Intelligent Balancing – progress of automated mixing
This development phase introduces a sophisticated dual-layer audio processing system that addresses both proactive and reactive sound masking, creating mixes that are not only visually faithful but also acoustically optimal. Where previous systems focused on semantic accuracy and visual hierarchy, we now ensure perceptual clarity and natural soundscape balance through scientific audio principles.
The Challenge: High-Energy Sounds Dominating the Mix
During testing, we identified a critical issue: certain sounds with naturally high spectral energy (motorcycles, engines, impacts) would dominate the audio mix despite appropriate importance-based volume scaling. Even with our masking analysis and EQ correction, these sounds created an unbalanced listening experience where the mix felt “crowded” by certain elements.
Dual-Layer Solution Architecture
Layer 1: Proactive Energy-Based Gain Reduction
This new function analyzes each sound’s spectral energy across Bark bands (psychoacoustic frequency scale) and applies additional gain reduction to naturally loud sounds. The system:
- Measures average and peak energy across 24 Bark bands
- Calculates perceived loudness based on spectral distribution
- Applies up to -6dB additional reduction to high-energy sounds
- Modulates reduction based on visual importance (high importance = less reduction)
Example Application:
- Motorcycle sound: -4.5dB additional reduction (high energy in 1-4kHz range)
- Bird chirp: -1.5dB additional reduction (lower overall energy)
- Both with same visual importance, but motorcycle receives more gain reduction
Layer 2: Reactive Masking EQ (Enhanced)
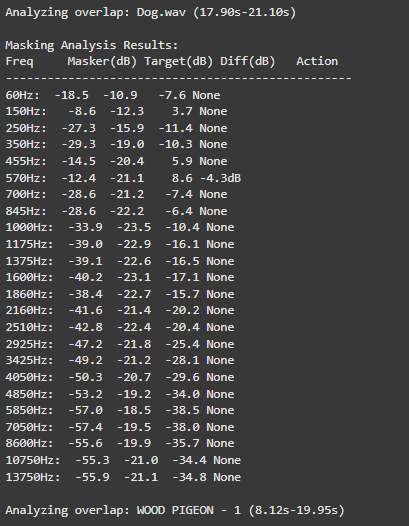
Improved Feature: Time-domain masking analysis now works with consistent positioning
We fixed a critical bug where sound positions were being randomized twice, causing:
- Overlap analysis using different positions than final placement
- EQ corrections applied to wrong temporal segments
- Inconsistent final mix compared to analysis predictions
Solution: Position consistency through saved_positions system:
- Initial random placement saved after calculation
- Same positions used for both masking analysis and final timeline
- Transparent debugging output showing exact positions used
Key Advancements
- Proactive Problem Prevention: Energy analysis occurs before mixing, preventing issues rather than fixing them
- Preserved Sound Quality: Moderate gain reduction + moderate EQ = better than extreme EQ alone
- Phase Relationship Protection: Gain reduction doesn’t affect phase like large EQ cuts do
- Mono Compatibility: Less aggressive processing improves mono downmix results
- Transparent Debugging: Complete logging shows every decision from energy analysis to final placement
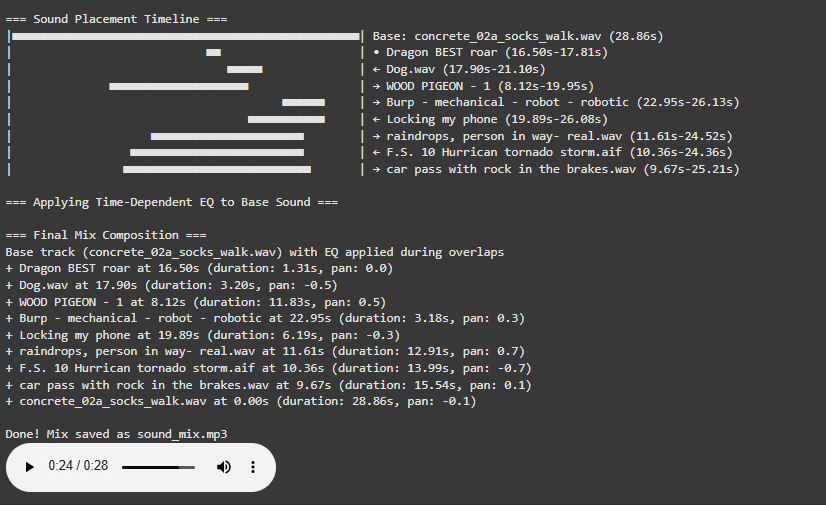
Integration with Existing System
The new energy-based system integrates seamlessly with our established pipeline:
text
Sound Download → Energy Analysis → Gain Reduction → Importance Normalization
→ Timeline Placement → Masking EQ (if needed) → Final Mix
This represents an evolution from reactive correction to intelligent anticipation, creating audio mixes that are both visually faithful and acoustically balanced. The system now understands not just what sounds should be present, but how they should coexist in the acoustic space, resulting in professional-quality soundscapes that feel natural and well-balanced to the human ear.