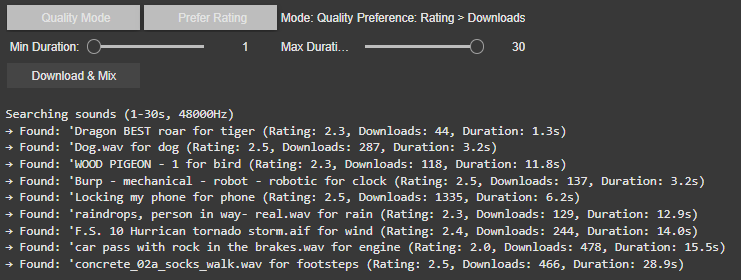
Best Result Mode (Quality-Focused) The system prioritizes sounds with the highest ratings and download counts, ensuring professional-grade audio quality. It progressively relaxes standards (e.g., from 4.0+ to 2.5+ ratings) if no perfect match is found, guaranteeing a usable sound for every tag.
Random Mode (Diverse Selection) In this mode, the tool ignores quality filters, returning the first valid sound for each tag. This is ideal for quick experiments or when unpredictability is desired or to be sure to achieve different results.
2. Filters: Rating vs. Downloads
Users can further refine searches with two filter preferences:
Rating > Downloads Favors sounds with the highest user ratings, even if they have fewer downloads. This prioritizes subjective quality (e.g., clean recordings, well-edited clips). Example: A rare, pristine “tiger growl” with a 4.8/5 rating might be chosen over a popular but noisy alternative.
Downloads > Rating Prioritizes widely downloaded sounds, which often indicate reliability or broad appeal. This is useful for finding “standard” effects (e.g., a typical phone ring). Example: A generic “clock tick” with 10,000 downloads might be selected over a niche, high-rated vintage clock sound.
If there would be no matching sound for the rating or download approach the system gets to the fallback and uses the hierarchy table privided to change for example maple into tree.
Intelligent Frequency Management
The audio engine now implements Bark Scale Filtering, which represents a significant improvement over the previous FFT peaks approach. By dividing the frequency spectrum into 25 critical bands spanning 20Hz to 20kHz, the system now precisely mirrors human hearing sensitivity. This psychoacoustic alignment enables more natural spectral adjustments that maintain perceptual balance while processing audio content.
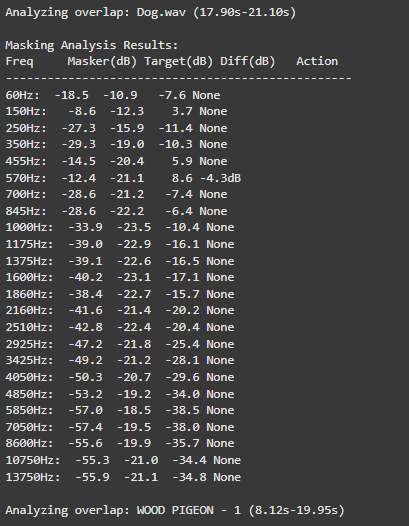
For dynamic equalization, the system features adaptive EQ Activation that intelligently engages only during actual sound clashes. For instance, when two sounds compete at 570Hz, the EQ applies a precise -4.7dB reduction exclusively during the overlapping period.
o preserve audio quality, the system employs Conservative Processing principles. Frequency band reductions are strictly limited to a maximum of -6dB, preventing artificial-sounding results. Additionally, the use of wide Q values (1.0) ensures that EQ adjustments maintain the natural timbral characteristics of each sound source while effectively resolving masking issues.
These core upgrades collectively transform Image Extender’s mixing capabilities, enabling professional-grade audio results while maintaining the system’s generative and adaptive nature. The improvements are particularly noticeable in complex soundscapes containing multiple overlapping elements with competing frequency content.
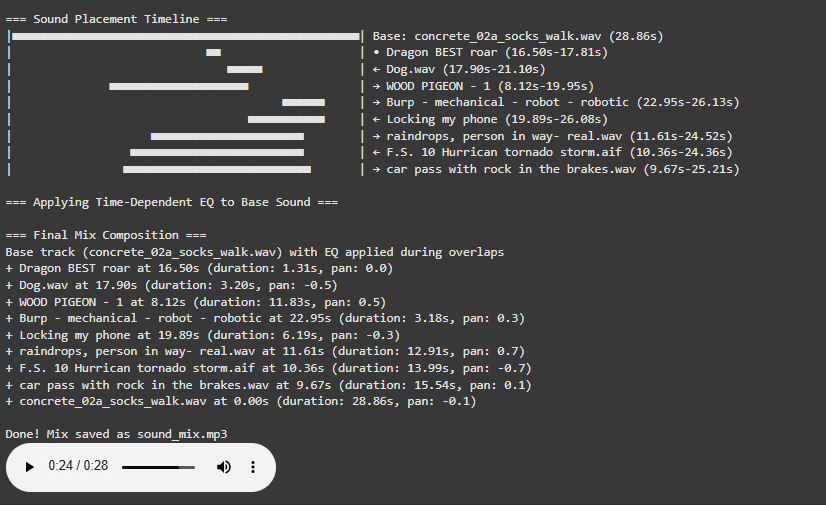
Visualization for a better overview
The newly implemented Timeline Visualization provides unprecedented insight into the mixing process through an intuitive graphical representation.
Researching Automated Mixing Strategies for Clarity and Real-Time Composition
As the Image Extender project continues to evolve from a tagging-to-sound pipeline into a dynamic, spatially aware audio compositing system, this phase focused on surveying and evaluating recent methods in automated sound mixing. My aim was to understand how existing research handles spectral masking, spatial distribution, and frequency-aware filtering—especially in scenarios where multiple unrelated sounds are combined without a human in the loop.
This blog post synthesizes findings from several key research papers and explores how their techniques may apply to our use case: a generative soundscape engine driven by object detection and Freesound API integration. The next development phase will evaluate which of these methods can be realistically adapted into the Python-based architecture.
Adaptive Filtering Through Time–Frequency Masking Detection
A compelling solution to masking was presented by Zhao and Pérez-Cota (2024), who proposed a method for adaptive equalization driven by masking analysis in both time and frequency. By calculating short-time Fourier transforms (STFT) for each track, their system identifies where overlap occurs and evaluates the masking directionality—determining whether a sound acts as a masker or a maskee over time.
These interactions are quantified into masking matrices that inform the design of parametric filters, tuned to reduce only the problematic frequency bands, while preserving the natural timbre and dynamics of the source sounds. The end result is a frequency-aware mixing approach that adapts to real masking events rather than applying static or arbitrary filtering.
Why this matters for Image Extender: Generated mixes often feature overlapping midrange content (e.g., engine hums, rustling leaves, footsteps). By applying this masking-aware logic, the system can avoid blunt frequency cuts and instead respond intelligently to real-time spectral conflicts.
Implementation possibilities:
STFTs: librosa.stft
Masking matrices: pairwise multiplication and normalization (NumPy)
EQ curves: second-order IIR filters via scipy.signal.iirfilter
“This information is then systematically used to design and apply filters… improving the clarity of the mix.” — Zhao and Pérez-Cota (2024)
Iterative Mixing Optimization Using Psychoacoustic Metrics
Another strong candidate emerged from Liu et al. (2024), who proposed an automatic mixing system based on iterative masking minimization. Their framework evaluates masking using a perceptual model derived from PEAQ (ITU-R BS.1387) and adjusts mixing parameters—equalization, dynamic range compression, and gain—through iterative optimization.
The system’s strength lies in its objective function: it not only minimizes total masking but also seeks to balance masking contributions across tracks, ensuring that no source is disproportionately buried. The optimization process runs until a minimum is reached, using a harmony search algorithm that continuously tunes each effect’s parameters for improved spectral separation.
Why this matters for Image Extender: This kind of global optimization is well-suited for multi-object scenes, where several detected elements contribute sounds. It supports a wide range of source content and adapts mixing decisions to preserve intelligibility across diverse sonic elements.
Implementation path:
Masking metrics: critical band energy modeling on the Bark scale
Optimization: scipy.optimize.differential_evolution or other derivative-free methods
EQ and dynamics: Python wrappers (pydub, sox, or raw filter design via scipy.signal)
“Different audio effects… are applied via an iterative Harmony searching algorithm that aims to minimize the masking.” — Liu et al. (2024)
Comparative Analysis
Method
Core Approach
Integration Potential
Implementation Effort
Time–Frequency Masking (Zhao)
Analyze masking via STFT; apply targeted EQ
High — per-event conflict resolution
Medium
Iterative Optimization (Liu)
Minimize masking metric via parametric search
High — global mix clarity
High
Both methods offer significant value. Zhao’s system is elegant in its directness—its per-pair analysis supports fine-grained filtering on demand, suitable for real-time or batch processes. Liu’s framework, while computationally heavier, offers a holistic solution that balances all tracks simultaneously, and may serve as a backend “refinement pass” after initial sound placement.
Looking Ahead
This research phase provided the theoretical and technical groundwork for the next evolution of Image Extender’s audio engine. The next development milestone will explore hybrid strategies that combine these insights:
Implementing a masking matrix engine to detect conflicts dynamically
Building filter generation pipelines based on frequency overlap intensity
Testing iterative mix refinement using masking as an objective metric
Measuring the perceived clarity improvements across varied image-driven scenes
The Image Extender project bridges accessibility and creativity, offering an innovative way to perceive visual data through sound. With its dual-purpose approach, the tool has the potential to redefine auditory experiences for diverse audiences, pushing the boundaries of technology and human perception.
The project is designed as a dual-purpose tool for immersive perception and creative sound design. By leveraging AI-based image recognition and sonification algorithms, the tool will transform visual data into auditory experiences. This innovative approach is intended for:
1. Visually Impaired Individuals 2. Artists and Designers
The tool will focus on translating colors, textures, shapes, and spatial arrangements into structured soundscapes, ensuring clarity and creativity for diverse users.
Core Functionality: Translating image data into sound using sonification frameworks and AI algorithms.
Target Audiences: Visually impaired users and creative professionals.
Platforms: Initially desktop applications with planned mobile deployment for on-the-go accessibility.
User Experience: A customizable interface to balance complexity, accessibility, and creativity.
Working Hypotheses and Requirements
Hypotheses:
Cross-modal sonification enhances understanding and creativity in visual-to-auditory transformations.
Intuitive soundscapes improve accessibility for visually impaired users compared to traditional methods.
Requirements:
Develop an intuitive sonification framework adaptable to various images.
Integrate customizable settings to prevent sensory overload.
Ensure compatibility across platforms (desktop and mobile).
Subtasks
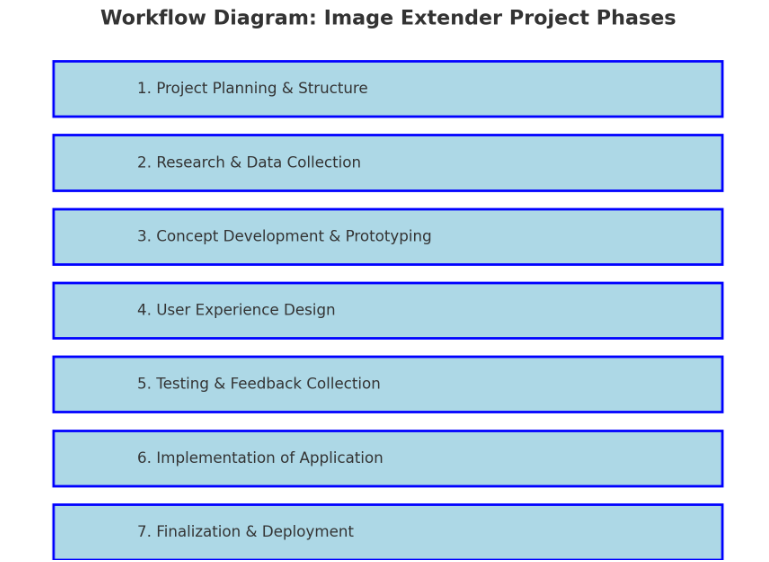
1. Project Planning & Structure
Define Scope and Goals: Clarify key deliverables and objectives for both visually impaired users and artists/designers.
Research Methods: Identify research approaches (e.g., user interviews, surveys, literature review).
Project Timeline and Milestones: Establish a phased timeline including prototyping, testing, and final implementation.
Identify Dependencies: List libraries, frameworks, and tools needed (Python, Pure Data, Max/MSP, OSC, etc.).
2. Research & Data Collection
Sonification Techniques: Research existing sonification methods and metaphors for cross-modal (sight-to-sound) mapping and research different other approaches that can also blend in the overall sonification strategy.
Psychoacoustics & Perceptual Mapping: Review how different sound frequencies, intensities, and spatialization affect perception.
Existing Tools & References: Study tools like Melobytes, VOSIS, and BeMyEyes to understand features, limitations, and user feedback.
object detection from python yolo library
3. Concept Development & Prototyping
Develop Sonification Mapping Framework: Define rules for mapping visual elements (color, shape, texture) to sound parameters (pitch, timbre, rhythm).
Simple Prototype: Create a basic prototype that integrates:
AI content recognition (Python + image processing libraries).
Sound generation (Pure Data or Max/MSP).
Communication via OSC (e.g., using Wekinator).
Create or collect Sample Soundscapes: Generate initial soundscapes for different types of images (e.g., landscapes, portraits, abstract visuals).
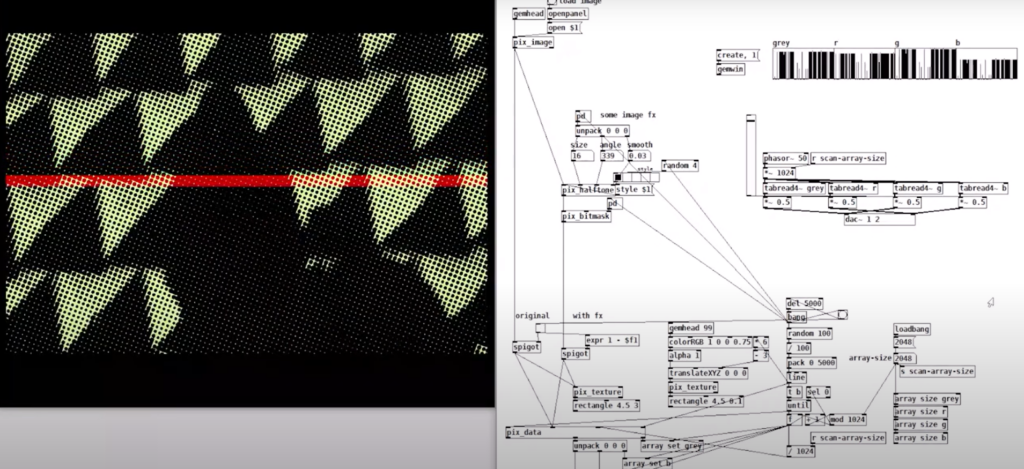
example of puredata with rem library (image to sound in pure data by Artiom Constantinov)
4. User Experience Design
UI/UX Design for Desktop:
Design intuitive interface for uploading images and adjusting sonification parameters.
Mock up controls for adjusting sound complexity, intensity, and spatialization.
Accessibility Features:
Ensure screen reader compatibility.
Develop customizable presets for different levels of user experience (basic vs. advanced).
Mobile Optimization Plan:
Plan for responsive design and functionality for smartphones.
5. Testing & Feedback Collection
Create Testing Scenarios:
Develop a set of diverse images (varying in content, color, and complexity).
Usability Testing with Visually Impaired Users:
Gather feedback on the clarity, intuitiveness, and sensory experience of the sonifications.
Identify areas of overstimulation or confusion.
Feedback from Artists/Designers:
Assess the creative flexibility and utility of the tool for sound design.
Iterate Based on Feedback:
Refine sonification mappings and interface based on user input.
6. Implementation of Standalone Application
Develop Core Application:
Integrate image recognition with sonification engine.
Implement adjustable parameters for sound generation.
Error Handling & Performance Optimization:
Ensure efficient processing for high-resolution images.
Handle edge cases for unexpected or low-quality inputs.
Cross-Platform Compatibility:
Ensure compatibility with Windows, macOS, and plan for future mobile deployment.
7. Finalization & Deployment
Finalize Feature Set:
Balance between accessibility and creative flexibility.
Ensure the sonification language is both consistent and adaptable.
Documentation & Tutorials:
Create user guides for visually impaired users and artists.
Provide tutorials for customizing sonification settings.
Deployment:
Package as a standalone desktop application.
Plan for mobile release (potentially a future phase).
Technological Basis Subtasks:
Programming: Develop core image recognition and processing modules in Python.
Sonification Engine: Create audio synthesis patches in Pure Data/Max/MSP.
Integration: Implement OSC communication between Python and the sound engine.
UI Development: Design and code the user interface for accessibility and usability.
Testing Automation: Create scripts for automating image-sonification tests.
Possible academic foundations for further research and work:
Chatterjee, Oindrila, and Shantanu Chakrabartty. “Using Growth Transform Dynamical Systems for Spatio-Temporal Data Sonification.” arXiv preprint, 2021.
Chion, Michel. Audio-Vision. New York: Columbia University Press, 1994.
Ziemer, Tim. Psychoacoustic Music Sound Field Synthesis. Cham: Springer International Publishing, 2020.
Ziemer, Tim, Nuttawut Nuchprayoon, and Holger Schultheis. “Psychoacoustic Sonification as User Interface for Human-Machine Interaction.” International Journal of Informatics Society, 2020.
Ziemer, Tim, and Holger Schultheis. “Three Orthogonal Dimensions for Psychoacoustic Sonification.” Acta Acustica United with Acustica, 2020.