New features in the object recognition and test run for images:
Since the initial freesound.org and GeminAI setup, I have added several improvements.
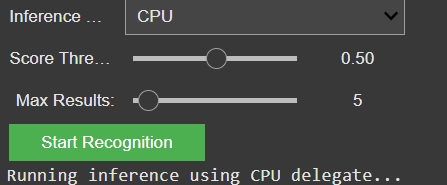
You can now choose between different object recognition models and adjust settings like the number of detected objects and the minimum confidence threshold.
I also created a detailed testing matrix, using a wide range of images to evaluate detection accuracy. Due to that there might be the change of the model later on, because it seems the gemini api only has a very basic pool of tags and is also not a good training in every category.
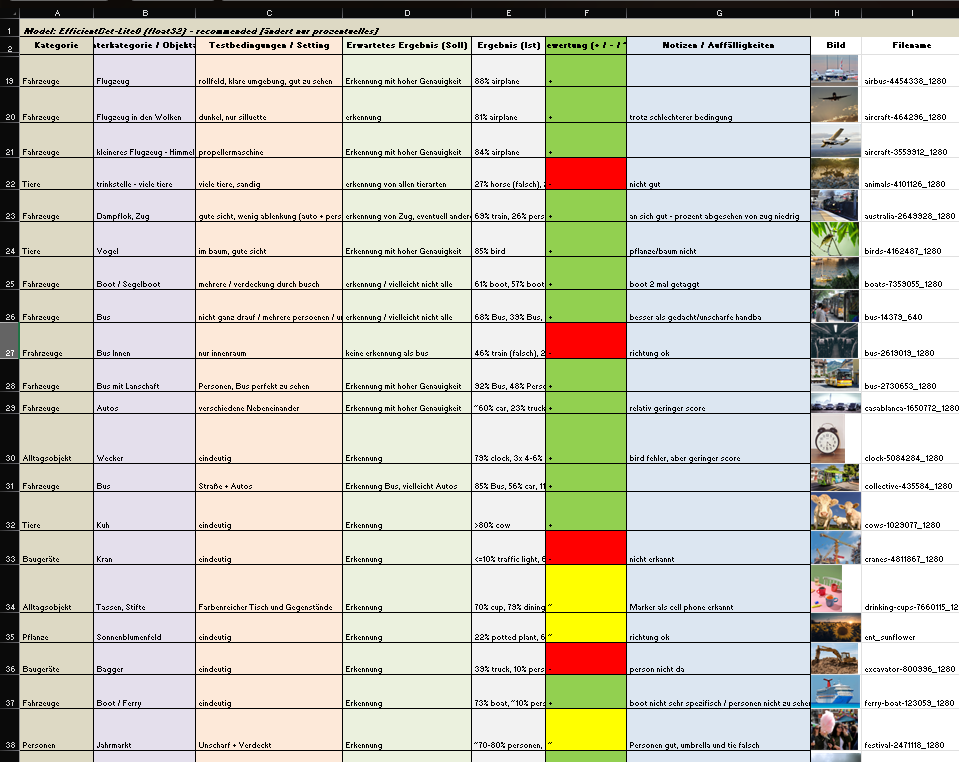
It is still reliable for these basic tags like “bird”, “car”, “tree”, etc. And for these tags it also doesn’t really matter if theres a lot of shadow, you only see half of the object or even if its blurry. But because of the lack of specific tags I will look into models or APIs that offer more fine-grained recognition.
Coming up: I’ll be working on whether to auto-play or download the selected audio files including layering sounds, adjusting volumes, experimenting with EQ and filtering — all to make the playback more natural and immersive. Also, I will think about categorization and moving the tags into a layer system. Beside that I am going to check for other object recognition models, but I might stick to the gemini api for prototyping a bit more and change the model later.



