Intelligent Sound Fallback Systems – Enhancing Audio Generation with AI-Powered Semantic Recovery
After refining Image Extender’s sound layering and spectral processing engine, this week’s development shifted focus to one of the system’s most practical yet creatively crucial challenges: ensuring that the generation process never fails silently. In previous iterations, when a detected visual object had no directly corresponding sound file in the Freesound database, the result was often an incomplete or muted soundscape. The goal of this phase was to build an intelligent fallback architecture—one capable of preserving meaning and continuity even in the absence of perfect data.
Closing the Gap Between Visual Recognition and Audio Availability
During testing, it became clear that visual recognition is often more detailed and specific than what current sound libraries can support. Object detection models might identify entities like “Golden Retriever,” “Ceramic Cup,” or “Lighthouse,” but audio datasets tend to contain more general or differently labeled entries. This mismatch created a semantic gap between what the system understands and what it can express acoustically.
The newly introduced fallback framework bridges this gap, allowing Image Extender to adapt gracefully. Instead of stopping when a sound is missing, the system now follows a set of intelligent recovery paths that preserve the intent and tone of the visual analysis while maintaining creative consistency. The result is a more resilient, contextually aware sonic generation process—one that doesn’t just survive missing data, but thrives within it.
Dual Strategy: Structured Hierarchies and AI-Powered Adaptation
Two complementary fallback strategies were introduced this week: one grounded in structured logic, and another driven by semantic intelligence.
The CSV-based fallback system builds on the ontology work from the previous phase. Using the tag_hierarchy.csv file, each sound tag is part of a parent–child chain, creating predictable fallback paths. For example, if “tiger” fails, the system ascends to “jungle,” and then “nature.” This rule-based approach guarantees reliability and zero additional computational cost, making it ideal for large-scale batch operations or offline workflows.
In contrast, the AI-powered semantic fallback uses GPT-based reasoning to dynamically generate alternative tags. When the CSV offers no viable route, the model proposes conceptually similar or thematically related categories. A specific bird species might lead to the broader concept of “bird sounds,” or an abstract object like “smartphone” could redirect to “digital notification” or “button click.” This layer of intelligence brings flexibility to unfamiliar or novel recognition results, extending the system’s creative reach beyond its predefined hierarchies.
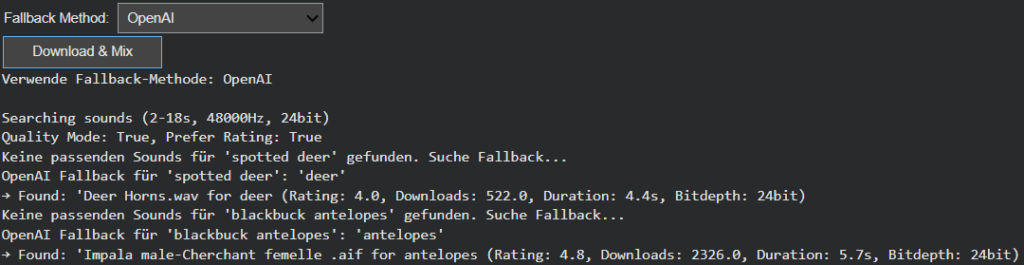
User-Controlled Adaptation
Recognizing that different projects require different balances between cost, control, and creativity, the fallback mode is now user-configurable. Through a simple dropdown menu, users can switch between CSV Mode and AI Mode.
- CSV Mode favors consistency, predictability, and cost-efficiency—perfect for common, well-defined categories.
- AI Mode prioritizes adaptability and creative expansion, ideal for complex visual inputs or unique scenes.
This configurability not only empowers users but also represents a deeper design philosophy: that AI systems should be tools for choice, not fixed solutions.
Toward Adaptive and Resilient Multimodal Systems
This week’s progress marks a pivotal evolution from static, database-bound sound generation to a hybrid model that merges structured logic with adaptive intelligence. The dual fallback system doesn’t just fill gaps, it embodies the philosophy of resilient multimodal AI, where structure and adaptability coexist in balance.
The CSV hierarchy ensures reliability, grounding the system in defined categories, while the AI layer provides flexibility and creativity, ensuring the output remains expressive even when the data isn’t. Together, they form a powerful, future-proof foundation for Image Extender’s ongoing mission: transforming visual perception into sound not as a mechanical translation, but as a living, interpretive process.