mood_and_composition”: […],
“panning”: […]
}
A multi-stage parser (AST → JSON → fallback) ensures robustness even when GPT responses contain formatting artifacts.
Prompt Refinement
During development, testing revealed that the English prompt version initially returned empty dictionaries. Investigation showed that overly strict phrasing (“exclusively as a Python dictionary”) caused the model to suppress uncertain outputs. By softening this instruction to allow “reasonable guesses” and explicitly forbidding empty fields, the API responses became consistent and semantically rich.
Debugging the Visualization
A subtle logic bug was discovered in the visualization layer: The post-processing code still referenced German dictionary keys (“objekte”, “szenerie_und_ort”, “stimmung_und_komposition”) from Last week. Since the new English prompt returned English keys (“objects”, “scene_and_location”, etc.), these lookups produced empty lists, which in turn broke the overlay rendering loop. After harmonizing key references to support both language variants, the visualization resumed normal operation.
Cross-Model Visualization and Validation
A unified visualization layer now overlays results from either model directly onto the source image. In OpenAI mode, the “panning” values from GPT’s response are projected as vertical lines with object labels. This provides immediate visual confirmation that the model’s spatial reasoning aligns with the actual object layout, an important diagnostic step for evaluating AI-based perception accuracy.
Outcome and Next Steps
The project now represents a dual-model visual intelligence system, capable of using symbolic AI interpretation (OpenAI) and local pixel-based detection (Gemini).
Next steps
The upcoming development cycle will focus on connecting the openAI API layer directly with the Image Extender’s audio search and fallback system.
Die Ars Electronica 2025 in Linz markierte für mich ein bedeutendes persönliches und künstlerisches Erlebnis. Das Festival gilt als eines der größten und renommiertesten Medienkunstfestivals Europas und stellt einen internationalen Treffpunkt für Künstler:innen, Forscher:innen und Technolog:innen dar (Ars Electronica 2025). Für mich war es der erste Besuch und zugleich eine Rückkehr zu den Wurzeln meiner eigenen künstlerischen Entwicklung.
Eingeladen beziehungsweise ermutigt wurde ich von einer Kuratorin eines Lichtfestivals aus Bremen, die ich im Rahmen meiner Arbeit an Projektionen und Installationen kennengelernt hatte. Bemerkenswert ist, dass sich unsere Wege bereits vor zwei Jahren hätten kreuzen sollen, während meines ersten Videomappings für das X-Mass Lights Festival in Münster. Dieses Projekt war mein damaliger Einstieg in die Welt der Projektion, noch ohne tiefgehende technische Erfahrung, eher als experimenteller Versuch. Rückblickend betrachte ich diese Arbeit als ersten Lernmoment, der den Grundstein für mein heutiges Verständnis von audiovisueller Raumgestaltung legte.
Der Besuch der Ars Electronica, insbesondere der Ausstellungsbereiche im Bunker und in der ehemaligen Postgarage am Linzer Bahnhof, stellte für mich eine intensive Auseinandersetzung mit zeitgenössischer Medienkunst dar. Die gezeigten Arbeiten verbanden Technologie, Raum und Wahrnehmung auf vielschichtige Weise und erinnerten mich stark an mein erstes Studium in den Niederlanden, das ich zwischen 2007 und 2011 mit Schwerpunkt Medienkunst absolvierte. Damals begegnete ich ähnlichen künstlerischen Ansätzen im Rahmen des Festivals GOGBOT, einer Plattform für experimentelle Klang- und Medienkunst (GOGBOT 2025).
Diese Begegnung mit der Ars Electronica wurde für mich daher zu einem Reflexionsraum über Kontinuität und Wiederkehr. Nach über einem Jahrzehnt in anderen gestalterischen Feldern spürte ich deutlich, wie sich frühere Interessen und Erfahrungen nun mit meinen aktuellen Forschungsschwerpunkten verbinden ließen. Der Besuch machte mir bewusst, dass künstlerische Identität nicht linear verläuft, sondern zirkulär: Themen, die man einst zurückgelassen glaubte, kehren in neuer Form wieder, erweitert durch technische, ästhetische und persönliche Entwicklungen.
Eine zentrale Erkenntnis der Ars Electronica 2025 war für mich die Einsicht, dass künstlerische Praxis und ökonomische Realität kein Widerspruch sein müssen. Viele der ausstellenden Künstler:innen zeigten, dass es möglich ist, Medienkunst als ernsthafte berufliche und forschende Tätigkeit zu etablieren, sei es durch interdisziplinäre Kooperationen, institutionelle Förderungen oder hybride Arbeitsmodelle zwischen Kunst und Design. Diese Beobachtung stärkte in mir das Bewusstsein, dass künstlerisches Arbeiten auch im Rahmen einer professionellen Laufbahn tragfähig sein kann.
Rückblickend war die Ars Electronica 2025 somit weniger ein einmaliges Ereignis als vielmehr ein Impuls zur Selbstverortung. Sie führte mir vor Augen, wie sich meine bisherigen gestalterischen Erfahrungen, von Projektion und Sounddesign bis zur kuratorischen Zusammenarbeit, in eine übergreifende künstlerische Forschung integrieren lassen. Diese Erkenntnis prägt nun auch meine Herangehensweise an die Masterarbeit: die Verbindung von reflexiver Medienkunst, technologischer Exploration und persönlicher Narration.
Literaturverzeichnis (Chicago Author–Date)
Ars Electronica. 2025. Festival for Art, Technology and Society 2025. Linz: Ars Electronica Center. GOGBOT. 2025. https://www.gogbot.nl/ X-Mass Lights Festival. 2023. Allwetterzoo Münster
Hinweis zur Verwendung von KI-Tools
Zur sprachlichen Optimierung und für Verbesserungsvorschläge hinsichtlich Rechtschreibung, Grammatik und Ausdruck wurde ein KI-gestütztes Schreibwerkzeug (ChatGPT, OpenAI, 2025) verwendet.
Ich schreibe meine Masterarbeit über das Thema Projektionen, Mappings und Hologramme an ungewöhnlichen Orten, etwa in Kirchen oder verlassenen Räumen und darüber, wie deren kultureller und architektonischer Kontext die Wahrnehmung und Bedeutung des Kunstwerks beeinflusst.
Meine Forschung untersucht, wie vertraute Orte durch Projektionen transformiert und neu kontextualisiert werden können, sodass sie zu immersiven, emotional aufgeladenen Räumen werden. Ich plane, verschiedene Projektionstechniken an unterschiedlichen Standorten zu erproben, um deren ästhetische, räumliche und atmosphärische Wirkung zu analysieren. Der praktische Teil der Arbeit wird die Erkenntnisse und Erfahrungen der letzten drei Semester zu einem kohärenten Showcase bzw. einer Ausstellung zusammenführen, in der Theorie und künstlerische Praxis miteinander verschmelzen.
Erweiterung der Idee: von der Kirche zur Trinität der Räume
Ursprünglich sollte sich die Masterarbeit ausschließlich auf sakrale Räume konzentrieren, also auf die Wirkung von Videomapping in Kirchen oder Kapellen. Doch durch die Erfahrungen beim Klanglicht Festival 2025, bei dem ich mit verschiedenen Formaten und Raumkontexten experimentieren konnte, hat sich mein Konzept weiterentwickelt.
Statt nur einen Raumtyp zu untersuchen, möchte ich nun eine Solo-Exhibition konzipieren, die aus drei unterschiedlichen Projektionsorten besteht. Diese Orte bilden eine Art Dreifaltigkeit oder „Holy Trinity“ der Wahrnehmung, drei Pole, die jeweils einen eigenen Charakter und Symbolwert haben:
Der sakrale Raum: eine Kirche oder Kapelle, die Spiritualität, Transzendenz und kollektives Erleben repräsentiert.
Der urbane, industrielle Raum: etwa ein verlassener Keller, ein altes Firmengelände oder das Hornig-Areal in Graz, das für Transformation, Vergänglichkeit und technische Überformung steht.
Der natürliche Raum: die Landschaft oder ein Waldrand, vergleichbar mit den Arbeiten von Philipp Franke, der Projektionen in der Natur als poetische Erweiterung des Raumes versteht (Franke 2022).
Jeder dieser Orte soll eine eigene Geschichte erzählen, zugleich aber Teil eines übergeordneten Narrativs bleiben: einer Reflexion über Transformation, Wandel und Wahrnehmung.
Theoretische Grundlage – Raum, Wahrnehmung und Materialität
Die Auseinandersetzung mit Projektionen an ungewöhnlichen Orten ist eng verbunden mit Fragen der Wahrnehmungsästhetik. Maurice Merleau-Ponty beschreibt in seiner Phänomenologie der Wahrnehmung (1945), dass Raum nicht nur geometrisch, sondern leiblich erfahren wird. Diese Idee ist besonders relevant für immersive Medienkunst, da Projektionen hier nicht nur visuell wirken, sondern auch den Körper der Betrachter:innen in das Werk einbeziehen.
Auch der medientheoretische Ansatz von Giuliana Bruno (Surface: Matters of Aesthetics, Materiality, and Media, 2014) ist zentral: Sie versteht Projektion als „Haut“ oder „membrane“, die zwischen Bild, Raum und Emotion vermittelt. Diese Perspektive erlaubt es, Projektionen nicht nur als technische Lichtphänomene, sondern als räumliche Erzählungen zu begreifen, die kulturelle Bedeutungen neu verhandeln.
Auf Basis dieser theoretischen Ansätze möchte ich untersuchen, wie Materialität, etwa das projizierte Medium (Stein, Stoff, Nebel, Glas), die Atmosphäre und semantische Tiefe einer Installation beeinflusst.
Technische und ästhetische Ansätze
Für die drei Räume plane ich den Einsatz verschiedener Projektions- und Mapping-Stile:
Hologramm-Projektionen (z. B. mit Holonet oder Hologauze-Materialien) für transparente, schwebende Ebenen,
Fog-Projektionen auf Nebel oder Dunst, um ephemere, körperlose Formen zu erzeugen,
Klassische Fassaden- und Objektprojektionen für architektonische Strukturen.
Diese Techniken sollen nicht nur formal differenziert werden, sondern in ihrer räumlich-sensorischen Wirkung vergleichend untersucht werden. Ziel ist es, herauszufinden, wie unterschiedliche Medien die Wahrnehmung von Tiefe, Bewegung und Präsenz erzeugen – und inwiefern sich daraus neue Formen einer „expanded perception“ ableiten lassen.
Verbindung zu bisherigen Arbeiten
Die geplante Ausstellung knüpft an meine bisherigen Arbeiten an, die sich alle mit dem Thema Transformation auseinandersetzen:
die Partikelstrom-Animation für Markus Zimmermann,
die Fassadenprojektion für MO:YA Generate 25,
sowie meine Installation „The Dragon’s Cave“ im Schlossbergstollen, die beim Klanglicht 2025 gezeigt wurde (Klanglicht Festival 2025).
Diese drei Projekte bilden die Grundlage einer inhaltlichen Linie, die sich nun in einer forschend-künstlerischen Ausstellung fortsetzt. Sie markieren den Übergang von einzelnen Experimenten zu einem systematischen Vergleich audiovisueller Raumformate.
Persönliche Zielsetzung
Mein langfristiges Ziel ist es, den Schritt vom hauptberuflichen Mediendesigner hin zum freischaffenden Medienkünstler zu vollziehen, der audiovisuelle Installationen für öffentliche Räume realisiert. Dazu möchte ich ein starkes Portfolio aufbauen und eine klare künstlerische Argumentation entwickeln, die es mir ermöglicht, mit Städten, Sponsoren und Institutionen zusammenzuarbeiten. Zugleich soll die Masterarbeit zeigen, dass ortsbezogene Medienkunst einen relevanten Beitrag zur kulturellen Wahrnehmung leisten kann, insbesondere, wenn sie in ungewöhnlichen Kontexten entsteht, die bestehende Bedeutungsstrukturen hinterfragen.
Schlussgedanke
Die geplante Trilogie aus Kirche, Industrie und Natur versteht sich als offenes Forschungslabor für Licht, Klang und Raum. Sie soll zeigen, wie Projektion als Medium sowohl sinnlich als auch erkenntnisfördernd wirkt: als ein Werkzeug, um über das Verhältnis von Technologie, Emotion und Spiritualität nachzudenken und letztlich über die Art und Weise, wie wir Räume erleben, erinnern und transformieren.
Literaturverzeichnis (Chicago Author–Date)
Bruno, Giuliana. 2014. Surface: Matters of Aesthetics, Materiality, and Media. Chicago: University of Chicago Press. Frank, Philipp. 2025. Instagram – https://www.instagram.com/philipp.frank_/ Klanglicht Festival. 2025. Official Website. Accessed November 2025. https://www.klanglicht.at
Hinweis zur Verwendung von KI-Tools
Zur sprachlichen Optimierung, Recherche und für Verbesserungsvorschläge hinsichtlich Rechtschreibung, Grammatik und Ausdruck wurde ein KI-gestütztes Schreibwerkzeug (ChatGPT, OpenAI, 2025) verwendet.