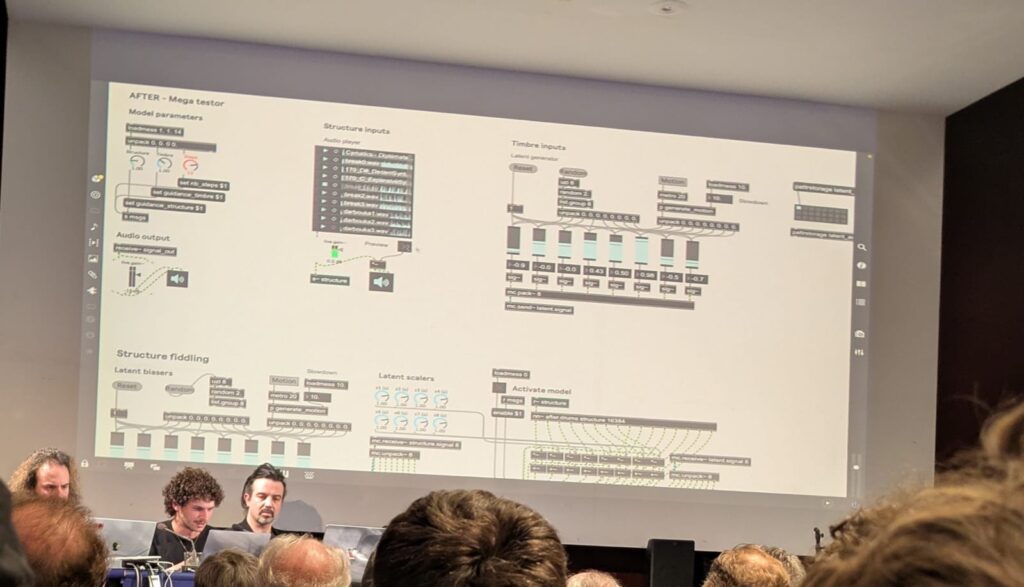
Title image: Luis Miehlich, “Cartographies – Ein Halbschlafkonzert (2023) – Pieces for Ensemble, Electronics & Video,” luismiehlich, accessed May 25, 2025, https://luismiehlich.com/.
In addition to developing the idea of a technical tool-set, I’ve started to dig a little bit deeper into the research part of my project, trying to better understand the evolving field the creative and technical work inhabits. What started as an effort to clarify the conceptual underpinnings of my practical project turned into a broader exploration of a field that is, in many ways, still defining itself: concert design.
This term may sound straightforward, but its scope is definitively not. Concert design is not just about programming a setlist or choosing a venue; it’s about crafting the entire experiential and spatial context of a performance. It treats every element of the concert, starting from basic things like the seating arrangements (or why not just laying down for example?) to interactivity, from sonic spatialization to the architecture of the space. Everything is understood as part of the creative material designers can work with.
A Field Still Taking Shape
What struck me early on is how fragmented this field still is, even though there are of course some technical resources in more specific aspects like e.g. stage lighting. But there are only a handful of academic sources that explicitly use the term concert design, understanding it as a more holistic view and even fewer that attempt to define it systematically. Among them, people like Martin Tröndle stand out for their efforts to create a structured framework through the emerging field of Concert Studies. Another name, more in the field of practical work, is Folkert Uhde.
Yet, when looking beyond academic texts, I found countless artistic projects that embody the principles of concert design even if their creators never labeled them as such. Here I want to point out the ambient scene with early experiments and even non-scientific reflections from Brian Eno up until very recent formats from Luis Miehlich for example. This suggests a noticeable gap: while practice is vibrant and evolving, theoretical reflection and shared language are still catching up.
Research Process
To navigate this space, I tried out different keywords relating disciplinary intersections; terms like “immersive performance,” “audience interaction,” “spatial dramaturgy”.
With that I found other fields that may offer interesting works, that are worth getting into:
Theater studies turned out to be a goldmine offering both practical and theoretical insights into spatial and participatory performance. There seems to be a howl tradition featuring big names like Berthold Brecht.
But what really surprised me, even though it might seem obvious, was the relevance of game design. The inherent interactive nature impacts of course the work with sound and music. The spaces were players interact with it might be of virtual nature, still the interaction of recipients with there surrounding has to be thought of during the design process. I think there might be a huge potential to examine as well, though it opens the frame to an extend that exceeds this project.
Future Steps: From Reflection to Contribution
The more I researched, the clearer it became that it is hard to just rely on existing research. A way to deal with that can be to contribute to the field as both a designer and researcher. This could be in the following ways:
- Provide an overview of the evolving field, both as a practical discipline and as an academic field. This may be a starting point.
- Reach out to leading voices in the field (e.g., Martin Tröndle, Experimental Concert Research) for interviews. This may lead to the following observations.
- Identify needs and gaps, from the perspective of practitioners and researchers: What do they lack? What could help them frame, evaluate, or communicate their work?
Ultimately, this could lead to the development of a manual or evaluation guid; something that can serve as a conceptual and practical tool for artists and designers, help them providing to the exploration performative spatial sound and the field of concert design.
From Sound Design to Concert Design
This research journey runs in parallel to my technical development of a spatial sound toolkit (→ previous blog entry), but it also stands on its own. It’s an interesting experience for me, locating my work within a broader context and trying to build some kind of bridge between my individual artistic practice and shared disciplinary structures. This might not be my future field of work, still I have the feeling, I can take this locating approach as a strategy with me and implement in future projects, to elevate them and for better communication towards outsiders.
Sources:
Martin Tröndle, ed., Das Konzert II: Beiträge zum Forschungsfeld der Concert Studies (Bielefeld: transcript Verlag, 2018), https://doi.org/10.1515/9783839443156.
“Folkert Uhde Konzertdesign,” accessed May 25, 2025, https://www.folkertuhdekonzertdesign.de/.
Brian Eno, “Ambient Music,” in Audio Culture: Readings in Modern Music, ed. Christoph Cox and Daniel Warner (New York: Continuum, 2004).
Luis Miehlich, “Cartographies – Ein Halbschlafkonzert (2023) – Pieces for Ensemble, Electronics & Video,” luismiehlich, accessed May 25, 2025, https://luismiehlich.com/.
“Re-Cartographies, by Luis Miehlich,” Bandcamp, accessed May 25, 2025, https://woolookologie.bandcamp.com/album/re-cartographies.