In meinem Video-Projekt habe ich mich auf das spannende Experiment eingelassen, Künstliche Intelligenz und echte Aufnahmen miteinander zu kombinieren. Konkret habe ich diesmal eine Mischung aus KI-generiertem Footage und realem Drohnenmaterial kombiniert. Ziel war es herauszufinden, wie gut diese beiden Welten inzwischen miteinander verschmelzen können und wie sehr sie sich visuell und atmosphärisch noch voneinander unterscheiden.
Im Gegensatz zu meinen früheren Projekten (Blogpost 5), bei denen ich mit Bild-zu-Video-Tools gearbeitet habe, kam diesmal eine reine „Text zu Video“-Herangehensweise zum Einsatz. Verwendet habe ich dabei die KI-Tools Sora und Hailou.
Der Ansatz: KI-Text zu Video trifft echte Drohne
Die Idee war simpel, die Umsetzung jedoch – wie so oft – alles andere als einfach: Ich wollte ein Video erschaffen, das nahtlos zwischen echten Drohnenaufnahmen und KI-generierten Sequenzen wechselt. Dabei war es mir wichtig, das KI-Footage nicht als bloßes Füllmaterial zu verwenden, sondern bewusst Szenen zu kreieren, die thematisch und optisch zur echten Drohnenaufnahme passen.
Während ich beim letzten Mal noch auf eine Kombination aus Bildern und Prompts gesetzt habe, um die KI-Footage zu erzeugen, bestand die Herausforderung diesmal darin, ausschließlich mit Text-Prompts zu arbeiten. Das bedeutet, dass ich der KI sehr präzise Beschreibungen liefern musste, um die gewünschten Szenen zu erzeugen – ein Aspekt, der sich im Prozess als eine der größten Hürden herausstellen sollte.
Der steinige Weg zum finalen Video
Wie bei vielen KI-Projekten war auch hier der Weg zum finalen Ergebnis gepflastert mit unzähligen Fehlversuchen, Frustrationen und überraschenden Erkenntnissen. Die wohl größte Herausforderung lag darin, die richtige Balance zwischen Präzision und Offenheit in den Prompts zu finden.
Ein zu vager Prompt führte oft zu unbrauchbaren Ergebnissen, die nichts mit meiner Vorstellung zu tun hatten. Umgekehrt lieferte ein zu detaillierter Prompt zwar manchmal visuell beeindruckende Resultate, allerdings wirkte das Video dann oft künstlich und zu „glatt“, sodass es nicht mehr zum realen Drohnenmaterial passte.
Wo KI an ihre Grenzen stößt
Trotz der enormen Fortschritte in der KI-Videoerstellung bleiben gewisse Grenzen unübersehbar – gerade, wenn man echtes Footage danebenstellt. Besonders problematisch war in meinem Projekt der Bewegungsfluss:
Echte Drohnenaufnahmen haben eine organische, gleichmäßige Kameraführung, während KI-generierte Videos häufig zu ruckartigen oder „unrealistisch glatten“ Bewegungen tendieren.
Auch die Beleuchtung stellte sich als große Herausforderung heraus. Während Drohnenaufnahmen mit natürlichem Licht spielen, wirken KI-Videos oft „zu perfekt“ ausgeleuchtet oder haben unrealistische Lichtreflexe. Diese Unterschiede sorgen gerade beim direkten Schnitt zwischen den beiden Quellen für Brüche, die nur schwer zu kaschieren sind.
Hier die Best of Fails
KI-Video: Kunst, Experiment oder Täuschung?
Was mich an diesem Projekt besonders fasziniert hat: Die Übergänge zwischen KI und Realität sind mittlerweile stellenweise so subtil, dass selbst ich im Schnitt manchmal noch zweimal hinschauen musste. Dennoch bleibt ein kritischer Blick wichtig – und genau hier möchte ich im nächsten Schritt anknüpfen.
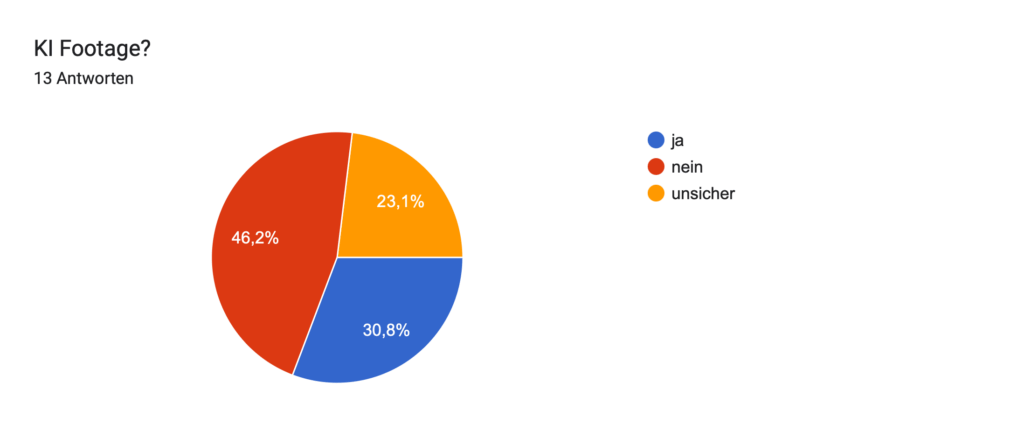
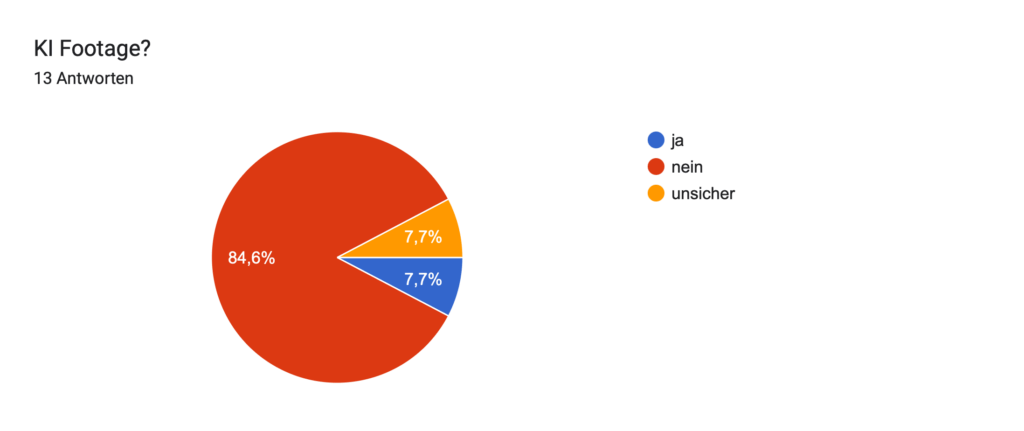
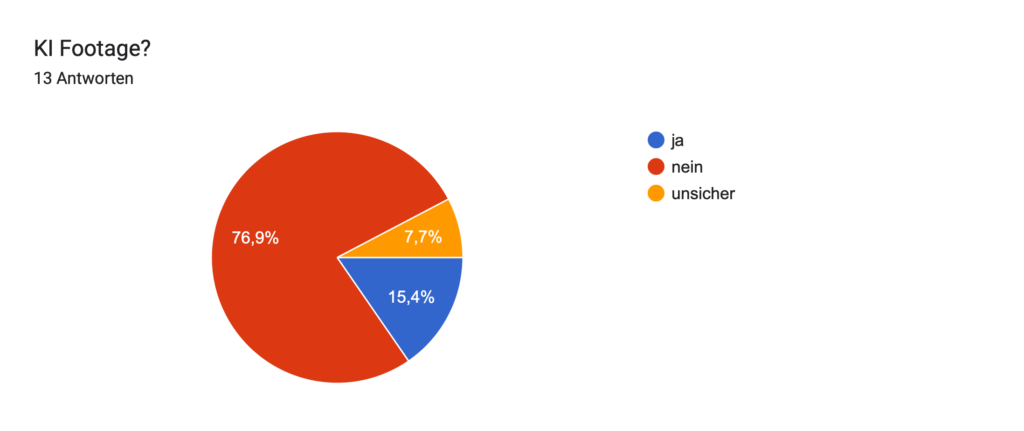
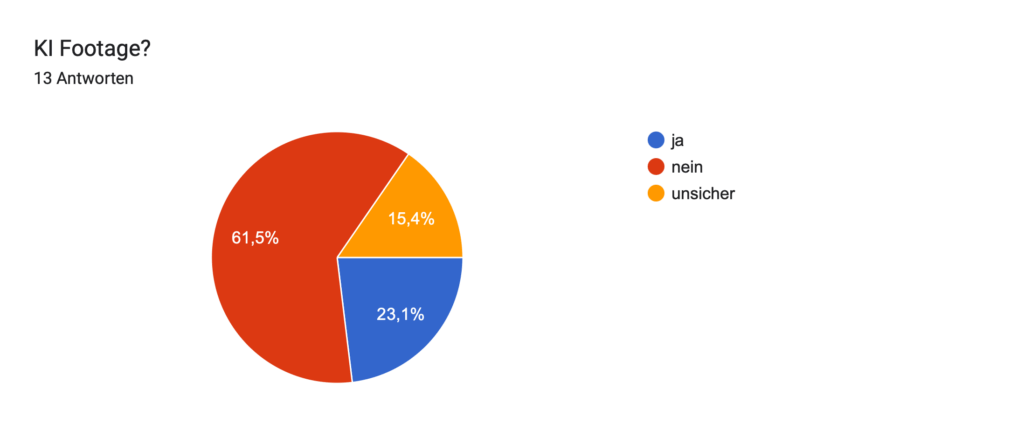
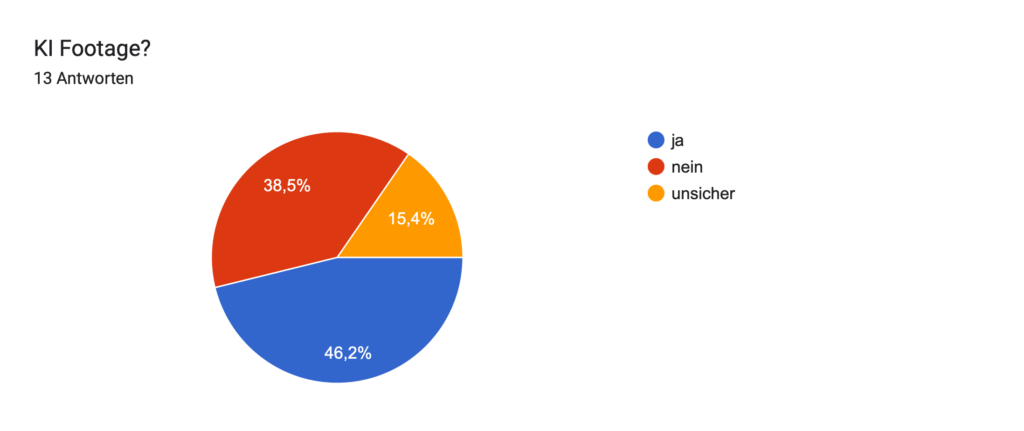
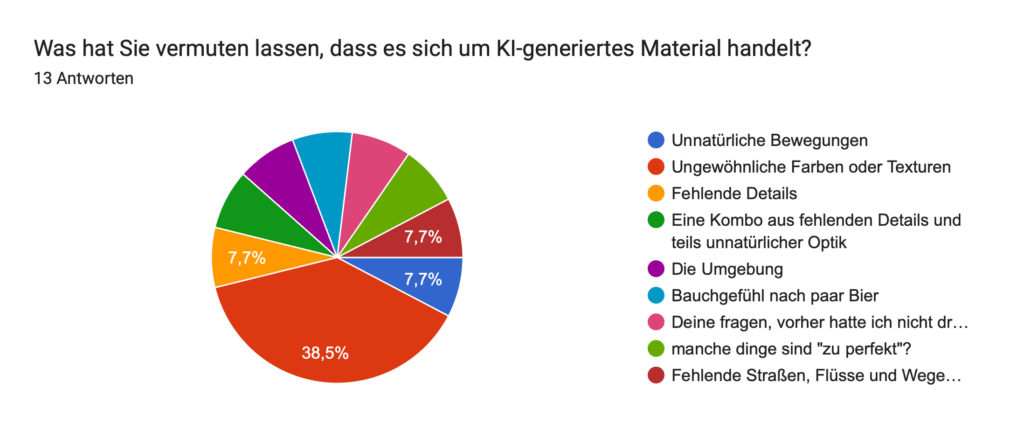
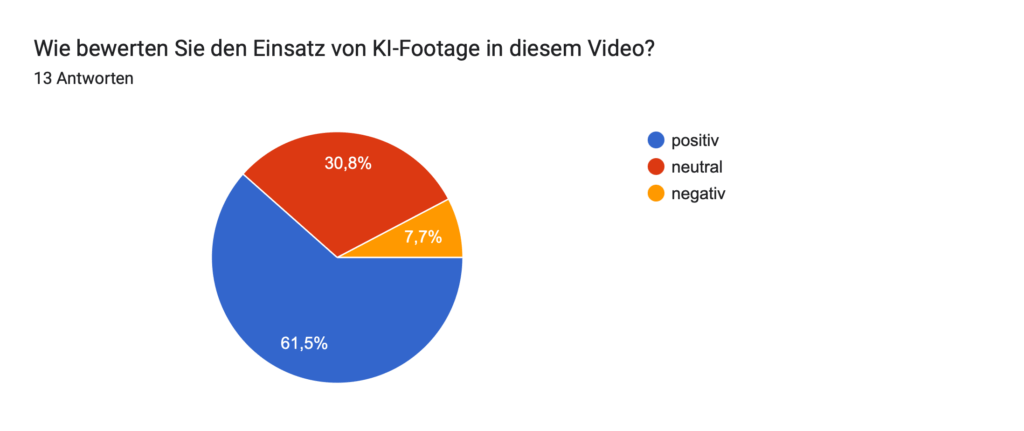
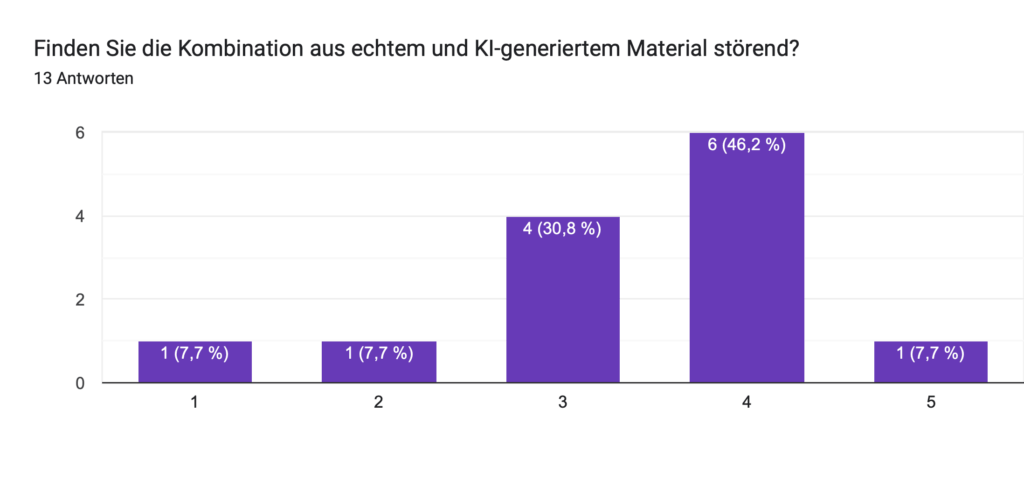
Geplant ist eine Umfrage, in der ich meinen Zuschauer:innen einzelne das Video zeige und sie raten lasse: „Ist das KI oder echt?“ Ziel dabei ist es, herauszufinden, wie gut Menschen solche Mischungen inzwischen erkennen können und gleichzeitig ein Bewusstsein für den Einfluss von KI auf Bewegtbild zu schaffen.
Fazit
Das Experiment hat mir erneut gezeigt, wie mächtig und faszinierend KI-Tools heute bereits sind aber auch, wie viel Feingefühl und Geduld notwendig sind, um wirklich überzeugende Ergebnisse zu erzielen. Ich habe unzählige Fehlversuche produziert, bevor ich am Ende ein Video in den Händen hielt, das ich guten Gewissens für dieses Projekt verwenden kann. Der spannendste Teil kommt allerdings jetzt: Die Reaktionen meiner Zuschauer:innen. Mehr dazu im nächsten Blogpost!
HIER DAS FINALE PROJEKT!