Room-Aware Mixing – From Image Analysis to Coherent Acoustic Spaces
Instead of attempting to recover exact physical properties, the system derives normalized, perceptual room parameters from visual cues such as geometry, materials, furnishing density, and openness. These parameters are intentionally abstracted to work with algorithmic reverbs.
The introduced parameters are:
room_detected (bool) Indicates whether the image depicts a closed indoor space or an outdoor/open environment.
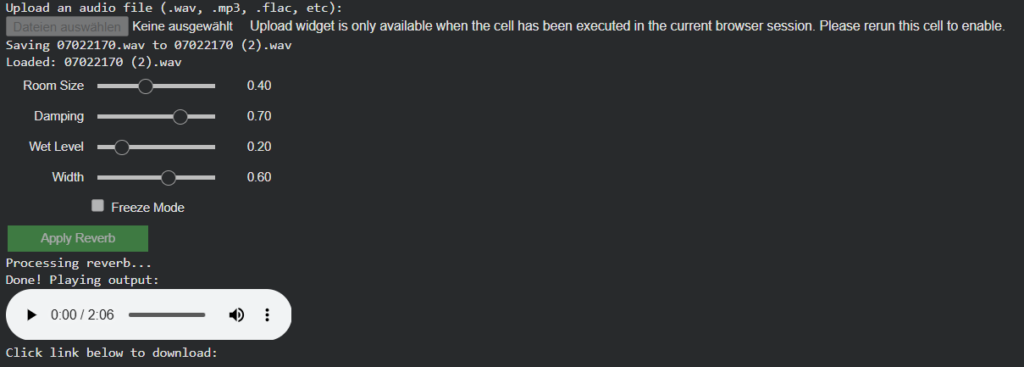
room_size (0.0–1.0) Represents the perceived acoustic size of the room (small rooms → short decay, large spaces → long decay).
damping (0.0–1.0) Estimates high-frequency absorption based on visible materials (soft furnishings, carpets, curtains vs. glass and hard walls).
wet_level (0.0–1.0) Describes how reverberant the space naturally feels.
width (0.0–1.0) Estimates perceived stereo width derived from room proportions and openness.
All parameters are stored flat within the same dictionary as objects, panning, and importance values, forming a single coherent scene representation.
Dereverberation: Explored, Then Intentionally Abandoned
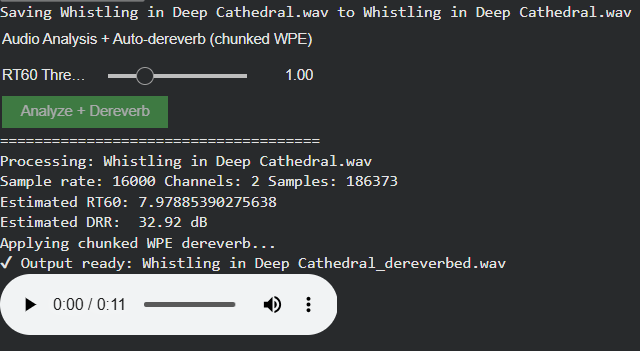
As part of this phase, automatic analysis of existing reverberation (RT60, DRR estimation) and dereverberation was evaluated.
The outcome:
Computationally expensive, especially in Google Colab
Inconsistent and often unsatisfactory audio results
High complexity with limited practical benefit
Decision: Dereverberation is not pursued further in this project. Instead, the system relies on:
Consistent room estimation
Controlled, unified reverb application
Preventive design rather than corrective processing
The next step will be to focus on the analysis of the sounds (especially rt60 and drr values) to make the reverb (if its a closed room) less on the specific sound.
Intelligent Balancing – progress of automated mixing
This development phase introduces a sophisticated dual-layer audio processing system that addresses both proactive and reactive sound masking, creating mixes that are not only visually faithful but also acoustically optimal. Where previous systems focused on semantic accuracy and visual hierarchy, we now ensure perceptual clarity and natural soundscape balance through scientific audio principles.
The Challenge: High-Energy Sounds Dominating the Mix
During testing, we identified a critical issue: certain sounds with naturally high spectral energy (motorcycles, engines, impacts) would dominate the audio mix despite appropriate importance-based volume scaling. Even with our masking analysis and EQ correction, these sounds created an unbalanced listening experience where the mix felt “crowded” by certain elements.
Dual-Layer Solution Architecture
Layer 1: Proactive Energy-Based Gain Reduction
This new function analyzes each sound’s spectral energy across Bark bands (psychoacoustic frequency scale) and applies additional gain reduction to naturally loud sounds. The system:
Measures average and peak energy across 24 Bark bands
Calculates perceived loudness based on spectral distribution
Applies up to -6dB additional reduction to high-energy sounds
Modulates reduction based on visual importance (high importance = less reduction)
Example Application:
Motorcycle sound: -4.5dB additional reduction (high energy in 1-4kHz range)
This represents an evolution from reactive correction to intelligent anticipation, creating audio mixes that are both visually faithful and acoustically balanced. The system now understands not just what sounds should be present, but how they should coexist in the acoustic space, resulting in professional-quality soundscapes that feel natural and well-balanced to the human ear.
Dynamic Audio Balancing Through Visual Importance Mapping
This development phase introduces sophisticated volume control based on visual importance analysis, creating audio mixes that dynamically reflect the compositional hierarchy of the original image. Where previous systems ensured semantic accuracy, we now ensure proportional acoustic representation.
The core advancement lies in importance-based volume scaling. Each detected object’s importance value (0-1 scale from visual analysis) now directly determines its loudness level within a configurable range (-30 dBFS to -20 dBFS). Visually dominant elements receive higher volume placement, while background objects maintain subtle presence.
Key enhancements include:
– Linear importance-to-volume mapping creating natural acoustic hierarchies
The system now distinguishes between foreground emphasis and background ambiance, producing mixes where a visually central “car” (importance 0.9) sounds appropriately prominent compared to a distant “tree” (importance 0.2), while “urban street atmo” provides unwavering environmental foundation.
This represents a significant evolution from flat audio layering to dynamically balanced soundscapes that respect visual composition through intelligent volume distribution.
Best Result Mode (Quality-Focused) The system prioritizes sounds with the highest ratings and download counts, ensuring professional-grade audio quality. It progressively relaxes standards (e.g., from 4.0+ to 2.5+ ratings) if no perfect match is found, guaranteeing a usable sound for every tag.
Random Mode (Diverse Selection) In this mode, the tool ignores quality filters, returning the first valid sound for each tag. This is ideal for quick experiments or when unpredictability is desired or to be sure to achieve different results.
2. Filters: Rating vs. Downloads
Users can further refine searches with two filter preferences:
Rating > Downloads Favors sounds with the highest user ratings, even if they have fewer downloads. This prioritizes subjective quality (e.g., clean recordings, well-edited clips). Example: A rare, pristine “tiger growl” with a 4.8/5 rating might be chosen over a popular but noisy alternative.
Downloads > Rating Prioritizes widely downloaded sounds, which often indicate reliability or broad appeal. This is useful for finding “standard” effects (e.g., a typical phone ring). Example: A generic “clock tick” with 10,000 downloads might be selected over a niche, high-rated vintage clock sound.
If there would be no matching sound for the rating or download approach the system gets to the fallback and uses the hierarchy table privided to change for example maple into tree.
Intelligent Frequency Management
The audio engine now implements Bark Scale Filtering, which represents a significant improvement over the previous FFT peaks approach. By dividing the frequency spectrum into 25 critical bands spanning 20Hz to 20kHz, the system now precisely mirrors human hearing sensitivity. This psychoacoustic alignment enables more natural spectral adjustments that maintain perceptual balance while processing audio content.
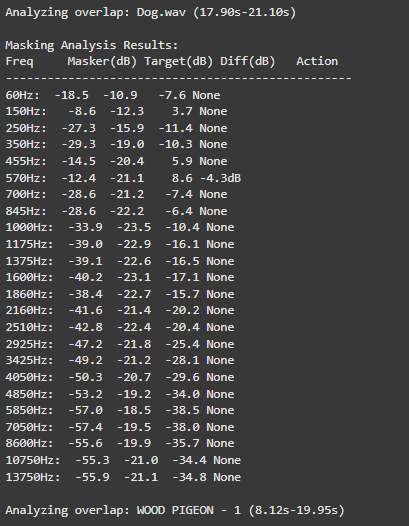
For dynamic equalization, the system features adaptive EQ Activation that intelligently engages only during actual sound clashes. For instance, when two sounds compete at 570Hz, the EQ applies a precise -4.7dB reduction exclusively during the overlapping period.
o preserve audio quality, the system employs Conservative Processing principles. Frequency band reductions are strictly limited to a maximum of -6dB, preventing artificial-sounding results. Additionally, the use of wide Q values (1.0) ensures that EQ adjustments maintain the natural timbral characteristics of each sound source while effectively resolving masking issues.
These core upgrades collectively transform Image Extender’s mixing capabilities, enabling professional-grade audio results while maintaining the system’s generative and adaptive nature. The improvements are particularly noticeable in complex soundscapes containing multiple overlapping elements with competing frequency content.
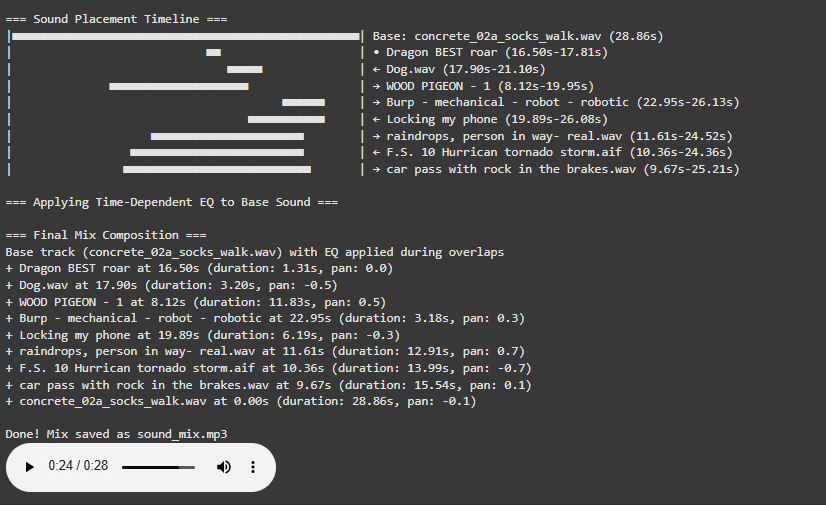
Visualization for a better overview
The newly implemented Timeline Visualization provides unprecedented insight into the mixing process through an intuitive graphical representation.
Researching Automated Mixing Strategies for Clarity and Real-Time Composition
As the Image Extender project continues to evolve from a tagging-to-sound pipeline into a dynamic, spatially aware audio compositing system, this phase focused on surveying and evaluating recent methods in automated sound mixing. My aim was to understand how existing research handles spectral masking, spatial distribution, and frequency-aware filtering—especially in scenarios where multiple unrelated sounds are combined without a human in the loop.
This blog post synthesizes findings from several key research papers and explores how their techniques may apply to our use case: a generative soundscape engine driven by object detection and Freesound API integration. The next development phase will evaluate which of these methods can be realistically adapted into the Python-based architecture.
Adaptive Filtering Through Time–Frequency Masking Detection
A compelling solution to masking was presented by Zhao and Pérez-Cota (2024), who proposed a method for adaptive equalization driven by masking analysis in both time and frequency. By calculating short-time Fourier transforms (STFT) for each track, their system identifies where overlap occurs and evaluates the masking directionality—determining whether a sound acts as a masker or a maskee over time.
These interactions are quantified into masking matrices that inform the design of parametric filters, tuned to reduce only the problematic frequency bands, while preserving the natural timbre and dynamics of the source sounds. The end result is a frequency-aware mixing approach that adapts to real masking events rather than applying static or arbitrary filtering.
Why this matters for Image Extender: Generated mixes often feature overlapping midrange content (e.g., engine hums, rustling leaves, footsteps). By applying this masking-aware logic, the system can avoid blunt frequency cuts and instead respond intelligently to real-time spectral conflicts.
Implementation possibilities:
STFTs: librosa.stft
Masking matrices: pairwise multiplication and normalization (NumPy)
EQ curves: second-order IIR filters via scipy.signal.iirfilter
“This information is then systematically used to design and apply filters… improving the clarity of the mix.” — Zhao and Pérez-Cota (2024)
Iterative Mixing Optimization Using Psychoacoustic Metrics
Another strong candidate emerged from Liu et al. (2024), who proposed an automatic mixing system based on iterative masking minimization. Their framework evaluates masking using a perceptual model derived from PEAQ (ITU-R BS.1387) and adjusts mixing parameters—equalization, dynamic range compression, and gain—through iterative optimization.
The system’s strength lies in its objective function: it not only minimizes total masking but also seeks to balance masking contributions across tracks, ensuring that no source is disproportionately buried. The optimization process runs until a minimum is reached, using a harmony search algorithm that continuously tunes each effect’s parameters for improved spectral separation.
Why this matters for Image Extender: This kind of global optimization is well-suited for multi-object scenes, where several detected elements contribute sounds. It supports a wide range of source content and adapts mixing decisions to preserve intelligibility across diverse sonic elements.
Implementation path:
Masking metrics: critical band energy modeling on the Bark scale
Optimization: scipy.optimize.differential_evolution or other derivative-free methods
EQ and dynamics: Python wrappers (pydub, sox, or raw filter design via scipy.signal)
“Different audio effects… are applied via an iterative Harmony searching algorithm that aims to minimize the masking.” — Liu et al. (2024)
Comparative Analysis
Method
Core Approach
Integration Potential
Implementation Effort
Time–Frequency Masking (Zhao)
Analyze masking via STFT; apply targeted EQ
High — per-event conflict resolution
Medium
Iterative Optimization (Liu)
Minimize masking metric via parametric search
High — global mix clarity
High
Both methods offer significant value. Zhao’s system is elegant in its directness—its per-pair analysis supports fine-grained filtering on demand, suitable for real-time or batch processes. Liu’s framework, while computationally heavier, offers a holistic solution that balances all tracks simultaneously, and may serve as a backend “refinement pass” after initial sound placement.
Looking Ahead
This research phase provided the theoretical and technical groundwork for the next evolution of Image Extender’s audio engine. The next development milestone will explore hybrid strategies that combine these insights:
Implementing a masking matrix engine to detect conflicts dynamically
Building filter generation pipelines based on frequency overlap intensity
Testing iterative mix refinement using masking as an objective metric
Measuring the perceived clarity improvements across varied image-driven scenes
Advanced Automated Sound Mixing with Hierarchical Tag Handling and Spectral Awareness
The Image Extender project continues to evolve in scope and sophistication. What began as a relatively straightforward pipeline connecting object recognition to the Freesound.org API has now grown into a rich, semi-intelligent audio mixing system. This recent development phase focused on enhancing both the semantic accuracy and the acoustic quality of generated soundscapes, tackling two significant challenges: how to gracefully handle missing tag-to-sound matches, and how to intelligently mix overlapping sounds to avoid auditory clutter.
Sound Retrieval Meets Semantic Depth
One of the core limitations of the original approach was its dependence on exact tag matches. If no sound was found for a detected object, that tag simply went silent. To address this, I introduced a multi-level fallback system based on a custom-built CSV ontology inspired by Google’s AudioSet.
This ontology now contains hundreds of entries, organized into logical hierarchies that progress from broad categories like “Entity” or “Animal” to highly specific leaf nodes like “White-tailed Deer,” “Pickup Truck,” or “Golden Eagle.” When a tag fails, the system automatically climbs upward through this tree, selecting a more general fallback—moving from “Tiger” to “Carnivore” to “Mammal,” and finally to “Animal” if necessary.
Implementation of temporal composition
Initial versions of Image Extender merely stacked sounds on top of each other by only using the spatial composition in the form of panning. Now, the mixing system behaves more like a simplified DAW (Digital Audio Workstation). Key improvements introduced in this iteration include:
Random temporal placement: Shorter sound files are distributed at randomized time positions across the duration of the mix, reducing sonic overcrowding and creating a more natural flow.
Automatic fade-ins and fade-outs: Each sound is treated with short fades to eliminate abrupt onsets and offsets, improving auditory smoothness.
Mix length based on longest sound: Instead of enforcing a fixed duration, the mix now adapts to the length of the longest inserted file, which is always placed at the beginning to anchor the composition.
These changes give each generated audio scene a sense of temporal structure and stereo space, making them more immersive and cinematic.
Frequency-Aware Mixing: Avoiding Spectral Masking
A standout feature developed during this phase was automatic spectral masking avoidance. When multiple sounds overlap in time and occupy similar frequency bands, they can mask each other, causing a loss of clarity. To mitigate this, the system performs the following steps:
Before placing a sound, the system extracts the portion of the mix it will overlap with.
Both the new sound and the overlapping mix segment are analyzed via FFT (Fast Fourier Transform) to determine their dominant frequency bands.
If the analysis detects significant overlap in frequency content, the system takes one of two corrective actions:
Attenuation: The new sound is reduced in volume (e.g., -6 dB).
EQ filtering: Depending on the nature of the conflict, a high-pass or low-pass filter is applied to the new sound to move it out of the way spectrally.
This spectral awareness doesn’t reach the complexity of advanced mixing, but it significantly reduces the most obvious masking effects in real-time-generated content—without user input.
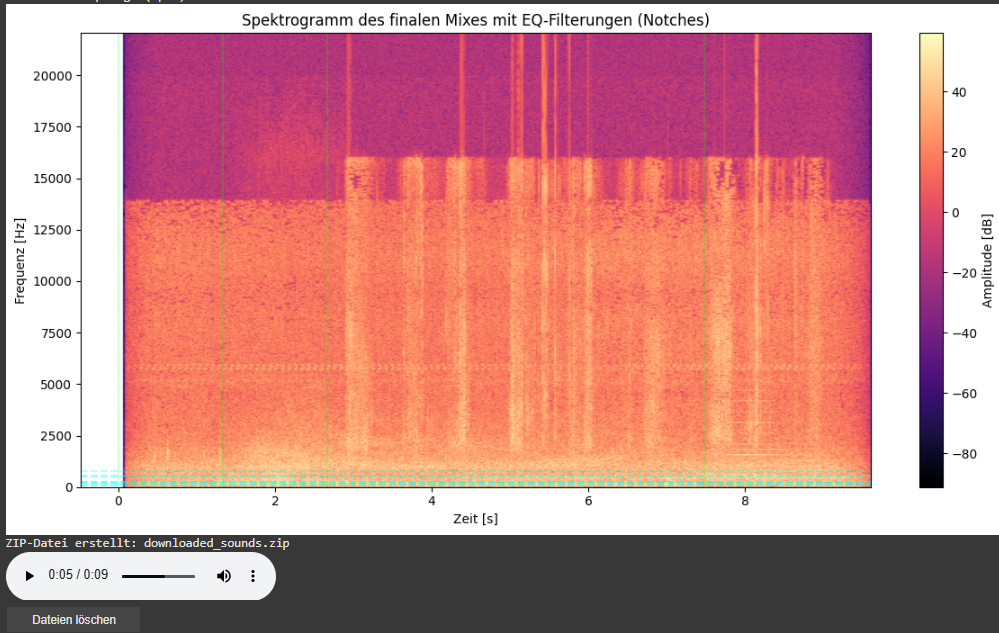
Spectrogram Visualization of the Final Mix
As part of this iteration, I also added a spectrogram visualization of the final mix. This visual feedback provides a frequency-time representation of the soundscape and highlights which parts of the spectrum have been affected by EQ filtering.
Vertical dashed lines indicate the insertion time of each new sound.
Horizontal lines mark the dominant frequencies of the added sound segments. These often coincide with spectral areas where notch filters have been applied to avoid collisions with the existing mix.
This visualization allows for easier debugging, improved understanding of frequency interactions, and serves as a useful tool when tuning mixing parameters or filter behaviors.
Looking Ahead
As the architecture matures, future milestones are already on the horizon. We aim to implement:
Visual feedback: A real-time timeline that shows audio placement, duration, and spectral content.
Advanced loudness control: Integration of dynamic range compression and LUFS-based normalization for output consistency.