Semantic Sound Validation & Ensuring Acoustic Relevance Through AI-Powered Verification
Building upon the intelligent fallback systems developed in Phase III, this week’s development addressed a more subtle yet critical challenge in audio generation: ensuring that retrieved sounds semantically match their visual counterparts. While the fallback system successfully handled missing sounds, I discovered that even when sounds were technically available, they didn’t always represent the intended objects accurately. This phase introduces a sophisticated description verification layer and flexible filtering system that transforms sound retrieval from a mechanical matching process to a semantically intelligent selection.
The newly implemented description verification system addresses this through OpenAI-powered semantic analysis. Each retrieved sound’s description is now evaluated against the original visual tag to determine if it represents the actual object or just references it contextually. This ensures that when Image Extender layers “car” sounds into a mix, they’re authentic engine recordings rather than musical tributes.
Intelligent Filter Architecture: Balancing Precision and Flexibility
Recognizing that overly restrictive filtering could eliminate viable sounds, we redesigned the filtering system with adaptive “any” options across all parameters. The Bit-Depth filter got removed because it resulted in search errors which is also mentioned in the documentation of the freesound.org api.
Scene-Aware Audio Composition: Atmo Sounds as Acoustic Foundation
A significant architectural improvement involves intelligent base track selection. The system now distinguishes between foreground objects and background atmosphere:
- Scene & Location Analysis: Object detection extracts environmental context (e.g., “forest atmo,” “urban street,” “beach waves”)
- Atmo-First Composition: Background sounds are prioritized as the foundational layer
- Stereo Preservation: Atmo/ambience sounds retain their stereo imaging for immersive soundscapes
- Object Layering: Foreground sounds are positioned spatially based on visual detection coordinates
This creates mixes where environmental sounds form a coherent base while individual objects occupy their proper spatial positions, resulting in professionally layered audio compositions.

Dual-Mode Object Detection with Scene Understanding
OpenAI GPT-4.1 Vision: Provides comprehensive scene analysis including:
- Object identification with spatial positioning
- Environmental context extraction
- Mood and atmosphere assessment
- Structured semantic output for precise sound matching
MediaPipe EfficientDet: Offers lightweight, real-time object detection:
- Fast local processing without API dependencies
- Basic object recognition with positional data
- Fallback when cloud services are unavailable
Wildcard-Enhanced Semantic Search: Beyond Exact Matching
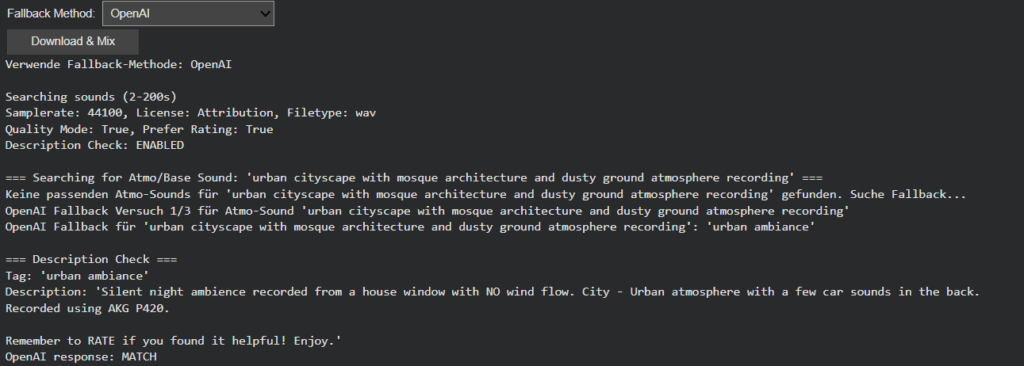
Multi-Stage Fallback with Verification Limits
The fallback system evolved into a sophisticated multi-stage process:
- Atmo Sound Prioritization: Scene_and_location tags are searched first as base layer
- Object Search: query with user-configured filters
- Description Verification: AI-powered semantic validation of each result
- Quality Tiering: Progressive relaxation of rating and download thresholds
- Pagination Support: Multiple result pages when initial matches fail verification
- Controlled Fallback: Limited OpenAI tag regeneration with automatic timeout
This structured approach prevents infinite loops while maximizing the chances of finding appropriate sounds. The system now intelligently gives up after reasonable attempts, preventing computational waste while maintaining output quality.
Toward Contextually Intelligent Audio Generation
This week’s enhancements represent a significant leap from simple sound retrieval to contextually intelligent audio selection. The combination of semantic verification, adaptive filtering and scene-aware composition creates a system that doesn’t just find sounds, it finds the right sounds and arranges them intelligently.