Continuing development on the Image Extender project, I’ve been exploring how to improve the connection between recognized visual elements and the sounds selected to represent them. A key question in this phase has been: How do we determine if a sound actually fits an image, not just technically but meaningfully?
Testing the Possibilities
I initially looked into using large language models to evaluate the fit between sound descriptions and the visual content of an image. Various API-based models showed potential in theory, particularly for generating a numerical score representing how well a sound matched the image content. However, many of these options required paid access or more complex setup than suited this early prototyping phase. I also explored frameworks like LangChain to help with integration, but these too proved a bit unstable for the lightweight, quick feedback loops I was aiming for.
A More Practical Approach: Semantic Comparison
To keep things moving forward, I’ve shifted toward a simpler method using semantic comparison between the image content and the sound description. In this system, the objects recognized in an image are merged into a combined tag string, which is then compared against the sound’s description using a classifier that evaluates their semantic relatedness.
Rather than returning a simple yes or no, this method provides a score that reflects how well the description aligns with the image’s content. If the score falls below a certain threshold, the sound is skipped — keeping the results focused and relevant without needing manual curation.
Why It Works (for Now)
This tag-based comparison system is easy to implement, doesn’t rely on external APIs, and integrates cleanly into the current audio selection pipeline. It allows for quick iteration, which is key during the early design and testing stages. While it doesn’t offer the nuanced understanding of a full-scale LLM, it provides a surprisingly effective filter to catch mismatches between sounds and images.
In the future, I may revisit the idea of using larger models once a more stable or affordable setup is in place. But for this phase, the focus is on building a clear and functional base — and semantic tag matching gives just enough structure to support that.
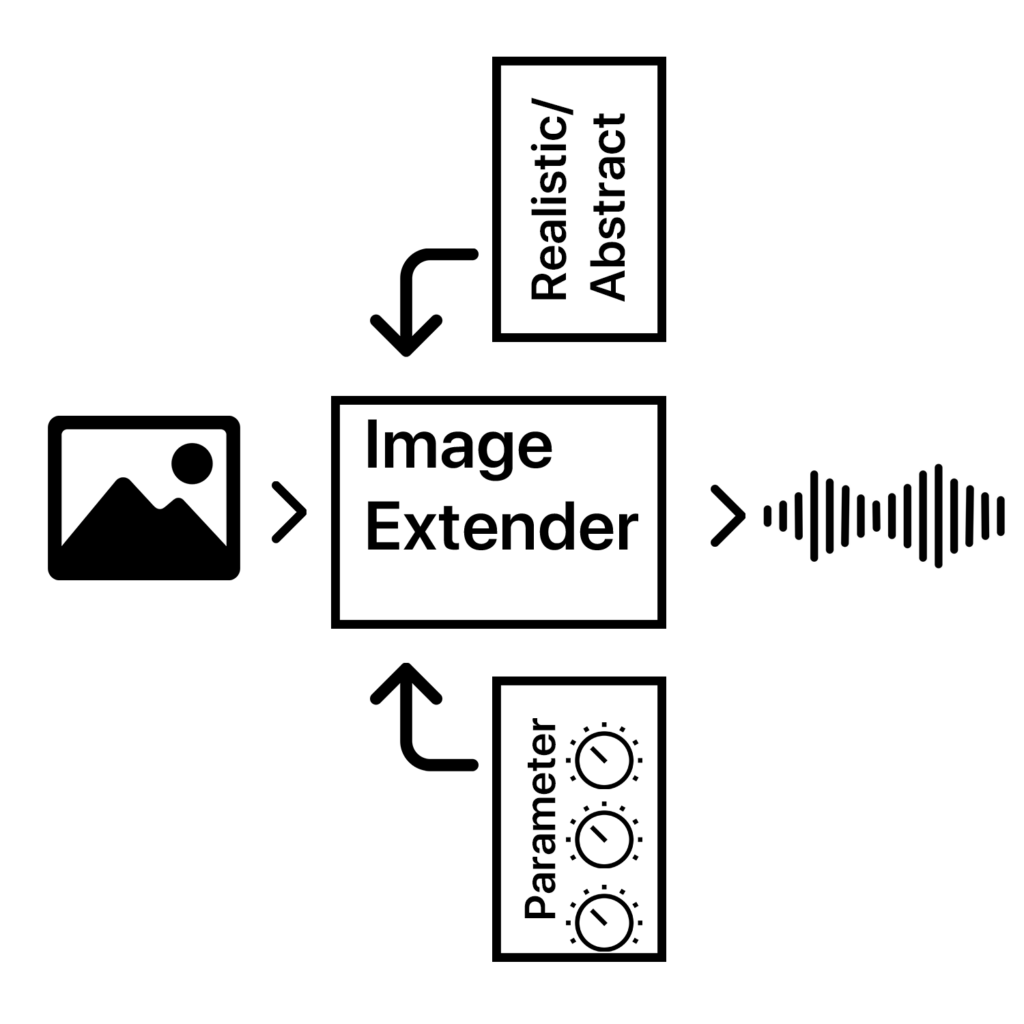
The Image Extender project bridges accessibility and creativity, offering an innovative way to perceive visual data through sound. With its dual-purpose approach, the tool has the potential to redefine auditory experiences for diverse audiences, pushing the boundaries of technology and human perception.
The project is designed as a dual-purpose tool for immersive perception and creative sound design. By leveraging AI-based image recognition and sonification algorithms, the tool will transform visual data into auditory experiences. This innovative approach is intended for:
1. Visually Impaired Individuals 2. Artists and Designers
The tool will focus on translating colors, textures, shapes, and spatial arrangements into structured soundscapes, ensuring clarity and creativity for diverse users.
Core Functionality: Translating image data into sound using sonification frameworks and AI algorithms.
Target Audiences: Visually impaired users and creative professionals.
Platforms: Initially desktop applications with planned mobile deployment for on-the-go accessibility.
User Experience: A customizable interface to balance complexity, accessibility, and creativity.
Working Hypotheses and Requirements
Hypotheses:
Cross-modal sonification enhances understanding and creativity in visual-to-auditory transformations.
Intuitive soundscapes improve accessibility for visually impaired users compared to traditional methods.
Requirements:
Develop an intuitive sonification framework adaptable to various images.
Integrate customizable settings to prevent sensory overload.
Ensure compatibility across platforms (desktop and mobile).
Subtasks
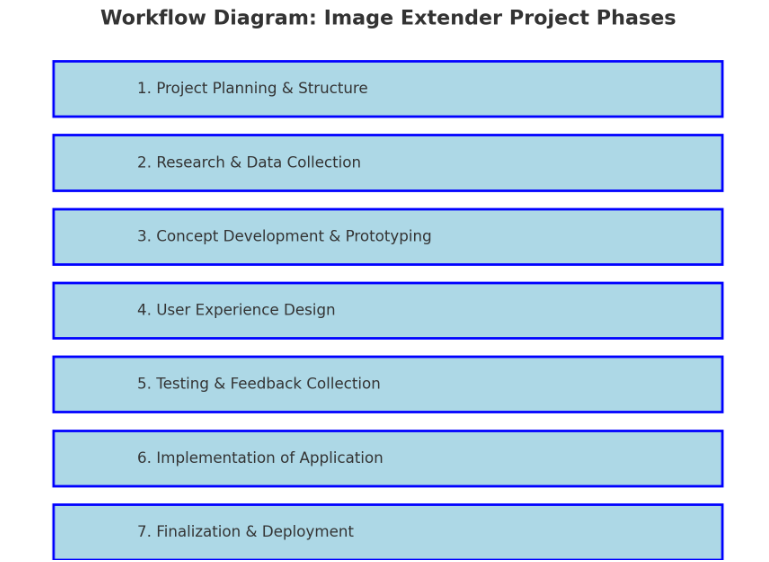
1. Project Planning & Structure
Define Scope and Goals: Clarify key deliverables and objectives for both visually impaired users and artists/designers.
Research Methods: Identify research approaches (e.g., user interviews, surveys, literature review).
Project Timeline and Milestones: Establish a phased timeline including prototyping, testing, and final implementation.
Identify Dependencies: List libraries, frameworks, and tools needed (Python, Pure Data, Max/MSP, OSC, etc.).
2. Research & Data Collection
Sonification Techniques: Research existing sonification methods and metaphors for cross-modal (sight-to-sound) mapping and research different other approaches that can also blend in the overall sonification strategy.
Psychoacoustics & Perceptual Mapping: Review how different sound frequencies, intensities, and spatialization affect perception.
Existing Tools & References: Study tools like Melobytes, VOSIS, and BeMyEyes to understand features, limitations, and user feedback.
object detection from python yolo library
3. Concept Development & Prototyping
Develop Sonification Mapping Framework: Define rules for mapping visual elements (color, shape, texture) to sound parameters (pitch, timbre, rhythm).
Simple Prototype: Create a basic prototype that integrates:
AI content recognition (Python + image processing libraries).
Sound generation (Pure Data or Max/MSP).
Communication via OSC (e.g., using Wekinator).
Create or collect Sample Soundscapes: Generate initial soundscapes for different types of images (e.g., landscapes, portraits, abstract visuals).
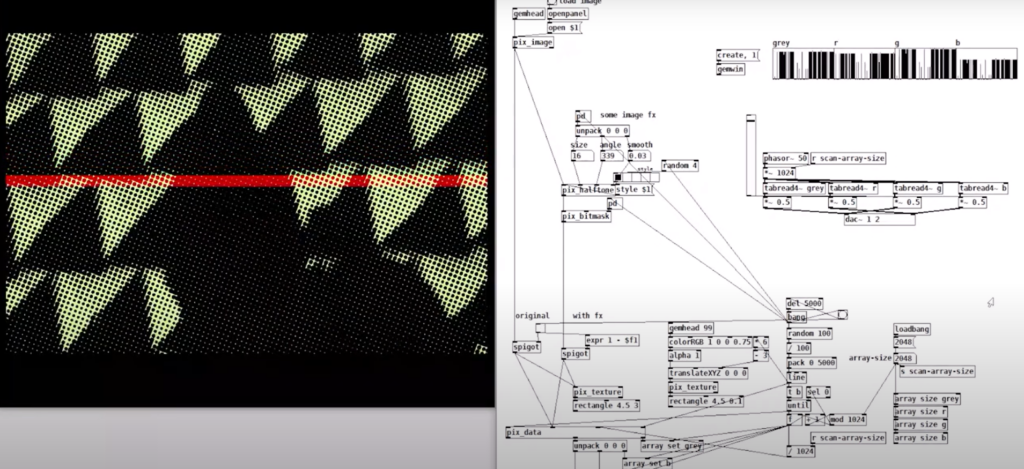
example of puredata with rem library (image to sound in pure data by Artiom Constantinov)
4. User Experience Design
UI/UX Design for Desktop:
Design intuitive interface for uploading images and adjusting sonification parameters.
Mock up controls for adjusting sound complexity, intensity, and spatialization.
Accessibility Features:
Ensure screen reader compatibility.
Develop customizable presets for different levels of user experience (basic vs. advanced).
Mobile Optimization Plan:
Plan for responsive design and functionality for smartphones.
5. Testing & Feedback Collection
Create Testing Scenarios:
Develop a set of diverse images (varying in content, color, and complexity).
Usability Testing with Visually Impaired Users:
Gather feedback on the clarity, intuitiveness, and sensory experience of the sonifications.
Identify areas of overstimulation or confusion.
Feedback from Artists/Designers:
Assess the creative flexibility and utility of the tool for sound design.
Iterate Based on Feedback:
Refine sonification mappings and interface based on user input.
6. Implementation of Standalone Application
Develop Core Application:
Integrate image recognition with sonification engine.
Implement adjustable parameters for sound generation.
Error Handling & Performance Optimization:
Ensure efficient processing for high-resolution images.
Handle edge cases for unexpected or low-quality inputs.
Cross-Platform Compatibility:
Ensure compatibility with Windows, macOS, and plan for future mobile deployment.
7. Finalization & Deployment
Finalize Feature Set:
Balance between accessibility and creative flexibility.
Ensure the sonification language is both consistent and adaptable.
Documentation & Tutorials:
Create user guides for visually impaired users and artists.
Provide tutorials for customizing sonification settings.
Deployment:
Package as a standalone desktop application.
Plan for mobile release (potentially a future phase).
Technological Basis Subtasks:
Programming: Develop core image recognition and processing modules in Python.
Sonification Engine: Create audio synthesis patches in Pure Data/Max/MSP.
Integration: Implement OSC communication between Python and the sound engine.
UI Development: Design and code the user interface for accessibility and usability.
Testing Automation: Create scripts for automating image-sonification tests.
Possible academic foundations for further research and work:
Chatterjee, Oindrila, and Shantanu Chakrabartty. “Using Growth Transform Dynamical Systems for Spatio-Temporal Data Sonification.” arXiv preprint, 2021.
Chion, Michel. Audio-Vision. New York: Columbia University Press, 1994.
Ziemer, Tim. Psychoacoustic Music Sound Field Synthesis. Cham: Springer International Publishing, 2020.
Ziemer, Tim, Nuttawut Nuchprayoon, and Holger Schultheis. “Psychoacoustic Sonification as User Interface for Human-Machine Interaction.” International Journal of Informatics Society, 2020.
Ziemer, Tim, and Holger Schultheis. “Three Orthogonal Dimensions for Psychoacoustic Sonification.” Acta Acustica United with Acustica, 2020.