Advanced Automated Sound Mixing with Hierarchical Tag Handling and Spectral Awareness
The Image Extender project continues to evolve in scope and sophistication. What began as a relatively straightforward pipeline connecting object recognition to the Freesound.org API has now grown into a rich, semi-intelligent audio mixing system. This recent development phase focused on enhancing both the semantic accuracy and the acoustic quality of generated soundscapes, tackling two significant challenges: how to gracefully handle missing tag-to-sound matches, and how to intelligently mix overlapping sounds to avoid auditory clutter.

Sound Retrieval Meets Semantic Depth
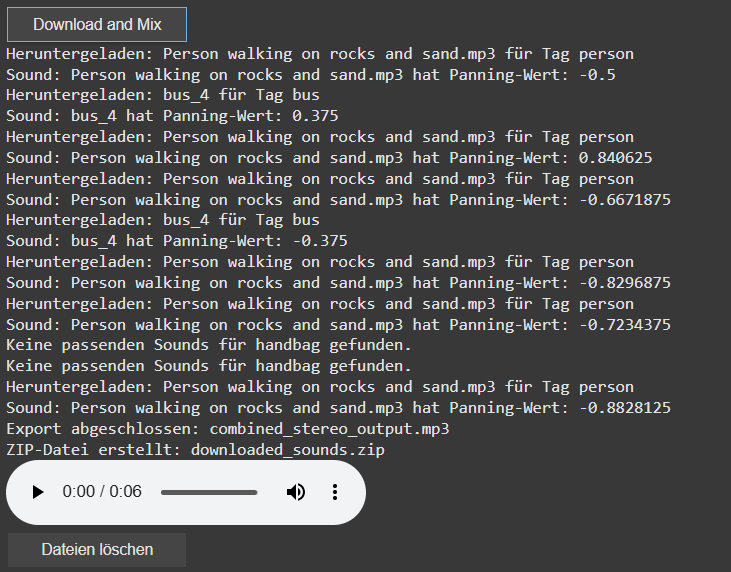
One of the core limitations of the original approach was its dependence on exact tag matches. If no sound was found for a detected object, that tag simply went silent. To address this, I introduced a multi-level fallback system based on a custom-built CSV ontology inspired by Google’s AudioSet.
This ontology now contains hundreds of entries, organized into logical hierarchies that progress from broad categories like “Entity” or “Animal” to highly specific leaf nodes like “White-tailed Deer,” “Pickup Truck,” or “Golden Eagle.” When a tag fails, the system automatically climbs upward through this tree, selecting a more general fallback—moving from “Tiger” to “Carnivore” to “Mammal,” and finally to “Animal” if necessary.
Implementation of temporal composition
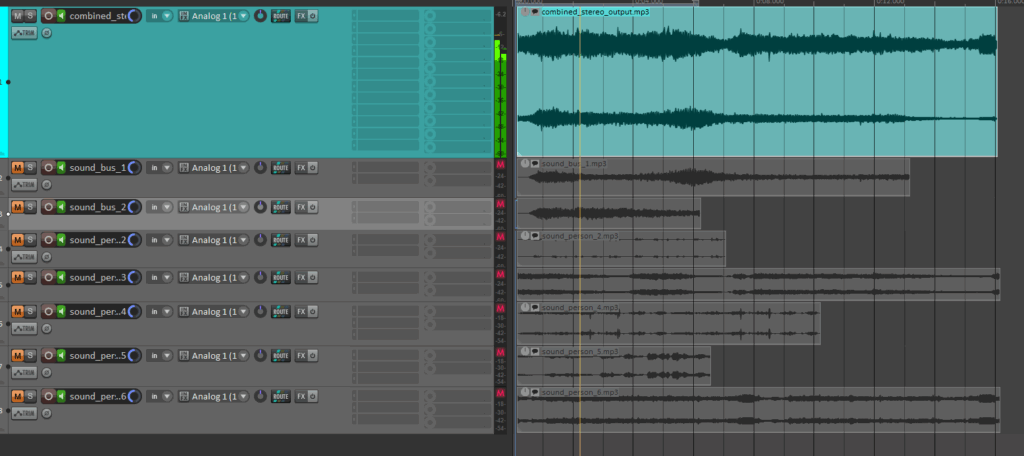
Initial versions of Image Extender merely stacked sounds on top of each other by only using the spatial composition in the form of panning. Now, the mixing system behaves more like a simplified DAW (Digital Audio Workstation). Key improvements introduced in this iteration include:
- Random temporal placement: Shorter sound files are distributed at randomized time positions across the duration of the mix, reducing sonic overcrowding and creating a more natural flow.
- Automatic fade-ins and fade-outs: Each sound is treated with short fades to eliminate abrupt onsets and offsets, improving auditory smoothness.
- Mix length based on longest sound: Instead of enforcing a fixed duration, the mix now adapts to the length of the longest inserted file, which is always placed at the beginning to anchor the composition.
These changes give each generated audio scene a sense of temporal structure and stereo space, making them more immersive and cinematic.
Frequency-Aware Mixing: Avoiding Spectral Masking
A standout feature developed during this phase was automatic spectral masking avoidance. When multiple sounds overlap in time and occupy similar frequency bands, they can mask each other, causing a loss of clarity. To mitigate this, the system performs the following steps:
- Before placing a sound, the system extracts the portion of the mix it will overlap with.
- Both the new sound and the overlapping mix segment are analyzed via FFT (Fast Fourier Transform) to determine their dominant frequency bands.
- If the analysis detects significant overlap in frequency content, the system takes one of two corrective actions:
- Attenuation: The new sound is reduced in volume (e.g., -6 dB).
- EQ filtering: Depending on the nature of the conflict, a high-pass or low-pass filter is applied to the new sound to move it out of the way spectrally.
This spectral awareness doesn’t reach the complexity of advanced mixing, but it significantly reduces the most obvious masking effects in real-time-generated content—without user input.

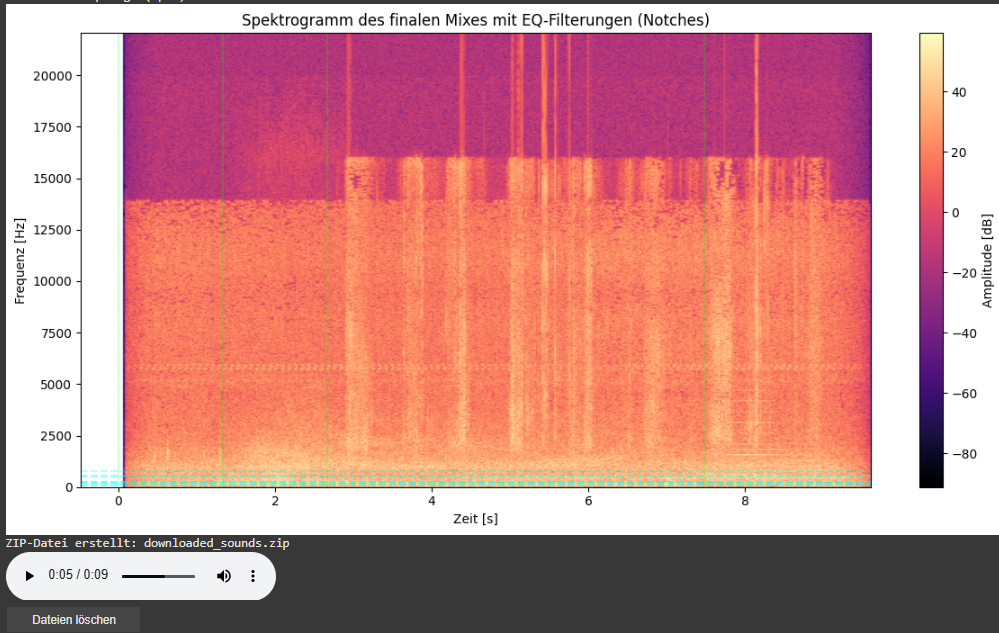
Spectrogram Visualization of the Final Mix
As part of this iteration, I also added a spectrogram visualization of the final mix. This visual feedback provides a frequency-time representation of the soundscape and highlights which parts of the spectrum have been affected by EQ filtering.
- Vertical dashed lines indicate the insertion time of each new sound.
- Horizontal lines mark the dominant frequencies of the added sound segments. These often coincide with spectral areas where notch filters have been applied to avoid collisions with the existing mix.
This visualization allows for easier debugging, improved understanding of frequency interactions, and serves as a useful tool when tuning mixing parameters or filter behaviors.
Looking Ahead
As the architecture matures, future milestones are already on the horizon. We aim to implement:
- Visual feedback: A real-time timeline that shows audio placement, duration, and spectral content.
- Advanced loudness control: Integration of dynamic range compression and LUFS-based normalization for output consistency.