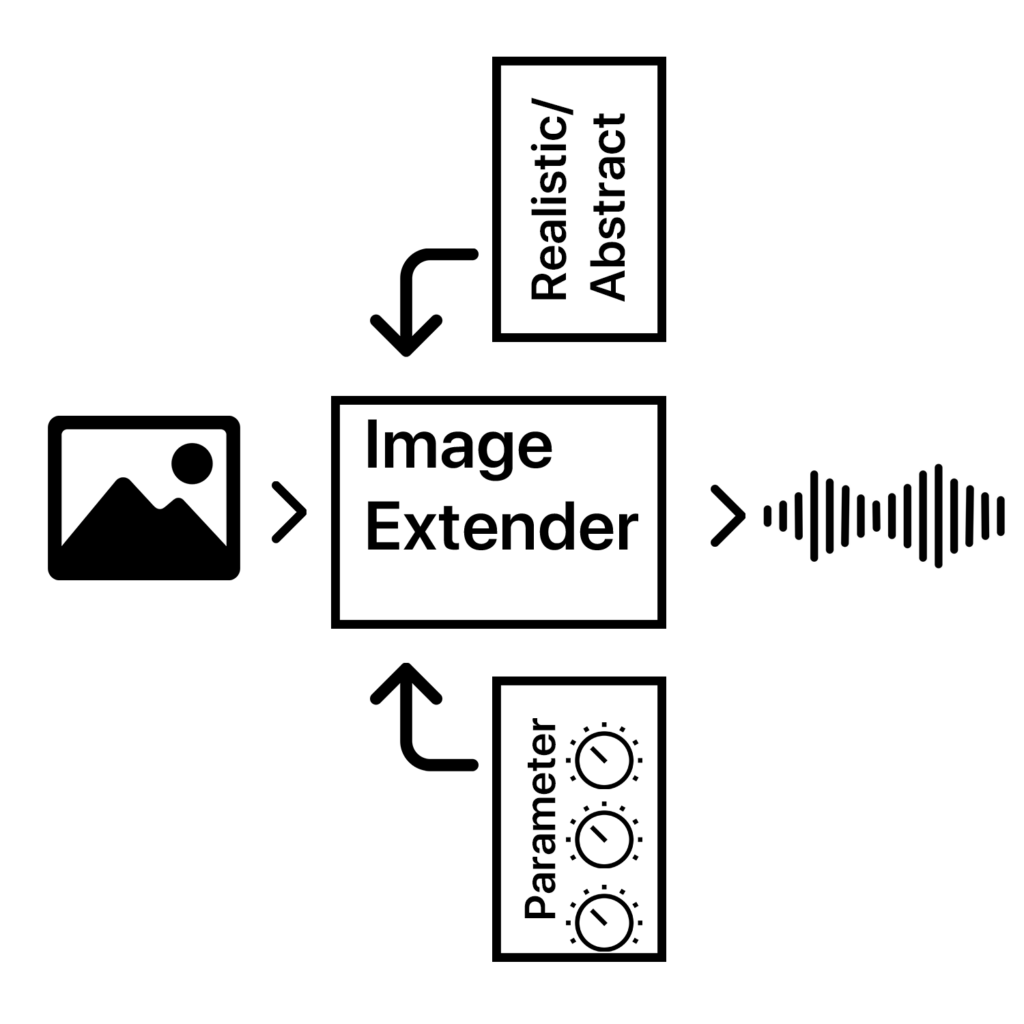
Dynamic Audio Balancing Through Visual Importance Mapping
This development phase introduces sophisticated volume control based on visual importance analysis, creating audio mixes that dynamically reflect the compositional hierarchy of the original image. Where previous systems ensured semantic accuracy, we now ensure proportional acoustic representation.
The core advancement lies in importance-based volume scaling. Each detected object’s importance value (0-1 scale from visual analysis) now directly determines its loudness level within a configurable range (-30 dBFS to -20 dBFS). Visually dominant elements receive higher volume placement, while background objects maintain subtle presence.
Key enhancements include:
– Linear importance-to-volume mapping creating natural acoustic hierarchies
The system now distinguishes between foreground emphasis and background ambiance, producing mixes where a visually central “car” (importance 0.9) sounds appropriately prominent compared to a distant “tree” (importance 0.2), while “urban street atmo” provides unwavering environmental foundation.
This represents a significant evolution from flat audio layering to dynamically balanced soundscapes that respect visual composition through intelligent volume distribution.
Sprachverständlichkeit im Broadcast: Masterarbeit von Elias Thomas Weißenrieder (HdM Stuttgart, 2024)
Arbeit (https://curdt.home.hdm-stuttgart.de/PDF/Weissenrieder.pdf)
Theoretische Ausarbeitung eines Programmtools zur Sprachverständlichkeitsanalyse von Sprachsignal-Audiodateien aus dem Broadcastumfeld Elias Thomas Weißenrieder, Master of Engineering, Hochschule der Medien Stuttgart, Studiengang: Audiovisuelle Medien.
Warum für mich interessant
Sprachverständlichkeit ist im TV-Broadcast eines der wichtigsten Forschungsfelder überhaupt. Die Arbeit entwickelt theoretisch, aber praxisnah ein Programmkonzept zur automatisierten Verständlichkeitsanalyse und prüft dafür etablierte Verfahren gegeneinander. Fokus: Was taugt im echten Broadcast-Use Case? Dazu gehören ein Versuch mit Hörtest und die Ableitung einer GUI/Workflow-Skizze für ein späteres Tool.
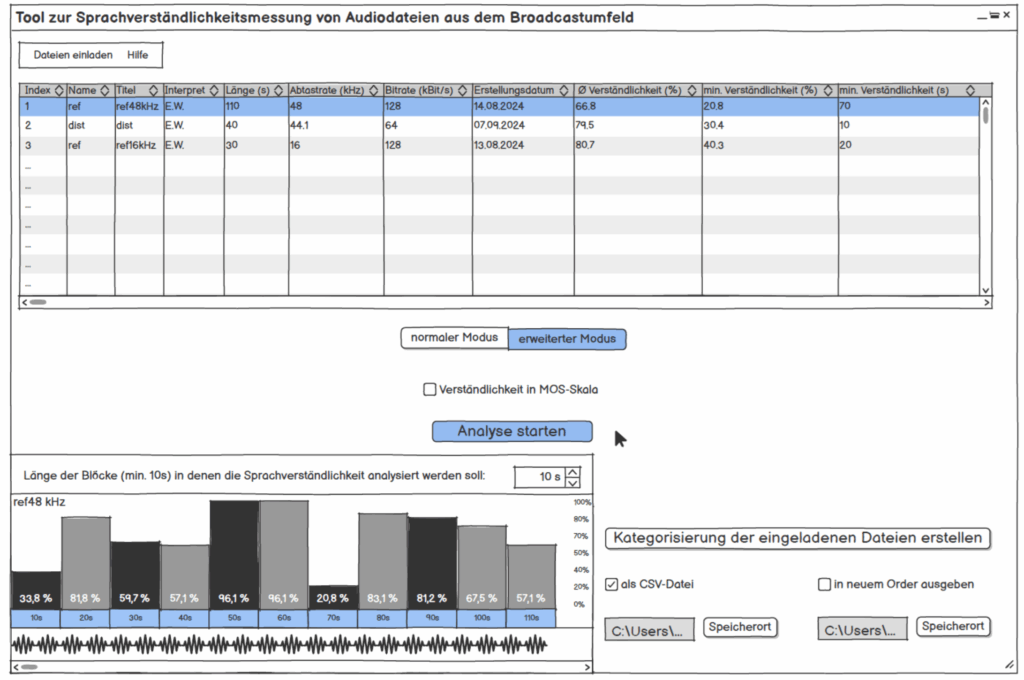
Abbildung: GUI Skizze vom entwickelten Tool
Werkstück/Dokumentation
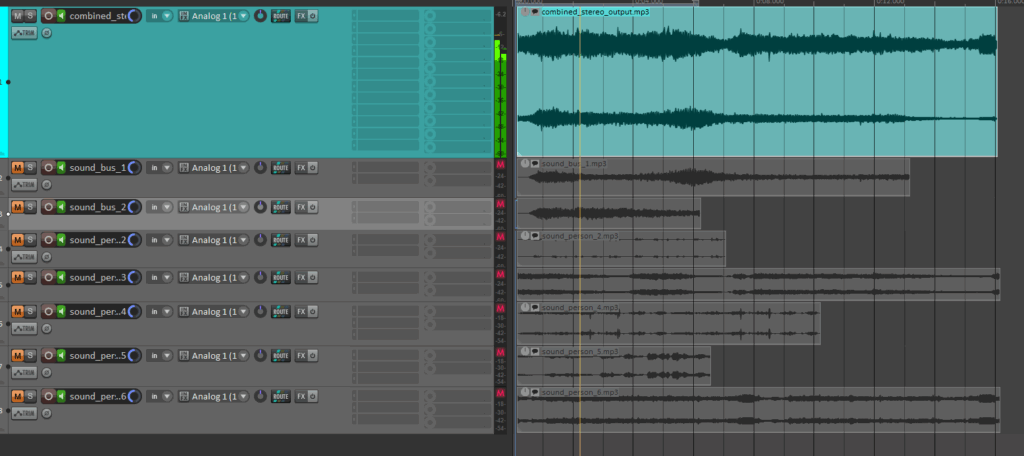
Es gibt kein ausgeliefertes Tool, aber klar dokumentierte Bausteine: Auswahl und Implementierungswege (Python Code) für akustische Metriken der Sprachverständlichkeitsmessung STOI, PESQ und NISQA, ein Hörversuch zur Validierung, Skizzen der Oberfläche, Blockschaltbilder zweier Varianten (intrusiv mit Referenz vs. non-intrusiv), plus Nutzerinterview mit einem Broadcast-Toningenieur (13 Jahre Praxis). Die Versuchsdaten sind typisch Broadcast: Kommentar Beyerdynamic DT797 PV über RIEDEL CCP-1116, Atmo mit SCHOEPS ORTF-3D (8 Kanäle). Aufzeichnung u. a. mit Reaper und RME MADIface USB, Routing „Direct Out“ aus LAWO; spätere Bearbeitung/Export u. a. in Nuendo 12, Loudness auf −23 LUFS normiert. Das “Werkstück” ist somit eine simulierte Stadionatmosphäre “in the Box” nachgestellt.
Abbildung: Aufbau eines ORTF 3D
1. Gestaltungshöhe
Die gestalterische Leistung liegt hier im Design eines belastbaren Mess-Workflows statt in Klangkunst. Sound Design Aspekte fanden hier dennoch seinen Platz für die Simulation für den Hörversuch. Positiv hervorzuheben ist: sauberer Use Case (Live-Kommentar im Stadion), realistische Testsignale, und eine Oberfläche, die Durchschnitts- und Worst-Block-Werte ausweist (für den schnellen Check und den gezielten Drill-down). Das ist genau der Blick, den man in der Sendezentrale braucht. Ein ästhetisches Sound-Narrativ schlüssig.
2. Innovationsgrad, Neuigkeitswert und Beitrag
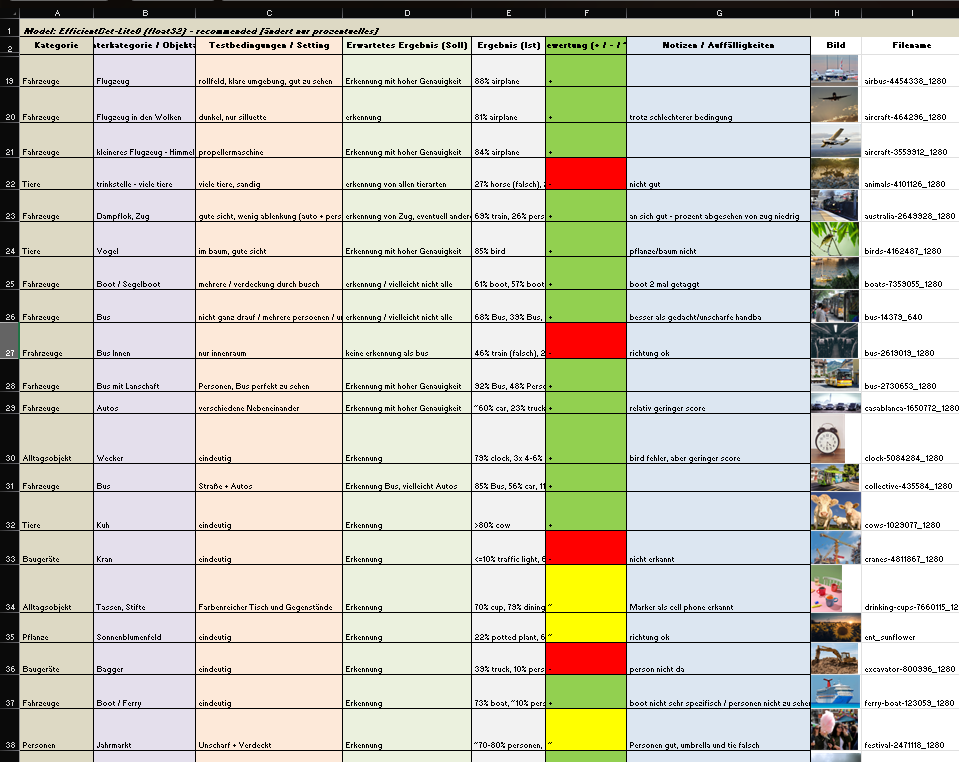
Nicht neu ist, dass man die Metriken STOI/PESQ/NISQA kennt, neu ist die konsequente Einbettung in Broadcast-Praxis inkl. Hörtest-Abgleich und GUI-Konsequenzen für die Programmierung (Blockgrößen, Sortierung, Ergebnisdarstellung). Das ist ein relevanter, kleiner Schritt Richtung operationalisierbares Tool. In der Zukunft wäre eine offene Referenz-Datenbank (Audio + Ground Truth) nötig, aber für eine Masterarbeit ist der gewählte Umfang und Scope realistisch und umfangreich genug.
3. Selbstständigkeit und Eigenleistung
Die Arbeit zeigt eigenständige Entscheidungen: Versuchsdesign (auch wenn es hier Kritikpunkte von mir gibt, da ein ITU-genormtes Design nicht einghalten wurde), Auswahl und Implementierungspfade der Algorithmen, Norm-Lautheit, Testsignal-Kuratorik (z. B. keine Eigennamen, um Bias zu vermeiden). Auch das Nutzerinterview ist selbst erhoben und floss in die GUI-Anforderungen ein (z. B. einfache Tabellen-View, blockweise Detailansicht).
4. Gliederung und Struktur, Logik und Nachvollziehbarkeit
Wießenrieder hält sich klar: Grundlagen, Vergleich, Versuch, Tool-Konzept, Hypothesen-Check und alles mündet in einem Fazit mit Implementierungsvorschlag. Es kann schnell herausgefunden werden, was wo begründet ist. Für meinen Geschmack könnte der Methoden-Teil teils kompakter sein, dafür glänzen die Blockschaltbilder und die GUI-Skizzen als Orientierungsanker.
5. Kommunikationsgrad, Verständlichkeit, Ausdruck und Darstellungsweise
Die Sprache ist sachlich, gut lesbar. Wichtig für mich war Einordnung und Konsequenz, dies wird durchgezogen (z. B. MOS-Skala für Hörtest, Mapping der Verfahren). Was ich mir als Leser wünschen würde: Audio-Beispiele/QR-Links und 1-2 Plots (z. B. Block-STOI über Zeit), um die Argumente des Autors der Masterarbeit hör- und sichtbar zu machen.
6. Umfang und Angemessenheit
Umfang passt zum Ziel einer theoretische Ausarbeitung und Validierung auf einen Datensatz. Der Hörtest ist okay skaliert (MOS-Skala definiert aber abgewandelt, Setup beschrieben), Hörversuch hat zu wenig Teilnehmer, ist okay für eine Masterarbeit, limitiert aber die Generalisierbarkeit bzw. kann sich negativ auf die statistische Auswertung auswirken.
Formal sauber, konsistente Terminologie, klare Verweise. Die Lautheits-Normierung (-23dB LUFS), die Samplerate-Grenzen (PESQ-Limit bei 16 kHz) und der Export-Workflow sind präzise dokumentiert. Pluspunkt für Reproduzierbarkeit. Ein vollständiger Tech-Appendix (Kanal-Matrizen, Skript-Versionen, REAPER Session) wären vorteilhaft gewesen.
8. Literatur, Qualität, Relevanz, Vollständigkeit
Die Kernverfahren (STOI, PESQ, POLQA, NISQA, STI/SII, etc.) sind eingeführt und sinnvoll verortet. Für ein produktives Tool bräuchte es perspektivisch mehr Breite bei Non-Intrusive Methoden und Domain-Spezifika (z. B. codec-spezifische Fehlerbilder im TV-Chain). Für die gewählte Fragestellung reicht diese Auswahl aber mehr als genug aus. Alle die schonmal mit der Messung solcher akustischen Metriken arbeiteten wissen, wie aufwändig dies ist auszuwerten und zu einem Hörversuch zusammenzuschüren.
Ergebnisdiskussion und Kernresultate
Im direkten Abgleich mit dem Hörtest schneidet STOI am besten ab. PESQ liegt spürbar dahinter, NISQA weicht am stärksten ab. Unter anderem weil das Modell in diesem Setup sogar das Referenzsignal zu schlecht bewertet und dadurch die Skalierung kippt. Für Live-Kommentar und Stadion-Atmo ist STOI daher die naheliegende Wahl: Das Maß reagiert robust auf maskierende Umgebungsgeräusche; PESQ misst eher allgemeine Qualität als Verständlichkeit.
Für die Bedienung würde ich für meinen Geschmack und für die Übersichtlichkeit so aufziehen: Balkendiagramm für den schnellen Vergleich mehrerer Dateien, dazu eine Tabelle mit Gesamtwert und dem schwächsten Zeitfenster inkl. Position, für die Detailprüfung eine zeitliche Fensterung mit Wellenform. Das ist im Sendebetrieb schnell lesbar und spart Zeit.
Das Test-Setup spiegelt reale TV-Bedingungen (Headset, ORTF-3D-Atmo, -23dB LUFS, LAWO-Kette). Die Ergebnisse sind damit gut auf ähnliche Livesituationen übertragbar. Grenzen sehe ich bei anderen Störprofilen und immersiven Ausspielungen. Nächste Schritte wären für mich: nicht-intrusive Modelle gezielt mit Broadcast-Daten nachtrainieren und kanal/stem-getrennte Auswertungen prüfen, um Maskierung in komplexeren Mischungen besser zu sehen.
Stärken/Schwächen der Masterarbeit
Die Stärke von Weißenrieders Masterarbeit liegt in der praktischen Umsetzung: getestet wird mit echten Broadcast-Signalen (Kommentar gegen Stadion-Atmo), nicht mit Labor-Pink-Noise. Der Weg von Versuch zu Entscheidung ist stringent: Hörtest und Algorithmusvergleich führen nachvollziehbar zu STOI als Leitgröße, daraus folgen klare UI-/Prozess-Konsequenzen (Schnellübersicht, schwächstes Zeitfenster mit Positionsangabe, einfache Sortierung). Der Nutzerfokus wirkt echt und sendetauglich.
Schwachstellen gibt es trotzdem: Die Hörtest-Stichprobe ist offenbar klein, und das dominierende Szenario (Fußball + Kommentar) lässt offen, wie stabil die Befunde in ruhigeren Formaten wären. Die ITU Norm für den MOS Hörversuch wurde modifiziert, was die Auswertbarkeit so nicht schlüssig macht. Hörbeispiele oder Zeitverlaufs-Plots hätten die Argumente zusätzlich tragfähig gemacht.
Für meine Praxis nehme ich mit: STOI als Default, aber blockweise auswerten (nicht nur Mittelwerte). Ablauf zuerst denken: Tabelle mit Gesamt- und Minimumwert, Balkenvergleich über Files, dazu eine einfache Timeline mit Wellenform. Und Daten wie on-air kuratieren (-23dB LUFS, Headsets, reale Atmo). Perspektivisch lohnt sich der Blick auf Immersive/Stem-basierte Auswertung. Fazit: eine fokussierte, praxistaugliche Arbeit mit echtem Mehrwert für den Sendebetrieb.
Mixing of the automatically searched audio files into one combined stereo file:
In this latest update, I’ve implemented several new features to create the first layer of an automated sound mixing system for the object recognition tool. The tool now automatically adjusts pan values and applies attenuation to ensure a balanced stereo mix, while seamlessly handling multiple tracks. This helps avoid overload and guarantees smooth audio mixing.
check of the automatically searched and downloaded files + the automatically generated combined audiofile
A key new feature is the addition of a sound_pannings array, which holds unique panning values for each sound based on the position of the object’s bounding box within an image. This ensures that each sound associated with a recognized object gets an individualized panning, calculated from its horizontal position within the image, for a more dynamic and immersive experience.
display of the sound panning values [-1 left, 1 right]
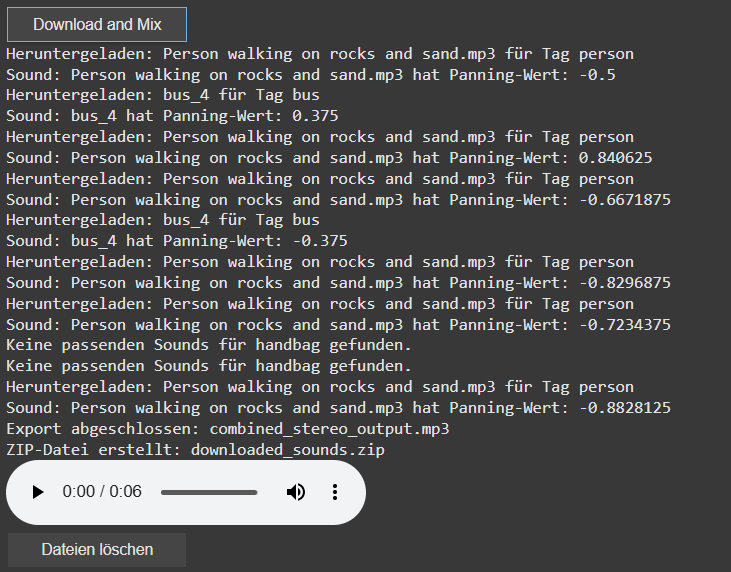
I’ve also introduced a system to automatically download sound files directly into Google Colab’s file system. This eliminates the need for managing local folders. Users can now easily preview audio within the notebook, which adds interactivity and helps visualize the results instantly.
The sound downloading process has also been revamped. The filters for the search can now be saved via a buttonclick to apply for the search and download for the audiofile. Currently for each tags there are 10 sounds per tag preloaded, with each sound randomly selected to avoid duplication but ensure the use of multiple times of the same tag. A sound is only downloaded if it hasn’t been used before. If all sound options for a tag are exhausted, no sound will be downloaded for that tag.
Additionally, I’ve added the ability to create a ZIP file that includes all the downloaded sounds as well as the final mixed audio output. This makes it easy to download and share the files. To keep things organized, I’ve also introduced a delete button that removes all downloaded files once they are no longer needed. The interface now includes buttons for controlling the download, file cleanup, and audio playback, simplifying the process for users.
Looking ahead, I plan to continue refining the system by working on better mixing techniques, focusing on aspects like spectrum, frequency, and the overall importance of the sounds. Future updates will also look at integrating volume control and more far in the future an LLM Model that can check the correctness of the found file title.
New features in the object recognition and test run for images:
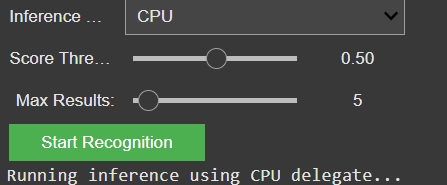
Since the initial freesound.org and GeminAI setup, I have added several improvements. You can now choose between different object recognition models and adjust settings like the number of detected objects and the minimum confidence threshold.
GUI for the settings of the model
I also created a detailed testing matrix, using a wide range of images to evaluate detection accuracy. Due to that there might be the change of the model later on, because it seems the gemini api only has a very basic pool of tags and is also not a good training in every category.
Test of images for the object recognition
It is still reliable for these basic tags like “bird”, “car”, “tree”, etc. And for these tags it also doesn’t really matter if theres a lot of shadow, you only see half of the object or even if its blurry. But because of the lack of specific tags I will look into models or APIs that offer more fine-grained recognition.
Coming up: I’ll be working on whether to auto-play or download the selected audio files including layering sounds, adjusting volumes, experimenting with EQ and filtering — all to make the playback more natural and immersive. Also, I will think about categorization and moving the tags into a layer system. Beside that I am going to check for other object recognition models, but I might stick to the gemini api for prototyping a bit more and change the model later.
Integration of AI-Object Recognition in the automated audio file search process:
After setting up the initial interface for the freesound.org API and confirming everything works with test tags and basic search filters, the next major milestone is now in motion: AI-based object recognition using the GeminAI API.
The idea is to feed in an image (or a batch of them), let the AI detect what’s in it, and then use those recognized tags to trigger an automated search for corresponding sounds on freesound.org. The integration already loads the detected tags into an array, which is then automatically passed on to the sound search. This allows the system to dynamically react to the content of an image and search for matching audio files — no manual tagging needed anymore.
So far, the detection is working pretty reliably for general categories like “bird”, “car”, “tree”, etc. But I’m looking into models or APIs that offer more fine-grained recognition. For instance, instead of just “bird”, I’d like it to say “sparrow”, “eagle”, or even specific songbird species if possible. This would make the whole sound mapping feel much more tailored and immersive.
A list of test images will be prepared, but there’s already a testing matrix for different objects, situations, scenery and technical differences
On the freesound side, I’ve got the basic query parameters set up: tag search, sample rate, file type, license, and duration filters. There’s room to expand this with additional parameters like rating, bit depth, and maybe even a random selection toggle to avoid repetition when the same tag comes up multiple times.
Coming up: I’ll be working on whether to auto-play or download the selected audio files, and starting to test how the AI-generated tags influence the mood and quality of the soundscape. The long-term plan includes layering sounds, adjusting volumes, experimenting with EQ and filtering — all to make the playback more natural and immersive.
“Listening to the Climate” : A Reflection on ClimaSynth
Climate change has become an overwhelming topic, often measured in numbers, graphs, and satellite images. But what if we could hear its effects instead? That’s the core question behind ClimaSynth, a web-based sonic interface developed by Eleni-Ira Panourgia, Bela Usabaev, and Angela Brennecke. Their paper, presented at NIME 2024, explores how environmental perception can be enhanced through real-time audio interaction, using granular synthesis to sonify future climate scenarios.
As someone researching the intersections of sound, interaction design, and environmental awareness, I found ClimaSynth to be both conceptually rich and technically compelling.
ClimaSynth isn’t just a tech demo, it’s a poetic instrument. Users interact with environmental recordings through a minimalistic web interface, manipulating sounds that morph depending on climate data and speculative futures. For instance, a serene “birds near water” recording can gradually transform into insect-heavy textures, mimicking a sonic shift tied to rising temperatures and drought. These transformations are not just aesthetic, they’re emotional cues for users to reflect on environmental degradation.
The choice to make ClimaSynth a web application is a smart one. It emphasizes accessibility, allowing anyone with a browser to engage with the experience, regardless of device or platform. This aligns beautifully with the ethos of broadening climate awareness beyond academia and into more public, participatory domains.
Another aspect I appreciated was how the team uses climate storytelling prompts in the interface. These small bits of narrative—like “trees readjusting their flexibility”—help ground the abstract sound manipulations in relatable ecological imagery. It’s a great example of how interface design can nudge user interpretation without being didactic.
Also worth highlighting is a thoughtful and often overlooked section: the ethical standards. The authors openly acknowledge the environmental cost of building web and cloud-based tools—specifically their energy demands and carbon footprint. It’s refreshing to see this kind of transparency and accountability in a digital art and research project. They even reflect on how publishing the app on GitHub (a platform supporting sustainable software practices) contributes to a more positive “handprint.” This attention to how the work is made—not just what it does—adds another layer of credibility and care to the project.
Where the Paper Left Me Wondering
While the system and concept are well-executed, I couldn’t help but feel a bit of a gap in understanding who exactly ClimaSynth is for. Is it a tool for public engagement? An artistic instrument? An educational platform? The authors mention “communicating climate change impacts,” but more clarity around the target audience or use-case scenarios could strengthen the work’s purpose.
Defining a user persona or community—whether that’s students, environmental activists, museum visitors, or musicians—might guide future iterations and also offer pathways for more impactful deployment. For example, if ClimaSynth is intended to foster awareness among high school students, it might benefit from a more guided interface or educational context. If it’s for artists, perhaps more export and remix functionality would be useful.
Similarly, I’m curious how ClimaSynth would perform in a collaborative or public setting. Could this be scaled into an installation? Could multiple users interact with it simultaneously? Could it be a live performance tool? These are all exciting possibilities that hint at ClimaSynth’s potential, but aren’t fully explored in this first prototype.
Final Thoughts
Overall, ClimaSynth is an inspiring step forward in the space where sonic interaction meets climate awareness. It reminds us that listening is a powerful way of knowing—and that sound can be both data and emotion, fact and feeling. In an age where climate anxiety often paralyzes, interactive tools like ClimaSynth offer a more intuitive, embodied way to reconnect with the world around us—and imagine what it might become.
As the project evolves, I’d love to see deeper engagement with users, clearer audience intentions, and expanded sonic possibilities. But as it stands, ClimaSynth is a meaningful addition to the growing field of eco-acoustic design.
Expanded research on sonification of images / video material and different approaches:
Yeo and Berger (2005) write in “A Framework for Designing Image Sonification Methods” about the challenge of mapping static, time-independent data like images into the time-dependent auditory domain. They introduce two main concepts: scanning and probing. Scanning follows a fixed, pre-determined order of sonification, whereas probing allows for arbitrary, user-controlled exploration. The paper also discusses the importance of pointers and paths in defining how data is mapped to sound. Several sonification techniques are analyzed, including inverse spectrogram mapping and the method of raster scanning (which already was explained in the Prototyping I – Blog entry), with examples illustrating their effectiveness. The authors suggest that combining scanning and probing offers a more comprehensive approach to image sonification, allowing for both global context and local feature exploration. Future work includes extending the framework to model human image perception for more intuitive sonification methods.
Time on “perpendicular” axis. (Yeo, Berger, 2005)Raster scanning method (Yeo, Berger, 2005)Pointers in different shapes: (a) single point, (b) line/curve, (c) area, and (d) set of distributed points. (Yeo, Berger, 2005)Inverse spectrogram scanning (Yeo, Berger, 2005)
Sharma et al. (2017) explore action recognition in still images using Natural Language Processing (NLP) techniques in “Action Recognition in Still Images Using Word Embeddings from Natural Language Descriptions.” Rather than training visual action detectors, they propose detecting prominent objects in an image and inferring actions based on object relationships. The Object-Verb-Object (OVO) triplet model predicts verbs using object co-occurrence, while word2vec captures semantic relationships between objects and actions. Experimental results show that this approach reliably detects actions without computationally intensive visual action detectors. The authors highlight the potential of this method in resource-constrained environments, such as mobile devices, and suggest future work incorporating spatial relationships and global scene context.
Iovino et al. (1997) discuss developments in Modalys, a physical modeling synthesizer based on modal synthesis, in “Recent Work Around Modalys and Modal Synthesis.” Modalys allows users to create virtual instruments by defining physical structures (objects), their interactions (connections), and control parameters (controllers). The authors explore the musical possibilities of Modalys, emphasizing its flexibility and the challenges of controlling complex synthesis parameters. They propose applications such as virtual instrument construction, simulation of instrumental gestures, and convergence of signal and physical modeling synthesis. The paper also introduces single-point objects, which allow for spectral control of sound, bridging the gap between signal synthesis and physical modeling. Real-time control and expressivity are emphasized, with future work focused on integrating Modalys with real-time platforms.
McGee et al. (2012) describe Voice of Sisyphus, a multimedia installation that sonifies a black-and-white image using raster scanning and frequency domain filtering in “Voice of Sisyphus: An Image Sonification Multimedia Installation.” Unlike traditional spectrograph-based sonification methods, this project focuses on probing different image regions to create a dynamic audio-visual composition. Custom software enables real-time manipulation of image regions, polyphonic sound generation, and spatialization. The installation cycles through eight phrases, each with distinct visual and auditory characteristics, creating a continuous, evolving experience. The authors discuss balancing visual and auditory aesthetics, noting that visually coherent images often produce noisy sounds, while abstract images yield clearer tones. The project draws inspiration from early experiments in image sonification and aims to create a synchronized audio-visual experience engaging viewers on multiple levels.
Software Interface for Voice of Sisyphus (McGee et al., 2012)
Roodaki et al. (2017) introduce SonifEye, a system that uses physical modeling sound synthesis to convey visual information in high-precision tasks, in “SonifEye: Sonification of Visual Information Using Physical Modeling Sound Synthesis.” They propose three sonification mechanisms: touch, pressure, and angle of approach, each mapped to sounds generated by physical models (e.g., tapping on a wooden plate or plucking a string). The system aims to reduce cognitive load and avoid alarm fatigue by using intuitive, natural sounds. Two experiments compare the effectiveness of visual, auditory, and combined feedback in high-precision tasks. Results show that auditory feedback alone can improve task performance, particularly in scenarios where visual feedback may be distracting. The authors suggest applications in medical procedures and other fields requiring precise manual tasks.
Dubus and Bresin review mapping strategies for the sonification of physical quantities in “A Systematic Review of Mapping Strategies for the Sonification of Physical Quantities.” Their study analyzes 179 publications to identify trends and best practices in sonification. The authors find that pitch is the most commonly used auditory dimension, while spatial auditory mapping is primarily applied to kinematic data. They also highlight the lack of standardized evaluation methods for sonification efficiency. The paper proposes a mapping-based framework for characterizing sonification and suggests future work in refining mapping strategies to enhance usability.
References
Yeo, Woon Seung, and Jonathan Berger. 2005. “A Framework for Designing Image Sonification Methods.” In Proceedings of ICAD 05-Eleventh Meeting of the International Conference on Auditory Display, Limerick, Ireland, July 6-9, 2005.
Sharma, Karan, Arun CS Kumar, and Suchendra M. Bhandarkar. 2017. “Action Recognition in Still Images Using Word Embeddings from Natural Language Descriptions.” In 2017 IEEE Winter Conference on Applications of Computer Vision (WACV), 978-1-5090-4941-7/17. DOI: 10.1109/WACVW.2017.17.
Iovino, Francisco, Rene Causse, and Richard Dudas. 1997. “Recent Work Around Modalys and Modal Synthesis.” In Proceedings of the International Computer Music Conference (ICMC).
McGee, Ryan, Joshua Dickinson, and George Legrady. 2012. “Voice of Sisyphus: An Image Sonification Multimedia Installation.” In Proceedings of the 18th International Conference on Auditory Display (ICAD-2012), Atlanta, USA, June 18–22, 2012.
Roodaki, Hessam, Navid Navab, Abouzar Eslami, Christopher Stapleton, and Nassir Navab. 2017. “SonifEye: Sonification of Visual Information Using Physical Modeling Sound Synthesis.” IEEE Transactions on Visualization and Computer Graphics 23, no. 11: 2366–2371. DOI: 10.1109/TVCG.2017.2734320.
Dubus, Gaël, and Roberto Bresin. 2013. “A Systematic Review of Mapping Strategies for the Sonification of Physical Quantities.” PLoS ONE 8(12): e82491. DOI: 10.1371/journal.pone.0082491.
Shift of intention of the project due to time plan:
By narrowing down the topic to ensure the feasibility of this project the focus or main purpose of the project will be the artistic approach. The tool will still combine the use of direct image to audio translation and the translation via sonification into a more abstract form. The main use cases will be generating unique audio samples for creative applications, such as sound design for interactive installations, brand audio identities, or matching image soundscapes and the possibility to be a versatile instrument for experimental media artists and display tool for image information.
By further research on different possibilities of sonification of image data and development of the sonification language itself the translation and display purpose is going to get more clear within the following weeks.
Testing of Google Gemini API for AI Object and Image Recognition:
The first testing of the Google Gemini Api started well. There are different models for dedicated object recognition and image recognition itself which can be combined to analyze pictures in terms of objects and partly scenery. These models (SSD, EfficientNET,…) create similar results but not always the same. It might be an option to make it selectable for the user (so that in a failure case a different model can be tried and may give better results). The scenery recognition itself tends to be a problem. It may be a possibility to try out different apis.
The data we get from this AI model is a tag for the recognized objects or image content and a percentage of the probability.
The next steps for the direct translation of it into realistic sound representations will be to test the possibility of using the api of freesound.org to search directly and automated for the recognized object tags and load matching audio files. These search calls also need to filter by copyright type of the sounds and a choosing rule / algorithm needs to be created.
object recognition: efficient float 16 model (Photo by Jason Oh on unsplash)object recognition: image splice test – recognition fail (Photo by Jason Oh on unsplash)object recognition: accurate but low score (Photo: https://lernen.zoner.de/)object recognition (photo: zdf.de)
Research on sonification of images / video material and different approaches:
The world of image sonification is rich with diverse techniques, each offering unique ways to transform visual data into auditory experiences. The world of image sonification is rich with diverse techniques, each offering unique ways to map visual data into auditory experiences. One of the most straightforward methods is raster scanning, introduced by Yeo and Berger. This technique maps the brightness values of grayscale image pixels directly to audio samples, creating a one-to-one correspondence between visual and auditory data. By scanning an image line by line, from top to bottom, the system generates a sound that reflects the texture and patterns of the image. For example, a smooth gradient might produce a steady tone, while a highly textured image could result in a more complex, evolving soundscape. The process is fully reversible, allowing for both image sonification and sound visualization, making it a versatile tool for artists and researchers alike. This method is particularly effective for sonifying image textures and exploring the auditory representation of visual filters, such as “patchwork” or “grain” effects.(Yeo and Berger, 2006)
Principle raster scanning (Yeo and Berger, 2006)
In contrast, Audible Panorama (Huang et al. 2019) automates sound mapping for 360° panorama images used in virtual reality (VR). It detects objects using computer vision, estimates their depth, and assigns spatialized audio from a database. For example, a car might trigger engine sounds, while a person generates footsteps, creating an immersive auditory experience that enhances VR realism. A user study confirmed that spatial audio significantly improves the sense of presence. It contains a interesting concept regarding to choosing a random audio file from a sound library to avoid producing similar or same results. Also it mentions the aspect of postprocessing the audios which also would be a relevant aspect for the image extender project.
principle audible panorama (Huang et al. 2019)
Another approach, HindSight (Schoop, Smith, and Hartmann 2018), focuses on real-time object detection and sonification in 360° video. Using a head-mounted camera and neural networks, it detects objects like cars and pedestrians, then sonifies their position and danger level through bone conduction headphones. Beeps increase in tempo and pan to indicate proximity and direction, providing real-time safety alerts for cyclists.
Finally, Sonic Panoramas (Kabisch, Kuester, and Penny 2005) takes an interactive approach, allowing users to navigate landscape images while generating sound based on their position. Edge detection extracts features like mountains or forests, mapping them to dynamic soundscapes. For instance, a mountain ridge might produce a resonant tone, while a forest creates layered, chaotic sounds, blending visual and auditory art. It also mentions different approaches for sonification itself. For example the idea of using micro (timbre, pitch and melody) and macro level (rhythm and form) mapping.
principle sonic panoramas (Kabisch, Kuester, and Penny 2005)
Each of these methods—raster scanning, Audible Panorama, HindSight, and Sonic Panoramas—demonstrates the versatility of sonification as a tool for transforming visual data into sound and lead keeping these different approaches in mind for developing my own sonification language or mapping method. It also leads to further research by checking some useful references they used in their work for a deeper understanding of sonification and extending the possibilities.
References
Huang, Haikun, Michael Solah, Dingzeyu Li, and Lap-Fai Yu. 2019. “Audible Panorama: Automatic Spatial Audio Generation for Panorama Imagery.” In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, 1–11. Glasgow, Scotland: ACM. https://doi.org/10.1145/3290605.3300851.
Kabisch, Eric, Falko Kuester, and Simon Penny. 2005. “Sonic Panoramas: Experiments with Interactive Landscape Image Sonification.” In Proceedings of the 2005 International Conference on Artificial Reality and Telexistence (ICAT), 156–163. Christchurch, New Zealand: HIT Lab NZ.
Schoop, Eldon, James Smith, and Bjoern Hartmann. 2018. “HindSight: Enhancing Spatial Awareness by Sonifying Detected Objects in Real-Time 360-Degree Video.” In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–12. Montreal, QC, Canada: ACM. https://doi.org/10.1145/3173574.3173717.
Yeo, Woon Seung, and Jonathan Berger. 2006. “Application of Raster Scanning Method to Image Sonification, Sound Visualization, Sound Analysis and Synthesis.” In Proceedings of the 9th International Conference on Digital Audio Effects (DAFx-06), 311–316. Montreal, Canada: DAFx.
The Image Extender project bridges accessibility and creativity, offering an innovative way to perceive visual data through sound. With its dual-purpose approach, the tool has the potential to redefine auditory experiences for diverse audiences, pushing the boundaries of technology and human perception.
The project is designed as a dual-purpose tool for immersive perception and creative sound design. By leveraging AI-based image recognition and sonification algorithms, the tool will transform visual data into auditory experiences. This innovative approach is intended for:
1. Visually Impaired Individuals 2. Artists and Designers
The tool will focus on translating colors, textures, shapes, and spatial arrangements into structured soundscapes, ensuring clarity and creativity for diverse users.
Core Functionality: Translating image data into sound using sonification frameworks and AI algorithms.
Target Audiences: Visually impaired users and creative professionals.
Platforms: Initially desktop applications with planned mobile deployment for on-the-go accessibility.
User Experience: A customizable interface to balance complexity, accessibility, and creativity.
Working Hypotheses and Requirements
Hypotheses:
Cross-modal sonification enhances understanding and creativity in visual-to-auditory transformations.
Intuitive soundscapes improve accessibility for visually impaired users compared to traditional methods.
Requirements:
Develop an intuitive sonification framework adaptable to various images.
Integrate customizable settings to prevent sensory overload.
Ensure compatibility across platforms (desktop and mobile).
Subtasks
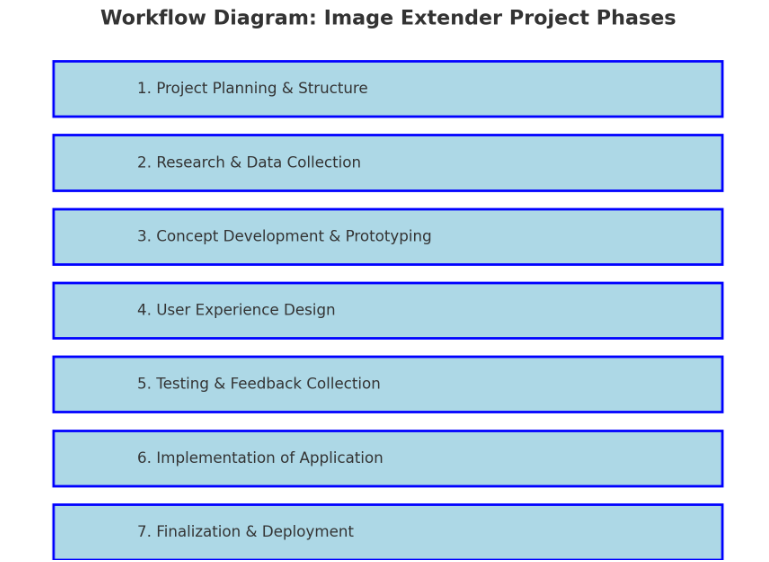
1. Project Planning & Structure
Define Scope and Goals: Clarify key deliverables and objectives for both visually impaired users and artists/designers.
Research Methods: Identify research approaches (e.g., user interviews, surveys, literature review).
Project Timeline and Milestones: Establish a phased timeline including prototyping, testing, and final implementation.
Identify Dependencies: List libraries, frameworks, and tools needed (Python, Pure Data, Max/MSP, OSC, etc.).
2. Research & Data Collection
Sonification Techniques: Research existing sonification methods and metaphors for cross-modal (sight-to-sound) mapping and research different other approaches that can also blend in the overall sonification strategy.
Psychoacoustics & Perceptual Mapping: Review how different sound frequencies, intensities, and spatialization affect perception.
Existing Tools & References: Study tools like Melobytes, VOSIS, and BeMyEyes to understand features, limitations, and user feedback.
object detection from python yolo library
3. Concept Development & Prototyping
Develop Sonification Mapping Framework: Define rules for mapping visual elements (color, shape, texture) to sound parameters (pitch, timbre, rhythm).
Simple Prototype: Create a basic prototype that integrates:
AI content recognition (Python + image processing libraries).
Sound generation (Pure Data or Max/MSP).
Communication via OSC (e.g., using Wekinator).
Create or collect Sample Soundscapes: Generate initial soundscapes for different types of images (e.g., landscapes, portraits, abstract visuals).
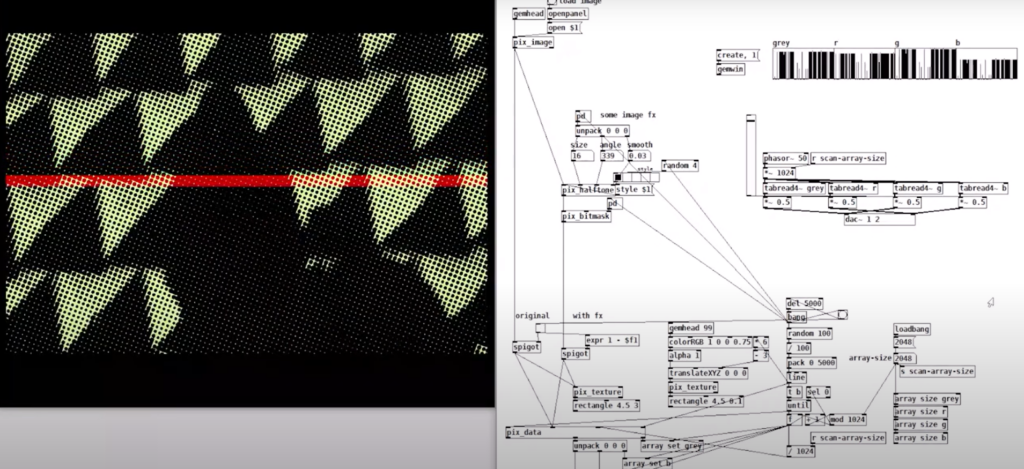
example of puredata with rem library (image to sound in pure data by Artiom Constantinov)
4. User Experience Design
UI/UX Design for Desktop:
Design intuitive interface for uploading images and adjusting sonification parameters.
Mock up controls for adjusting sound complexity, intensity, and spatialization.
Accessibility Features:
Ensure screen reader compatibility.
Develop customizable presets for different levels of user experience (basic vs. advanced).
Mobile Optimization Plan:
Plan for responsive design and functionality for smartphones.
5. Testing & Feedback Collection
Create Testing Scenarios:
Develop a set of diverse images (varying in content, color, and complexity).
Usability Testing with Visually Impaired Users:
Gather feedback on the clarity, intuitiveness, and sensory experience of the sonifications.
Identify areas of overstimulation or confusion.
Feedback from Artists/Designers:
Assess the creative flexibility and utility of the tool for sound design.
Iterate Based on Feedback:
Refine sonification mappings and interface based on user input.
6. Implementation of Standalone Application
Develop Core Application:
Integrate image recognition with sonification engine.
Implement adjustable parameters for sound generation.
Error Handling & Performance Optimization:
Ensure efficient processing for high-resolution images.
Handle edge cases for unexpected or low-quality inputs.
Cross-Platform Compatibility:
Ensure compatibility with Windows, macOS, and plan for future mobile deployment.
7. Finalization & Deployment
Finalize Feature Set:
Balance between accessibility and creative flexibility.
Ensure the sonification language is both consistent and adaptable.
Documentation & Tutorials:
Create user guides for visually impaired users and artists.
Provide tutorials for customizing sonification settings.
Deployment:
Package as a standalone desktop application.
Plan for mobile release (potentially a future phase).
Technological Basis Subtasks:
Programming: Develop core image recognition and processing modules in Python.
Sonification Engine: Create audio synthesis patches in Pure Data/Max/MSP.
Integration: Implement OSC communication between Python and the sound engine.
UI Development: Design and code the user interface for accessibility and usability.
Testing Automation: Create scripts for automating image-sonification tests.
Possible academic foundations for further research and work:
Chatterjee, Oindrila, and Shantanu Chakrabartty. “Using Growth Transform Dynamical Systems for Spatio-Temporal Data Sonification.” arXiv preprint, 2021.
Chion, Michel. Audio-Vision. New York: Columbia University Press, 1994.
Ziemer, Tim. Psychoacoustic Music Sound Field Synthesis. Cham: Springer International Publishing, 2020.
Ziemer, Tim, Nuttawut Nuchprayoon, and Holger Schultheis. “Psychoacoustic Sonification as User Interface for Human-Machine Interaction.” International Journal of Informatics Society, 2020.
Ziemer, Tim, and Holger Schultheis. “Three Orthogonal Dimensions for Psychoacoustic Sonification.” Acta Acustica United with Acustica, 2020.
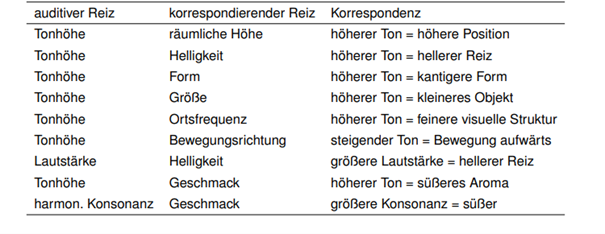
The project would be a program that uses either AI-content recognition or a specific sonification algorithm by using equivalent of the perception of sight (cross-model metaphors).
examples of cross modal metaphors (Görne, 2017, S.53)
This approach could serve two main audiences:
1. Visually Impaired Individuals: The tool would provide an alternative to traditional audio descriptions, aiming instead to deliver a sonic experience that evokes the ambiance, spatial depth, or mood of an image. Instead of giving direct descriptive feedback, it would use non-verbal soundscapes to create an “impression” of the scene, engaging the listener’s perception intuitively. Therefore, the aspect of a strict sonification language might be a good approach. Maybe even better than just displaying the sounds of the images. Or maybe a mixture of both.
2. Artists and Designers: The tool could generate unique audio samples for creative applications, such as sound design for interactive installations, brand audio identities, or cinematic soundscapes. By enabling the synthesis of sound based on visual data, the tool could become a versatile instrument for experimental media artists.
Purpose
The core purpose would be the mixture of both purposes before, a tool that supports and helps creating in the same suite.
The dual purpose of accessibility and creativity is central to the project’s design philosophy, but balancing these objectives poses a challenge. While the tool should serve as a robust aid for visually impaired users, it also needs to function as a practical and flexible sound design instrument.
The final product can then be used by people who benefit from the added perception they get of images and screens and for artists or designers as a tool.
Primary Goal
A primary goal is to establish a sonification language that is intuitive, consistent, and adaptable to a variety of images and scenes. This “language” would ideally be flexible enough for creative expression yet structured enough to provide clarity for visually impaired users. Using a dynamic, adaptable set of rules tied to image data, the tool would be able to translate colors, textures, shapes, and contrasts into specific sounds.
To make the tool accessible and enjoyable, careful attention needs to be paid to the balance of sound complexity. Testing with visually impaired individuals will be essential for calibrating the audio to avoid overwhelming or confusing sensory experiences. Adjustable parameters could allow users to tailor sound intensity, frequency, and spatialization, giving them control while preserving the underlying sonification framework. It’s important to focus on realistic an achievable goal first.
planning on the methods (structure)
research and data collection
simple prototyping of key concept
testing phases
implementation in an standalone application
ui design and mobile optimization
The prototype will evolve in stages, with usability testing playing a key role in refining functionality. Early feedback from visually impaired testers will be invaluable in shaping how soundscapes are structured and controlled. Incorporating adjustable settings will likely be necessary to allow users to customize their experience and avoid potential overstimulation. However, this customization could complicate the design if the aim is to develop a consistent sonification language. Testing will help to balance these needs
Initial development will target desktop environments, with plans to expand to smartphones. A mobile-friendly interface would allow users to access sonification on the go, making it easier to engage with images and scenes from any device.
In general, it could lead to a different perception of sound in connection with images or visuals.
Needed components
Technological Basis:
Programming Language & IDE: The primary development of the image recognition could be done in Python, which offers strong libraries for image processing, machine learning, and integration with sound engines. Also wekinator could be a good start for the communication via OSC for example.
Sonification Tools: Pure Data or Max/MSP are ideal choices for creating the audio processing and synthesis framework, as they enable fine-tuned audio manipulation. These platforms can map visual data inputs (like color or shape) to sound parameters (such as pitch, timbre, or rhythm).
Testing Resources: A set of test images and videos will be required to refine the tool’s translations across various visual scenarios.
Existing Inspirations and References:
– Melobytes: Software that converts images to music, highlighting the potential for creative auditory representations of visuals.
– VOSIS: A synthesizer that filters visual data based on grayscale values, demonstrating how sound synthesis can be based on visual texture.
– image-sonification.vercel.app: A platform that creates audio loops from RGB values, showing how color data can be translated into sound.
– BeMyEyes: An app that provides auditory descriptions for visually impaired users, emphasizing the importance of accessibility in technology design.
Academic Foundations:
Literature on sonification, psychoacoustics, and synthesis will support the development of the program. These fields will help inform how sound can effectively communicate complex information without overwhelming the listener.