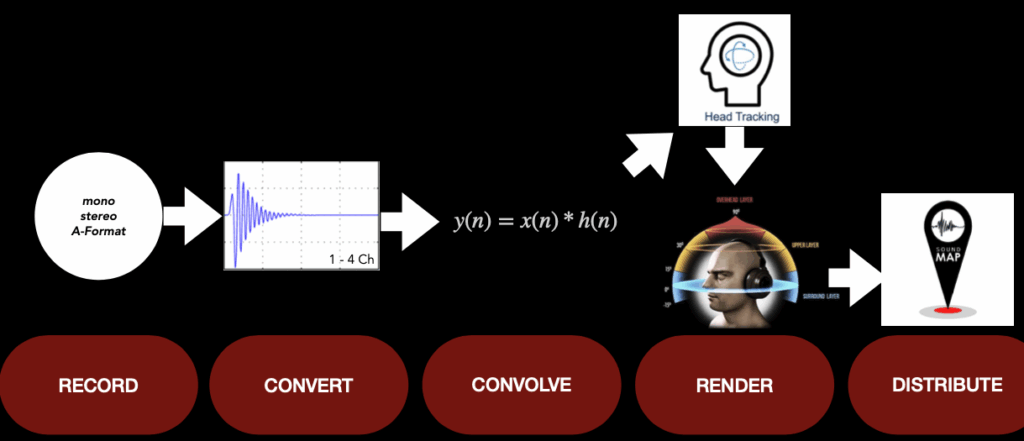
Sprachverständlichkeit im Broadcast:
Masterarbeit von Elias Thomas Weißenrieder (HdM Stuttgart, 2024)
Arbeit (https://curdt.home.hdm-stuttgart.de/PDF/Weissenrieder.pdf)
Theoretische Ausarbeitung eines Programmtools zur Sprachverständlichkeitsanalyse von Sprachsignal-Audiodateien aus dem Broadcastumfeld
Elias Thomas Weißenrieder, Master of Engineering, Hochschule der Medien Stuttgart, Studiengang: Audiovisuelle Medien.
Warum für mich interessant
Sprachverständlichkeit ist im TV-Broadcast eines der wichtigsten Forschungsfelder überhaupt. Die Arbeit entwickelt theoretisch, aber praxisnah ein Programmkonzept zur automatisierten Verständlichkeitsanalyse und prüft dafür etablierte Verfahren gegeneinander. Fokus: Was taugt im echten Broadcast-Use Case? Dazu gehören ein Versuch mit Hörtest und die Ableitung einer GUI/Workflow-Skizze für ein späteres Tool.
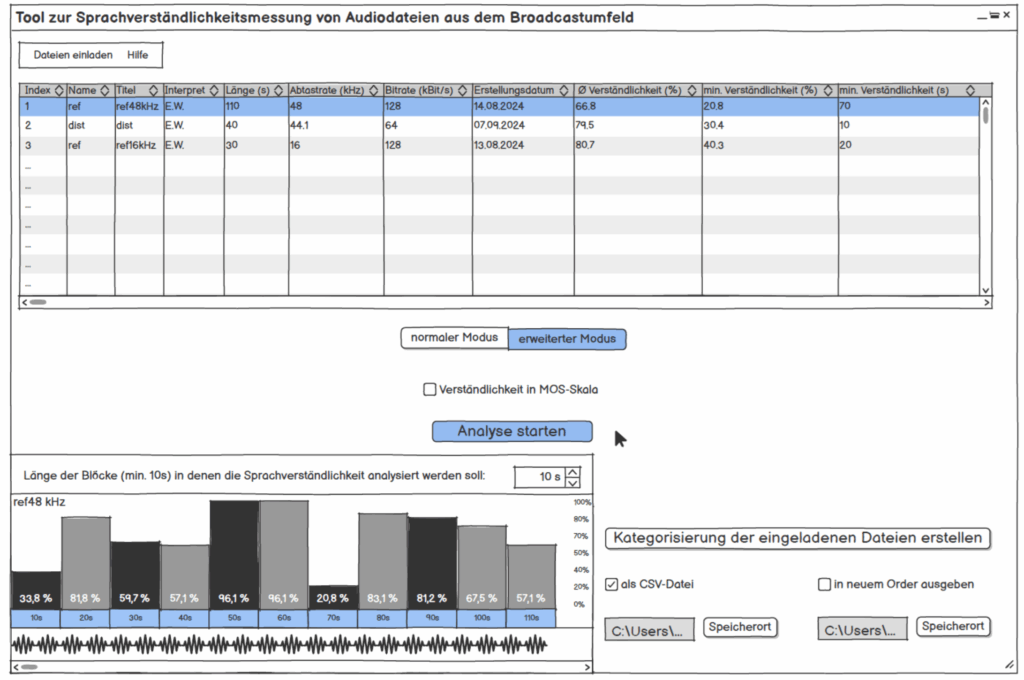
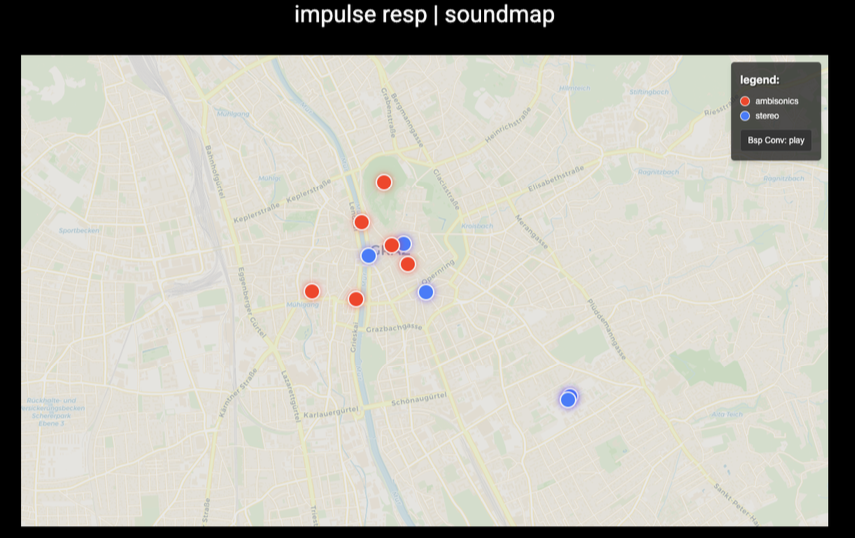
Abbildung: GUI Skizze vom entwickelten Tool
Werkstück/Dokumentation
Es gibt kein ausgeliefertes Tool, aber klar dokumentierte Bausteine: Auswahl und Implementierungswege (Python Code) für akustische Metriken der Sprachverständlichkeitsmessung STOI, PESQ und NISQA, ein Hörversuch zur Validierung, Skizzen der Oberfläche, Blockschaltbilder zweier Varianten (intrusiv mit Referenz vs. non-intrusiv), plus Nutzerinterview mit einem Broadcast-Toningenieur (13 Jahre Praxis).
Die Versuchsdaten sind typisch Broadcast: Kommentar Beyerdynamic DT797 PV über RIEDEL CCP-1116, Atmo mit SCHOEPS ORTF-3D (8 Kanäle). Aufzeichnung u. a. mit Reaper und RME MADIface USB, Routing „Direct Out“ aus LAWO; spätere Bearbeitung/Export u. a. in Nuendo 12, Loudness auf −23 LUFS normiert. Das “Werkstück” ist somit eine simulierte Stadionatmosphäre “in the Box” nachgestellt.

Abbildung: Aufbau eines ORTF 3D
1. Gestaltungshöhe
Die gestalterische Leistung liegt hier im Design eines belastbaren Mess-Workflows statt in Klangkunst. Sound Design Aspekte fanden hier dennoch seinen Platz für die Simulation für den Hörversuch. Positiv hervorzuheben ist: sauberer Use Case (Live-Kommentar im Stadion), realistische Testsignale, und eine Oberfläche, die Durchschnitts- und Worst-Block-Werte ausweist (für den schnellen Check und den gezielten Drill-down). Das ist genau der Blick, den man in der Sendezentrale braucht. Ein ästhetisches Sound-Narrativ schlüssig.
2. Innovationsgrad, Neuigkeitswert und Beitrag
Nicht neu ist, dass man die Metriken STOI/PESQ/NISQA kennt, neu ist die konsequente Einbettung in Broadcast-Praxis inkl. Hörtest-Abgleich und GUI-Konsequenzen für die Programmierung (Blockgrößen, Sortierung, Ergebnisdarstellung). Das ist ein relevanter, kleiner Schritt Richtung operationalisierbares Tool. In der Zukunft wäre eine offene Referenz-Datenbank (Audio + Ground Truth) nötig, aber für eine Masterarbeit ist der gewählte Umfang und Scope realistisch und umfangreich genug.
3. Selbstständigkeit und Eigenleistung
Die Arbeit zeigt eigenständige Entscheidungen: Versuchsdesign (auch wenn es hier Kritikpunkte von mir gibt, da ein ITU-genormtes Design nicht einghalten wurde), Auswahl und Implementierungspfade der Algorithmen, Norm-Lautheit, Testsignal-Kuratorik (z. B. keine Eigennamen, um Bias zu vermeiden). Auch das Nutzerinterview ist selbst erhoben und floss in die GUI-Anforderungen ein (z. B. einfache Tabellen-View, blockweise Detailansicht).
4. Gliederung und Struktur, Logik und Nachvollziehbarkeit
Wießenrieder hält sich klar: Grundlagen, Vergleich, Versuch, Tool-Konzept, Hypothesen-Check und alles mündet in einem Fazit mit Implementierungsvorschlag. Es kann schnell herausgefunden werden, was wo begründet ist. Für meinen Geschmack könnte der Methoden-Teil teils kompakter sein, dafür glänzen die Blockschaltbilder und die GUI-Skizzen als Orientierungsanker.
5. Kommunikationsgrad, Verständlichkeit, Ausdruck und Darstellungsweise
Die Sprache ist sachlich, gut lesbar. Wichtig für mich war Einordnung und Konsequenz, dies wird durchgezogen (z. B. MOS-Skala für Hörtest, Mapping der Verfahren). Was ich mir als Leser wünschen würde: Audio-Beispiele/QR-Links und 1-2 Plots (z. B. Block-STOI über Zeit), um die Argumente des Autors der Masterarbeit hör- und sichtbar zu machen.
6. Umfang und Angemessenheit
Umfang passt zum Ziel einer theoretische Ausarbeitung und Validierung auf einen Datensatz. Der Hörtest ist okay skaliert (MOS-Skala definiert aber abgewandelt, Setup beschrieben), Hörversuch hat zu wenig Teilnehmer, ist okay für eine Masterarbeit, limitiert aber die Generalisierbarkeit bzw. kann sich negativ auf die statistische Auswertung auswirken.
7. Orthographie, Sorgfalt & Genauigkeit, Formale Präzision
Formal sauber, konsistente Terminologie, klare Verweise. Die Lautheits-Normierung (-23dB LUFS), die Samplerate-Grenzen (PESQ-Limit bei 16 kHz) und der Export-Workflow sind präzise dokumentiert. Pluspunkt für Reproduzierbarkeit. Ein vollständiger Tech-Appendix (Kanal-Matrizen, Skript-Versionen, REAPER Session) wären vorteilhaft gewesen.
8. Literatur, Qualität, Relevanz, Vollständigkeit
Die Kernverfahren (STOI, PESQ, POLQA, NISQA, STI/SII, etc.) sind eingeführt und sinnvoll verortet. Für ein produktives Tool bräuchte es perspektivisch mehr Breite bei Non-Intrusive Methoden und Domain-Spezifika (z. B. codec-spezifische Fehlerbilder im TV-Chain). Für die gewählte Fragestellung reicht diese Auswahl aber mehr als genug aus. Alle die schonmal mit der Messung solcher akustischen Metriken arbeiteten wissen, wie aufwändig dies ist auszuwerten und zu einem Hörversuch zusammenzuschüren.
Ergebnisdiskussion und Kernresultate
Im direkten Abgleich mit dem Hörtest schneidet STOI am besten ab. PESQ liegt spürbar dahinter, NISQA weicht am stärksten ab. Unter anderem weil das Modell in diesem Setup sogar das Referenzsignal zu schlecht bewertet und dadurch die Skalierung kippt. Für Live-Kommentar und Stadion-Atmo ist STOI daher die naheliegende Wahl: Das Maß reagiert robust auf maskierende Umgebungsgeräusche; PESQ misst eher allgemeine Qualität als Verständlichkeit.
Für die Bedienung würde ich für meinen Geschmack und für die Übersichtlichkeit so aufziehen: Balkendiagramm für den schnellen Vergleich mehrerer Dateien, dazu eine Tabelle mit Gesamtwert und dem schwächsten Zeitfenster inkl. Position, für die Detailprüfung eine zeitliche Fensterung mit Wellenform. Das ist im Sendebetrieb schnell lesbar und spart Zeit.
Das Test-Setup spiegelt reale TV-Bedingungen (Headset, ORTF-3D-Atmo, -23dB LUFS, LAWO-Kette). Die Ergebnisse sind damit gut auf ähnliche Livesituationen übertragbar. Grenzen sehe ich bei anderen Störprofilen und immersiven Ausspielungen. Nächste Schritte wären für mich: nicht-intrusive Modelle gezielt mit Broadcast-Daten nachtrainieren und kanal/stem-getrennte Auswertungen prüfen, um Maskierung in komplexeren Mischungen besser zu sehen.
Stärken/Schwächen der Masterarbeit
Die Stärke von Weißenrieders Masterarbeit liegt in der praktischen Umsetzung: getestet wird mit echten Broadcast-Signalen (Kommentar gegen Stadion-Atmo), nicht mit Labor-Pink-Noise. Der Weg von Versuch zu Entscheidung ist stringent: Hörtest und Algorithmusvergleich führen nachvollziehbar zu STOI als Leitgröße, daraus folgen klare UI-/Prozess-Konsequenzen (Schnellübersicht, schwächstes Zeitfenster mit Positionsangabe, einfache Sortierung). Der Nutzerfokus wirkt echt und sendetauglich.
Schwachstellen gibt es trotzdem: Die Hörtest-Stichprobe ist offenbar klein, und das dominierende Szenario (Fußball + Kommentar) lässt offen, wie stabil die Befunde in ruhigeren Formaten wären. Die ITU Norm für den MOS Hörversuch wurde modifiziert, was die Auswertbarkeit so nicht schlüssig macht. Hörbeispiele oder Zeitverlaufs-Plots hätten die Argumente zusätzlich tragfähig gemacht.
Für meine Praxis nehme ich mit: STOI als Default, aber blockweise auswerten (nicht nur Mittelwerte). Ablauf zuerst denken: Tabelle mit Gesamt- und Minimumwert, Balkenvergleich über Files, dazu eine einfache Timeline mit Wellenform. Und Daten wie on-air kuratieren (-23dB LUFS, Headsets, reale Atmo). Perspektivisch lohnt sich der Blick auf Immersive/Stem-basierte Auswertung.
Fazit: eine fokussierte, praxistaugliche Arbeit mit echtem Mehrwert für den Sendebetrieb.