Continuing development on the Image Extender project, I’ve been exploring how to improve the connection between recognized visual elements and the sounds selected to represent them. A key question in this phase has been: How do we determine if a sound actually fits an image, not just technically but meaningfully?
Testing the Possibilities
I initially looked into using large language models to evaluate the fit between sound descriptions and the visual content of an image. Various API-based models showed potential in theory, particularly for generating a numerical score representing how well a sound matched the image content. However, many of these options required paid access or more complex setup than suited this early prototyping phase. I also explored frameworks like LangChain to help with integration, but these too proved a bit unstable for the lightweight, quick feedback loops I was aiming for.
A More Practical Approach: Semantic Comparison
To keep things moving forward, I’ve shifted toward a simpler method using semantic comparison between the image content and the sound description. In this system, the objects recognized in an image are merged into a combined tag string, which is then compared against the sound’s description using a classifier that evaluates their semantic relatedness.
Rather than returning a simple yes or no, this method provides a score that reflects how well the description aligns with the image’s content. If the score falls below a certain threshold, the sound is skipped — keeping the results focused and relevant without needing manual curation.
Why It Works (for Now)
This tag-based comparison system is easy to implement, doesn’t rely on external APIs, and integrates cleanly into the current audio selection pipeline. It allows for quick iteration, which is key during the early design and testing stages. While it doesn’t offer the nuanced understanding of a full-scale LLM, it provides a surprisingly effective filter to catch mismatches between sounds and images.
In the future, I may revisit the idea of using larger models once a more stable or affordable setup is in place. But for this phase, the focus is on building a clear and functional base — and semantic tag matching gives just enough structure to support that.
Tests on automated audio file search via freesound.org api:
For further use in the automated audio file search of the recognized objects I tested the freesound.org api and programmed the first interface for testing purposes. The first thing I had to do was request an API-Key by freesound.org. After that I noticed an interesting point to think about using it in my project: it is open for 5000 requests per year, but I will research on possibilities for using it more. For the testing 5000 is more than enough.
The current code already searches with a few testing tags and gives possibilities to filter the searches by samplerate, duration, licence and file type. There might be added more filter possibilities next like rating, bit depth, and maybe the possibility of random file selection so it won’t be always the same for each tag.
Next steps would also include to either download the file or just play it automatically. Then there will be tests on using the tags of the AI image recognition code for this automated search. And later in the process I have to figure out the playback of multiple files, volume staging and filtering or EQing methods for masking effects etc…
Test gui for automated sound searching via freesounds.org API
Research on sonification of images / video material and different approaches – focus on RGB
The paper by Kopecek and Ošlejšek presents a system that enables visually impaired users to perceive color images through sound using a semantic color model. Each primary color (such as red, green, or blue) is assigned a unique sound, and colors in an image are approximated by the two closest primary colors. These are represented through two simultaneous tones, with volume indicating the proportion of each color. Users can explore images by selecting pixels or regions using input devices like a touchscreen or mouse. The system calculates the average color of the selected area and plays the corresponding sounds. Distinct audio cues indicate image boundaries, and sounds can be either synthetic or instrument-based, with timbre and pitch helping to differentiate them. Users can customize colors and sounds for a more personalized experience. This approach allows for dynamic, efficient exploration of images and supports navigation via annotated SVG formats.
image seperation by Kopecek and Ošlejšek
The review by Sarkar, Bakshi, and Sa offers an overview of various image sonification methods designed to help visually impaired users interpret visual scenes through sound. It covers techniques such as raster scanning, query-based, and path-based approaches, where visual data like pixel intensity and position are mapped to auditory cues. Systems like vOICe and NAVI use high and low-frequency tones to represent image regions vertically. The paper emphasizes the importance of transfer functions, which link image properties to sound attributes such as pitch, volume, and frequency. Different rendering methods—like audification, earcons, and parameter mapping—are discussed in relation to human auditory perception. Special attention is given to color sonification, including the semantic color model introduced by Kopecek and Ošlejšek, which improves usability through clearly distinguishable tones. The paper also explores applications in fields such as medical imaging, algorithm visualization, and network analysis, and briefly touches on sound-to-image conversions.
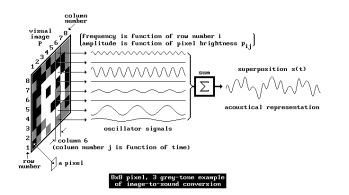
Principles of the image-to-sound mapping
Matta, Rudolph, and Kumar propose the theoretical system “Auditory Eyes,” which converts visual data into auditory and tactile signals to support blind users. The system comprises three main components: an image encoder that uses edge detection and triangulation to estimate object location and distance; a mapper that translates features like motion, brightness, and proximity into corresponding sound and vibration cues; and output generators that produce sound using tools like Csound and tactile feedback via vibrations. Motion is represented using effects like Doppler shift and interaural time difference, while spatial positioning is conveyed through head-related transfer functions. Brightness is mapped to pitch, and edges are conveyed through tone duration. The authors emphasize that combining auditory and tactile information can create a richer and more intuitive understanding of the environment, making the system potentially very useful for real-world navigation and object recognition.
References
Kopecek, Ivan, and Radek Ošlejšek. 2008. “Hybrid Approach to Sonification of Color Images.” In Third 2008 International Conference on Convergence and Hybrid Information Technology, 721–726. IEEE. https://doi.org/10.1109/ICCIT.2008.152.
Sarkar, Rajib, Sambit Bakshi, and Pankaj K Sa. 2012. “Review on Image Sonification: A Non-visual Scene Representation.” In 1st International Conference on Recent Advances in Information Technology (RAIT-2012), 1–5. IEEE. https://doi.org/10.1109/RAIT.2012.6194495.
Matta, Suresh, Heiko Rudolph, and Dinesh K Kumar. 2005. “Auditory Eyes: Representing Visual Information in Sound and Tactile Cues.” In Proceedings of the 13th European Signal Processing Conference (EUSIPCO 2005), 1–5. Antalya, Turkey. https://www.researchgate.net/publication/241256962.
Expanded research on sonification of images / video material and different approaches:
Yeo and Berger (2005) write in “A Framework for Designing Image Sonification Methods” about the challenge of mapping static, time-independent data like images into the time-dependent auditory domain. They introduce two main concepts: scanning and probing. Scanning follows a fixed, pre-determined order of sonification, whereas probing allows for arbitrary, user-controlled exploration. The paper also discusses the importance of pointers and paths in defining how data is mapped to sound. Several sonification techniques are analyzed, including inverse spectrogram mapping and the method of raster scanning (which already was explained in the Prototyping I – Blog entry), with examples illustrating their effectiveness. The authors suggest that combining scanning and probing offers a more comprehensive approach to image sonification, allowing for both global context and local feature exploration. Future work includes extending the framework to model human image perception for more intuitive sonification methods.
Time on “perpendicular” axis. (Yeo, Berger, 2005)Raster scanning method (Yeo, Berger, 2005)Pointers in different shapes: (a) single point, (b) line/curve, (c) area, and (d) set of distributed points. (Yeo, Berger, 2005)Inverse spectrogram scanning (Yeo, Berger, 2005)
Sharma et al. (2017) explore action recognition in still images using Natural Language Processing (NLP) techniques in “Action Recognition in Still Images Using Word Embeddings from Natural Language Descriptions.” Rather than training visual action detectors, they propose detecting prominent objects in an image and inferring actions based on object relationships. The Object-Verb-Object (OVO) triplet model predicts verbs using object co-occurrence, while word2vec captures semantic relationships between objects and actions. Experimental results show that this approach reliably detects actions without computationally intensive visual action detectors. The authors highlight the potential of this method in resource-constrained environments, such as mobile devices, and suggest future work incorporating spatial relationships and global scene context.
Iovino et al. (1997) discuss developments in Modalys, a physical modeling synthesizer based on modal synthesis, in “Recent Work Around Modalys and Modal Synthesis.” Modalys allows users to create virtual instruments by defining physical structures (objects), their interactions (connections), and control parameters (controllers). The authors explore the musical possibilities of Modalys, emphasizing its flexibility and the challenges of controlling complex synthesis parameters. They propose applications such as virtual instrument construction, simulation of instrumental gestures, and convergence of signal and physical modeling synthesis. The paper also introduces single-point objects, which allow for spectral control of sound, bridging the gap between signal synthesis and physical modeling. Real-time control and expressivity are emphasized, with future work focused on integrating Modalys with real-time platforms.
McGee et al. (2012) describe Voice of Sisyphus, a multimedia installation that sonifies a black-and-white image using raster scanning and frequency domain filtering in “Voice of Sisyphus: An Image Sonification Multimedia Installation.” Unlike traditional spectrograph-based sonification methods, this project focuses on probing different image regions to create a dynamic audio-visual composition. Custom software enables real-time manipulation of image regions, polyphonic sound generation, and spatialization. The installation cycles through eight phrases, each with distinct visual and auditory characteristics, creating a continuous, evolving experience. The authors discuss balancing visual and auditory aesthetics, noting that visually coherent images often produce noisy sounds, while abstract images yield clearer tones. The project draws inspiration from early experiments in image sonification and aims to create a synchronized audio-visual experience engaging viewers on multiple levels.
Software Interface for Voice of Sisyphus (McGee et al., 2012)
Roodaki et al. (2017) introduce SonifEye, a system that uses physical modeling sound synthesis to convey visual information in high-precision tasks, in “SonifEye: Sonification of Visual Information Using Physical Modeling Sound Synthesis.” They propose three sonification mechanisms: touch, pressure, and angle of approach, each mapped to sounds generated by physical models (e.g., tapping on a wooden plate or plucking a string). The system aims to reduce cognitive load and avoid alarm fatigue by using intuitive, natural sounds. Two experiments compare the effectiveness of visual, auditory, and combined feedback in high-precision tasks. Results show that auditory feedback alone can improve task performance, particularly in scenarios where visual feedback may be distracting. The authors suggest applications in medical procedures and other fields requiring precise manual tasks.
Dubus and Bresin review mapping strategies for the sonification of physical quantities in “A Systematic Review of Mapping Strategies for the Sonification of Physical Quantities.” Their study analyzes 179 publications to identify trends and best practices in sonification. The authors find that pitch is the most commonly used auditory dimension, while spatial auditory mapping is primarily applied to kinematic data. They also highlight the lack of standardized evaluation methods for sonification efficiency. The paper proposes a mapping-based framework for characterizing sonification and suggests future work in refining mapping strategies to enhance usability.
References
Yeo, Woon Seung, and Jonathan Berger. 2005. “A Framework for Designing Image Sonification Methods.” In Proceedings of ICAD 05-Eleventh Meeting of the International Conference on Auditory Display, Limerick, Ireland, July 6-9, 2005.
Sharma, Karan, Arun CS Kumar, and Suchendra M. Bhandarkar. 2017. “Action Recognition in Still Images Using Word Embeddings from Natural Language Descriptions.” In 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), 978-1-5090-4941-7/17. DOI: 10.1109/WACVW.2017.17.
Iovino, Francisco, Rene Causse, and Richard Dudas. 1997. “Recent Work Around Modalys and Modal Synthesis.” In Proceedings of the International Computer Music Conference (ICMC).
McGee, Ryan, Joshua Dickinson, and George Legrady. 2012. “Voice of Sisyphus: An Image Sonification Multimedia Installation.” In Proceedings of the 18th International Conference on Auditory Display (ICAD-2012), Atlanta, USA, June 18–22, 2012.
Roodaki, Hessam, Navid Navab, Abouzar Eslami, Christopher Stapleton, and Nassir Navab. 2017. “SonifEye: Sonification of Visual Information Using Physical Modeling Sound Synthesis.” IEEE Transactions on Visualization and Computer Graphics 23, no. 11: 2366–2371. DOI: 10.1109/TVCG.2017.2734320.
Dubus, Gaël, and Roberto Bresin. 2013. “A Systematic Review of Mapping Strategies for the Sonification of Physical Quantities.” PLoS ONE 8(12): e82491. DOI: 10.1371/journal.pone.0082491.
Shift of intention of the project due to time plan:
By narrowing down the topic to ensure the feasibility of this project the focus or main purpose of the project will be the artistic approach. The tool will still combine the use of direct image to audio translation and the translation via sonification into a more abstract form. The main use cases will be generating unique audio samples for creative applications, such as sound design for interactive installations, brand audio identities, or matching image soundscapes and the possibility to be a versatile instrument for experimental media artists and display tool for image information.
By further research on different possibilities of sonification of image data and development of the sonification language itself the translation and display purpose is going to get more clear within the following weeks.
Testing of Google Gemini API for AI Object and Image Recognition:
The first testing of the Google Gemini Api started well. There are different models for dedicated object recognition and image recognition itself which can be combined to analyze pictures in terms of objects and partly scenery. These models (SSD, EfficientNET,…) create similar results but not always the same. It might be an option to make it selectable for the user (so that in a failure case a different model can be tried and may give better results). The scenery recognition itself tends to be a problem. It may be a possibility to try out different apis.
The data we get from this AI model is a tag for the recognized objects or image content and a percentage of the probability.
The next steps for the direct translation of it into realistic sound representations will be to test the possibility of using the api of freesound.org to search directly and automated for the recognized object tags and load matching audio files. These search calls also need to filter by copyright type of the sounds and a choosing rule / algorithm needs to be created.
object recognition: efficient float 16 model (Photo by Jason Oh on unsplash)object recognition: image splice test – recognition fail (Photo by Jason Oh on unsplash)object recognition: accurate but low score (Photo: https://lernen.zoner.de/)object recognition (photo: zdf.de)
Research on sonification of images / video material and different approaches:
The world of image sonification is rich with diverse techniques, each offering unique ways to transform visual data into auditory experiences. The world of image sonification is rich with diverse techniques, each offering unique ways to map visual data into auditory experiences. One of the most straightforward methods is raster scanning, introduced by Yeo and Berger. This technique maps the brightness values of grayscale image pixels directly to audio samples, creating a one-to-one correspondence between visual and auditory data. By scanning an image line by line, from top to bottom, the system generates a sound that reflects the texture and patterns of the image. For example, a smooth gradient might produce a steady tone, while a highly textured image could result in a more complex, evolving soundscape. The process is fully reversible, allowing for both image sonification and sound visualization, making it a versatile tool for artists and researchers alike. This method is particularly effective for sonifying image textures and exploring the auditory representation of visual filters, such as “patchwork” or “grain” effects.(Yeo and Berger, 2006)
Principle raster scanning (Yeo and Berger, 2006)
In contrast, Audible Panorama (Huang et al. 2019) automates sound mapping for 360° panorama images used in virtual reality (VR). It detects objects using computer vision, estimates their depth, and assigns spatialized audio from a database. For example, a car might trigger engine sounds, while a person generates footsteps, creating an immersive auditory experience that enhances VR realism. A user study confirmed that spatial audio significantly improves the sense of presence. It contains a interesting concept regarding to choosing a random audio file from a sound library to avoid producing similar or same results. Also it mentions the aspect of postprocessing the audios which also would be a relevant aspect for the image extender project.
principle audible panorama (Huang et al. 2019)
Another approach, HindSight (Schoop, Smith, and Hartmann 2018), focuses on real-time object detection and sonification in 360° video. Using a head-mounted camera and neural networks, it detects objects like cars and pedestrians, then sonifies their position and danger level through bone conduction headphones. Beeps increase in tempo and pan to indicate proximity and direction, providing real-time safety alerts for cyclists.
Finally, Sonic Panoramas (Kabisch, Kuester, and Penny 2005) takes an interactive approach, allowing users to navigate landscape images while generating sound based on their position. Edge detection extracts features like mountains or forests, mapping them to dynamic soundscapes. For instance, a mountain ridge might produce a resonant tone, while a forest creates layered, chaotic sounds, blending visual and auditory art. It also mentions different approaches for sonification itself. For example the idea of using micro (timbre, pitch and melody) and macro level (rhythm and form) mapping.
principle sonic panoramas (Kabisch, Kuester, and Penny 2005)
Each of these methods—raster scanning, Audible Panorama, HindSight, and Sonic Panoramas—demonstrates the versatility of sonification as a tool for transforming visual data into sound and lead keeping these different approaches in mind for developing my own sonification language or mapping method. It also leads to further research by checking some useful references they used in their work for a deeper understanding of sonification and extending the possibilities.
References
Huang, Haikun, Michael Solah, Dingzeyu Li, and Lap-Fai Yu. 2019. “Audible Panorama: Automatic Spatial Audio Generation for Panorama Imagery.” In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, 1–11. Glasgow, Scotland: ACM. https://doi.org/10.1145/3290605.3300851.
Kabisch, Eric, Falko Kuester, and Simon Penny. 2005. “Sonic Panoramas: Experiments with Interactive Landscape Image Sonification.” In Proceedings of the 2005 International Conference on Artificial Reality and Telexistence (ICAT), 156–163. Christchurch, New Zealand: HIT Lab NZ.
Schoop, Eldon, James Smith, and Bjoern Hartmann. 2018. “HindSight: Enhancing Spatial Awareness by Sonifying Detected Objects in Real-Time 360-Degree Video.” In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–12. Montreal, QC, Canada: ACM. https://doi.org/10.1145/3173574.3173717.
Yeo, Woon Seung, and Jonathan Berger. 2006. “Application of Raster Scanning Method to Image Sonification, Sound Visualization, Sound Analysis and Synthesis.” In Proceedings of the 9th International Conference on Digital Audio Effects (DAFx-06), 311–316. Montreal, Canada: DAFx.