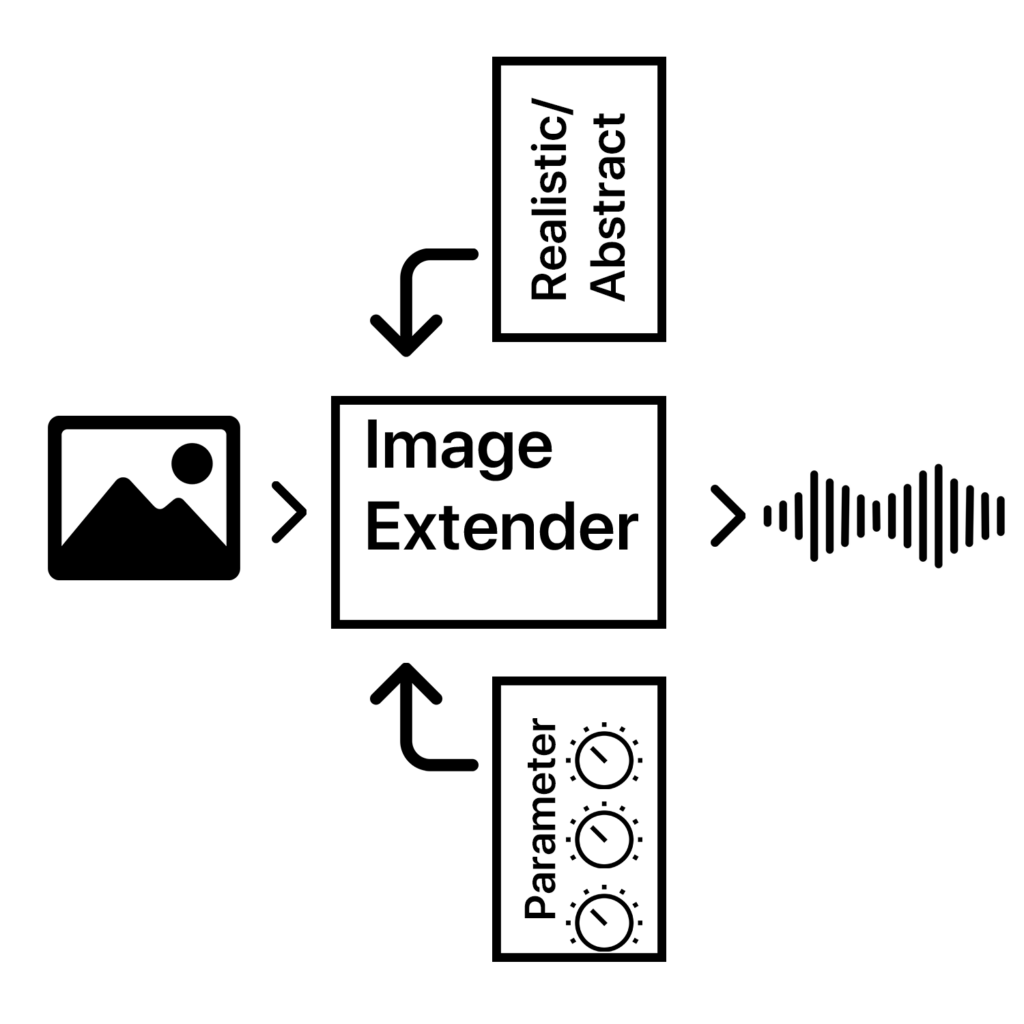
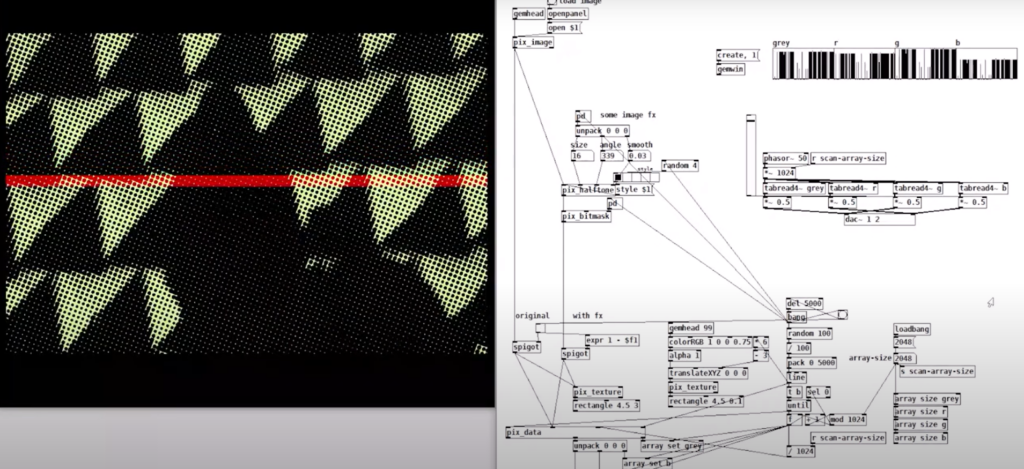
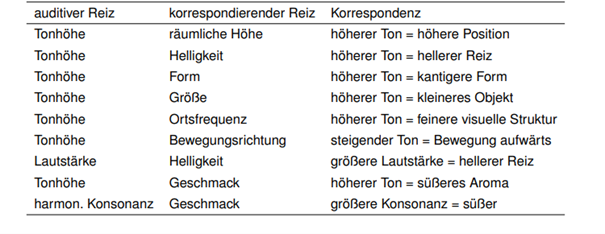
Shift of intention of the project due to time plan:
By narrowing down the topic to ensure the feasibility of this project the focus or main purpose of the project will be the artistic approach. The tool will still combine the use of direct image to audio translation and the translation via sonification into a more abstract form. The main use cases will be generating unique audio samples for creative applications, such as sound design for interactive installations, brand audio identities, or matching image soundscapes and the possibility to be a versatile instrument for experimental media artists and display tool for image information.
By further research on different possibilities of sonification of image data and development of the sonification language itself the translation and display purpose is going to get more clear within the following weeks.
Testing of Google Gemini API for AI Object and Image Recognition:
The first testing of the Google Gemini Api started well. There are different models for dedicated object recognition and image recognition itself which can be combined to analyze pictures in terms of objects and partly scenery. These models (SSD, EfficientNET,…) create similar results but not always the same. It might be an option to make it selectable for the user (so that in a failure case a different model can be tried and may give better results). The scenery recognition itself tends to be a problem. It may be a possibility to try out different apis.
The data we get from this AI model is a tag for the recognized objects or image content and a percentage of the probability.
The next steps for the direct translation of it into realistic sound representations will be to test the possibility of using the api of freesound.org to search directly and automated for the recognized object tags and load matching audio files. These search calls also need to filter by copyright type of the sounds and a choosing rule / algorithm needs to be created.




Research on sonification of images / video material and different approaches:
The world of image sonification is rich with diverse techniques, each offering unique ways to transform visual data into auditory experiences. The world of image sonification is rich with diverse techniques, each offering unique ways to map visual data into auditory experiences. One of the most straightforward methods is raster scanning, introduced by Yeo and Berger. This technique maps the brightness values of grayscale image pixels directly to audio samples, creating a one-to-one correspondence between visual and auditory data. By scanning an image line by line, from top to bottom, the system generates a sound that reflects the texture and patterns of the image. For example, a smooth gradient might produce a steady tone, while a highly textured image could result in a more complex, evolving soundscape. The process is fully reversible, allowing for both image sonification and sound visualization, making it a versatile tool for artists and researchers alike. This method is particularly effective for sonifying image textures and exploring the auditory representation of visual filters, such as “patchwork” or “grain” effects.(Yeo and Berger, 2006)

In contrast, Audible Panorama (Huang et al. 2019) automates sound mapping for 360° panorama images used in virtual reality (VR). It detects objects using computer vision, estimates their depth, and assigns spatialized audio from a database. For example, a car might trigger engine sounds, while a person generates footsteps, creating an immersive auditory experience that enhances VR realism. A user study confirmed that spatial audio significantly improves the sense of presence. It contains a interesting concept regarding to choosing a random audio file from a sound library to avoid producing similar or same results. Also it mentions the aspect of postprocessing the audios which also would be a relevant aspect for the image extender project.

Another approach, HindSight (Schoop, Smith, and Hartmann 2018), focuses on real-time object detection and sonification in 360° video. Using a head-mounted camera and neural networks, it detects objects like cars and pedestrians, then sonifies their position and danger level through bone conduction headphones. Beeps increase in tempo and pan to indicate proximity and direction, providing real-time safety alerts for cyclists.
Finally, Sonic Panoramas (Kabisch, Kuester, and Penny 2005) takes an interactive approach, allowing users to navigate landscape images while generating sound based on their position. Edge detection extracts features like mountains or forests, mapping them to dynamic soundscapes. For instance, a mountain ridge might produce a resonant tone, while a forest creates layered, chaotic sounds, blending visual and auditory art. It also mentions different approaches for sonification itself. For example the idea of using micro (timbre, pitch and melody) and macro level (rhythm and form) mapping.

Each of these methods—raster scanning, Audible Panorama, HindSight, and Sonic Panoramas—demonstrates the versatility of sonification as a tool for transforming visual data into sound and lead keeping these different approaches in mind for developing my own sonification language or mapping method. It also leads to further research by checking some useful references they used in their work for a deeper understanding of sonification and extending the possibilities.
References
Huang, Haikun, Michael Solah, Dingzeyu Li, and Lap-Fai Yu. 2019. “Audible Panorama: Automatic Spatial Audio Generation for Panorama Imagery.” In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, 1–11. Glasgow, Scotland: ACM. https://doi.org/10.1145/3290605.3300851.
Kabisch, Eric, Falko Kuester, and Simon Penny. 2005. “Sonic Panoramas: Experiments with Interactive Landscape Image Sonification.” In Proceedings of the 2005 International Conference on Artificial Reality and Telexistence (ICAT), 156–163. Christchurch, New Zealand: HIT Lab NZ.
Schoop, Eldon, James Smith, and Bjoern Hartmann. 2018. “HindSight: Enhancing Spatial Awareness by Sonifying Detected Objects in Real-Time 360-Degree Video.” In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–12. Montreal, QC, Canada: ACM. https://doi.org/10.1145/3173574.3173717.
Yeo, Woon Seung, and Jonathan Berger. 2006. “Application of Raster Scanning Method to Image Sonification, Sound Visualization, Sound Analysis and Synthesis.” In Proceedings of the 9th International Conference on Digital Audio Effects (DAFx-06), 311–316. Montreal, Canada: DAFx.