Dynamic Audio Balancing Through Visual Importance Mapping
This development phase introduces sophisticated volume control based on visual importance analysis, creating audio mixes that dynamically reflect the compositional hierarchy of the original image. Where previous systems ensured semantic accuracy, we now ensure proportional acoustic representation.
The core advancement lies in importance-based volume scaling. Each detected object’s importance value (0-1 scale from visual analysis) now directly determines its loudness level within a configurable range (-30 dBFS to -20 dBFS). Visually dominant elements receive higher volume placement, while background objects maintain subtle presence.
Key enhancements include:
– Linear importance-to-volume mapping creating natural acoustic hierarchies
The system now distinguishes between foreground emphasis and background ambiance, producing mixes where a visually central “car” (importance 0.9) sounds appropriately prominent compared to a distant “tree” (importance 0.2), while “urban street atmo” provides unwavering environmental foundation.
This represents a significant evolution from flat audio layering to dynamically balanced soundscapes that respect visual composition through intelligent volume distribution.
Semantic Sound Validation & Ensuring Acoustic Relevance Through AI-Powered Verification
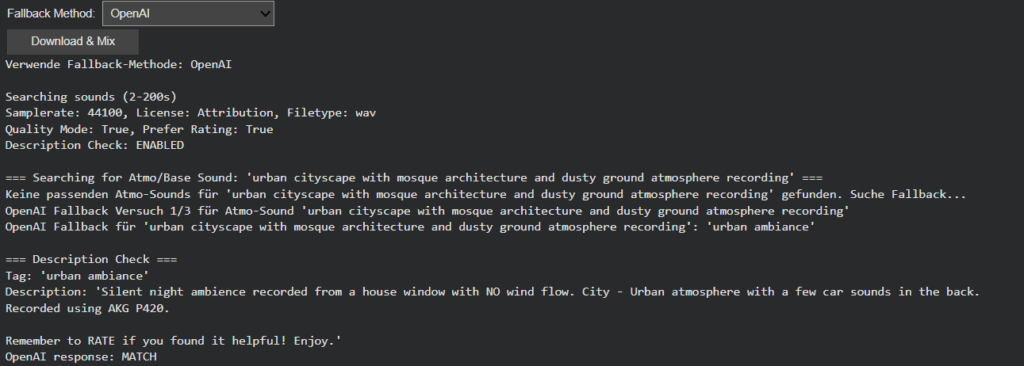
Building upon the intelligent fallback systems developed in Phase III, this week’s development addressed a more subtle yet critical challenge in audio generation: ensuring that retrieved sounds semantically match their visual counterparts. While the fallback system successfully handled missing sounds, I discovered that even when sounds were technically available, they didn’t always represent the intended objects accurately. This phase introduces a sophisticated description verification layer and flexible filtering system that transforms sound retrieval from a mechanical matching process to a semantically intelligent selection.
The newly implemented description verification system addresses this through OpenAI-powered semantic analysis. Each retrieved sound’s description is now evaluated against the original visual tag to determine if it represents the actual object or just references it contextually. This ensures that when Image Extender layers “car” sounds into a mix, they’re authentic engine recordings rather than musical tributes.
Intelligent Filter Architecture: Balancing Precision and Flexibility
Recognizing that overly restrictive filtering could eliminate viable sounds, we redesigned the filtering system with adaptive “any” options across all parameters. The Bit-Depth filter got removed because it resulted in search errors which is also mentioned in the documentation of the freesound.org api.
Scene-Aware Audio Composition: Atmo Sounds as Acoustic Foundation
A significant architectural improvement involves intelligent base track selection. The system now distinguishes between foreground objects and background atmosphere:
Atmo-First Composition: Background sounds are prioritized as the foundational layer
Stereo Preservation: Atmo/ambience sounds retain their stereo imaging for immersive soundscapes
Object Layering: Foreground sounds are positioned spatially based on visual detection coordinates
This creates mixes where environmental sounds form a coherent base while individual objects occupy their proper spatial positions, resulting in professionally layered audio compositions.
Dual-Mode Object Detection with Scene Understanding
OpenAI GPT-4.1 Vision: Provides comprehensive scene analysis including:
Object identification with spatial positioning
Environmental context extraction
Mood and atmosphere assessment
Structured semantic output for precise sound matching
The fallback system evolved into a sophisticated multi-stage process:
Atmo Sound Prioritization: Scene_and_location tags are searched first as base layer
Object Search: query with user-configured filters
Description Verification: AI-powered semantic validation of each result
Quality Tiering: Progressive relaxation of rating and download thresholds
Pagination Support: Multiple result pages when initial matches fail verification
Controlled Fallback: Limited OpenAI tag regeneration with automatic timeout
This structured approach prevents infinite loops while maximizing the chances of finding appropriate sounds. The system now intelligently gives up after reasonable attempts, preventing computational waste while maintaining output quality.
Toward Contextually Intelligent Audio Generation
This week’s enhancements represent a significant leap from simple sound retrieval to contextually intelligent audio selection. The combination of semantic verification, adaptive filtering and scene-aware composition creates a system that doesn’t just find sounds, it finds the right sounds and arranges them intelligently.
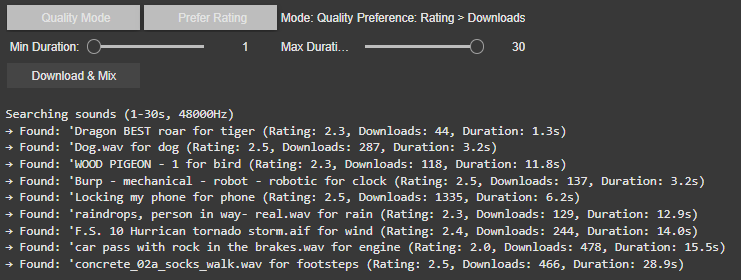
Best Result Mode (Quality-Focused) The system prioritizes sounds with the highest ratings and download counts, ensuring professional-grade audio quality. It progressively relaxes standards (e.g., from 4.0+ to 2.5+ ratings) if no perfect match is found, guaranteeing a usable sound for every tag.
Random Mode (Diverse Selection) In this mode, the tool ignores quality filters, returning the first valid sound for each tag. This is ideal for quick experiments or when unpredictability is desired or to be sure to achieve different results.
2. Filters: Rating vs. Downloads
Users can further refine searches with two filter preferences:
Rating > Downloads Favors sounds with the highest user ratings, even if they have fewer downloads. This prioritizes subjective quality (e.g., clean recordings, well-edited clips). Example: A rare, pristine “tiger growl” with a 4.8/5 rating might be chosen over a popular but noisy alternative.
Downloads > Rating Prioritizes widely downloaded sounds, which often indicate reliability or broad appeal. This is useful for finding “standard” effects (e.g., a typical phone ring). Example: A generic “clock tick” with 10,000 downloads might be selected over a niche, high-rated vintage clock sound.
If there would be no matching sound for the rating or download approach the system gets to the fallback and uses the hierarchy table privided to change for example maple into tree.
Intelligent Frequency Management
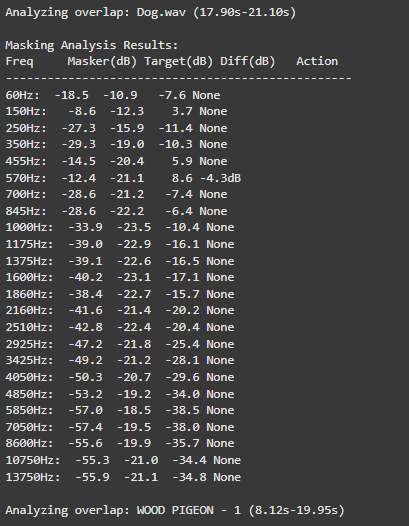
The audio engine now implements Bark Scale Filtering, which represents a significant improvement over the previous FFT peaks approach. By dividing the frequency spectrum into 25 critical bands spanning 20Hz to 20kHz, the system now precisely mirrors human hearing sensitivity. This psychoacoustic alignment enables more natural spectral adjustments that maintain perceptual balance while processing audio content.
For dynamic equalization, the system features adaptive EQ Activation that intelligently engages only during actual sound clashes. For instance, when two sounds compete at 570Hz, the EQ applies a precise -4.7dB reduction exclusively during the overlapping period.
o preserve audio quality, the system employs Conservative Processing principles. Frequency band reductions are strictly limited to a maximum of -6dB, preventing artificial-sounding results. Additionally, the use of wide Q values (1.0) ensures that EQ adjustments maintain the natural timbral characteristics of each sound source while effectively resolving masking issues.
These core upgrades collectively transform Image Extender’s mixing capabilities, enabling professional-grade audio results while maintaining the system’s generative and adaptive nature. The improvements are particularly noticeable in complex soundscapes containing multiple overlapping elements with competing frequency content.
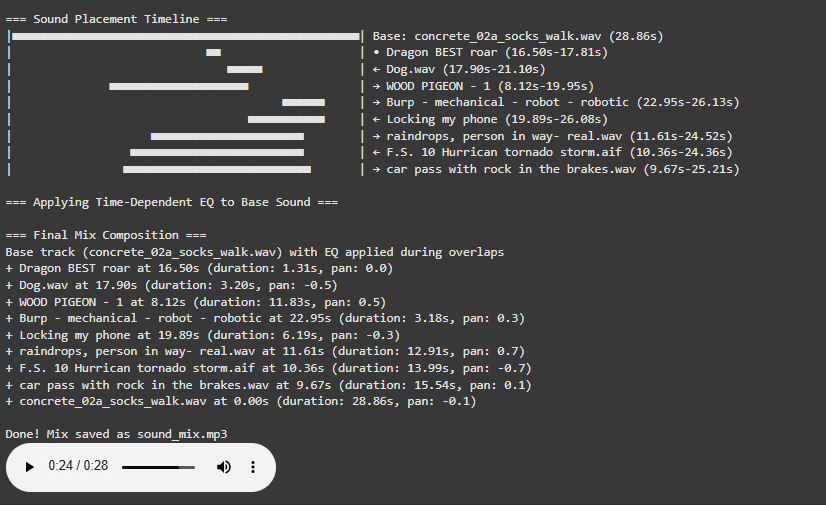
Visualization for a better overview
The newly implemented Timeline Visualization provides unprecedented insight into the mixing process through an intuitive graphical representation.
Researching Automated Mixing Strategies for Clarity and Real-Time Composition
As the Image Extender project continues to evolve from a tagging-to-sound pipeline into a dynamic, spatially aware audio compositing system, this phase focused on surveying and evaluating recent methods in automated sound mixing. My aim was to understand how existing research handles spectral masking, spatial distribution, and frequency-aware filtering—especially in scenarios where multiple unrelated sounds are combined without a human in the loop.
This blog post synthesizes findings from several key research papers and explores how their techniques may apply to our use case: a generative soundscape engine driven by object detection and Freesound API integration. The next development phase will evaluate which of these methods can be realistically adapted into the Python-based architecture.
Adaptive Filtering Through Time–Frequency Masking Detection
A compelling solution to masking was presented by Zhao and Pérez-Cota (2024), who proposed a method for adaptive equalization driven by masking analysis in both time and frequency. By calculating short-time Fourier transforms (STFT) for each track, their system identifies where overlap occurs and evaluates the masking directionality—determining whether a sound acts as a masker or a maskee over time.
These interactions are quantified into masking matrices that inform the design of parametric filters, tuned to reduce only the problematic frequency bands, while preserving the natural timbre and dynamics of the source sounds. The end result is a frequency-aware mixing approach that adapts to real masking events rather than applying static or arbitrary filtering.
Why this matters for Image Extender: Generated mixes often feature overlapping midrange content (e.g., engine hums, rustling leaves, footsteps). By applying this masking-aware logic, the system can avoid blunt frequency cuts and instead respond intelligently to real-time spectral conflicts.
Implementation possibilities:
STFTs: librosa.stft
Masking matrices: pairwise multiplication and normalization (NumPy)
EQ curves: second-order IIR filters via scipy.signal.iirfilter
“This information is then systematically used to design and apply filters… improving the clarity of the mix.” — Zhao and Pérez-Cota (2024)
Iterative Mixing Optimization Using Psychoacoustic Metrics
Another strong candidate emerged from Liu et al. (2024), who proposed an automatic mixing system based on iterative masking minimization. Their framework evaluates masking using a perceptual model derived from PEAQ (ITU-R BS.1387) and adjusts mixing parameters—equalization, dynamic range compression, and gain—through iterative optimization.
The system’s strength lies in its objective function: it not only minimizes total masking but also seeks to balance masking contributions across tracks, ensuring that no source is disproportionately buried. The optimization process runs until a minimum is reached, using a harmony search algorithm that continuously tunes each effect’s parameters for improved spectral separation.
Why this matters for Image Extender: This kind of global optimization is well-suited for multi-object scenes, where several detected elements contribute sounds. It supports a wide range of source content and adapts mixing decisions to preserve intelligibility across diverse sonic elements.
Implementation path:
Masking metrics: critical band energy modeling on the Bark scale
Optimization: scipy.optimize.differential_evolution or other derivative-free methods
EQ and dynamics: Python wrappers (pydub, sox, or raw filter design via scipy.signal)
“Different audio effects… are applied via an iterative Harmony searching algorithm that aims to minimize the masking.” — Liu et al. (2024)
Comparative Analysis
Method
Core Approach
Integration Potential
Implementation Effort
Time–Frequency Masking (Zhao)
Analyze masking via STFT; apply targeted EQ
High — per-event conflict resolution
Medium
Iterative Optimization (Liu)
Minimize masking metric via parametric search
High — global mix clarity
High
Both methods offer significant value. Zhao’s system is elegant in its directness—its per-pair analysis supports fine-grained filtering on demand, suitable for real-time or batch processes. Liu’s framework, while computationally heavier, offers a holistic solution that balances all tracks simultaneously, and may serve as a backend “refinement pass” after initial sound placement.
Looking Ahead
This research phase provided the theoretical and technical groundwork for the next evolution of Image Extender’s audio engine. The next development milestone will explore hybrid strategies that combine these insights:
Implementing a masking matrix engine to detect conflicts dynamically
Building filter generation pipelines based on frequency overlap intensity
Testing iterative mix refinement using masking as an objective metric
Measuring the perceived clarity improvements across varied image-driven scenes