Room-Aware Mixing – From Image Analysis to Coherent Acoustic Spaces
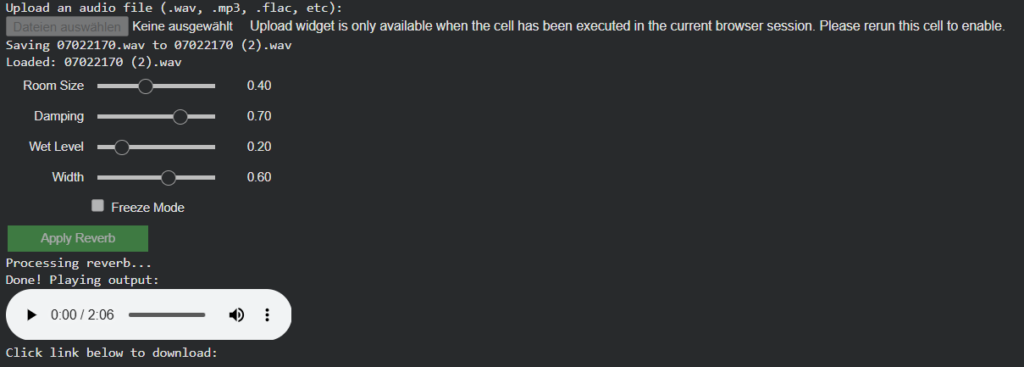
Instead of attempting to recover exact physical properties, the system derives normalized, perceptual room parameters from visual cues such as geometry, materials, furnishing density, and openness. These parameters are intentionally abstracted to work with algorithmic reverbs.
The introduced parameters are:
room_detected (bool) Indicates whether the image depicts a closed indoor space or an outdoor/open environment.
room_size (0.0–1.0) Represents the perceived acoustic size of the room (small rooms → short decay, large spaces → long decay).
damping (0.0–1.0) Estimates high-frequency absorption based on visible materials (soft furnishings, carpets, curtains vs. glass and hard walls).
wet_level (0.0–1.0) Describes how reverberant the space naturally feels.
width (0.0–1.0) Estimates perceived stereo width derived from room proportions and openness.
All parameters are stored flat within the same dictionary as objects, panning, and importance values, forming a single coherent scene representation.
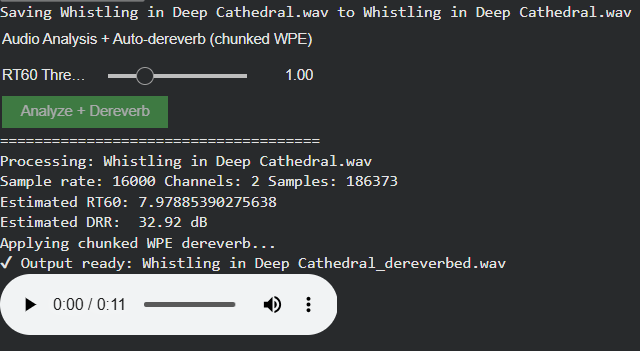
Dereverberation: Explored, Then Intentionally Abandoned
As part of this phase, automatic analysis of existing reverberation (RT60, DRR estimation) and dereverberation was evaluated.
The outcome:
Computationally expensive, especially in Google Colab
Inconsistent and often unsatisfactory audio results
High complexity with limited practical benefit
Decision: Dereverberation is not pursued further in this project. Instead, the system relies on:
Consistent room estimation
Controlled, unified reverb application
Preventive design rather than corrective processing
The next step will be to focus on the analysis of the sounds (especially rt60 and drr values) to make the reverb (if its a closed room) less on the specific sound.
Researching Automated Mixing Strategies for Clarity and Real-Time Composition
As the Image Extender project continues to evolve from a tagging-to-sound pipeline into a dynamic, spatially aware audio compositing system, this phase focused on surveying and evaluating recent methods in automated sound mixing. My aim was to understand how existing research handles spectral masking, spatial distribution, and frequency-aware filtering—especially in scenarios where multiple unrelated sounds are combined without a human in the loop.
This blog post synthesizes findings from several key research papers and explores how their techniques may apply to our use case: a generative soundscape engine driven by object detection and Freesound API integration. The next development phase will evaluate which of these methods can be realistically adapted into the Python-based architecture.
Adaptive Filtering Through Time–Frequency Masking Detection
A compelling solution to masking was presented by Zhao and Pérez-Cota (2024), who proposed a method for adaptive equalization driven by masking analysis in both time and frequency. By calculating short-time Fourier transforms (STFT) for each track, their system identifies where overlap occurs and evaluates the masking directionality—determining whether a sound acts as a masker or a maskee over time.
These interactions are quantified into masking matrices that inform the design of parametric filters, tuned to reduce only the problematic frequency bands, while preserving the natural timbre and dynamics of the source sounds. The end result is a frequency-aware mixing approach that adapts to real masking events rather than applying static or arbitrary filtering.
Why this matters for Image Extender: Generated mixes often feature overlapping midrange content (e.g., engine hums, rustling leaves, footsteps). By applying this masking-aware logic, the system can avoid blunt frequency cuts and instead respond intelligently to real-time spectral conflicts.
Implementation possibilities:
STFTs: librosa.stft
Masking matrices: pairwise multiplication and normalization (NumPy)
EQ curves: second-order IIR filters via scipy.signal.iirfilter
“This information is then systematically used to design and apply filters… improving the clarity of the mix.” — Zhao and Pérez-Cota (2024)
Iterative Mixing Optimization Using Psychoacoustic Metrics
Another strong candidate emerged from Liu et al. (2024), who proposed an automatic mixing system based on iterative masking minimization. Their framework evaluates masking using a perceptual model derived from PEAQ (ITU-R BS.1387) and adjusts mixing parameters—equalization, dynamic range compression, and gain—through iterative optimization.
The system’s strength lies in its objective function: it not only minimizes total masking but also seeks to balance masking contributions across tracks, ensuring that no source is disproportionately buried. The optimization process runs until a minimum is reached, using a harmony search algorithm that continuously tunes each effect’s parameters for improved spectral separation.
Why this matters for Image Extender: This kind of global optimization is well-suited for multi-object scenes, where several detected elements contribute sounds. It supports a wide range of source content and adapts mixing decisions to preserve intelligibility across diverse sonic elements.
Implementation path:
Masking metrics: critical band energy modeling on the Bark scale
Optimization: scipy.optimize.differential_evolution or other derivative-free methods
EQ and dynamics: Python wrappers (pydub, sox, or raw filter design via scipy.signal)
“Different audio effects… are applied via an iterative Harmony searching algorithm that aims to minimize the masking.” — Liu et al. (2024)
Comparative Analysis
Method
Core Approach
Integration Potential
Implementation Effort
Time–Frequency Masking (Zhao)
Analyze masking via STFT; apply targeted EQ
High — per-event conflict resolution
Medium
Iterative Optimization (Liu)
Minimize masking metric via parametric search
High — global mix clarity
High
Both methods offer significant value. Zhao’s system is elegant in its directness—its per-pair analysis supports fine-grained filtering on demand, suitable for real-time or batch processes. Liu’s framework, while computationally heavier, offers a holistic solution that balances all tracks simultaneously, and may serve as a backend “refinement pass” after initial sound placement.
Looking Ahead
This research phase provided the theoretical and technical groundwork for the next evolution of Image Extender’s audio engine. The next development milestone will explore hybrid strategies that combine these insights:
Implementing a masking matrix engine to detect conflicts dynamically
Building filter generation pipelines based on frequency overlap intensity
Testing iterative mix refinement using masking as an objective metric
Measuring the perceived clarity improvements across varied image-driven scenes
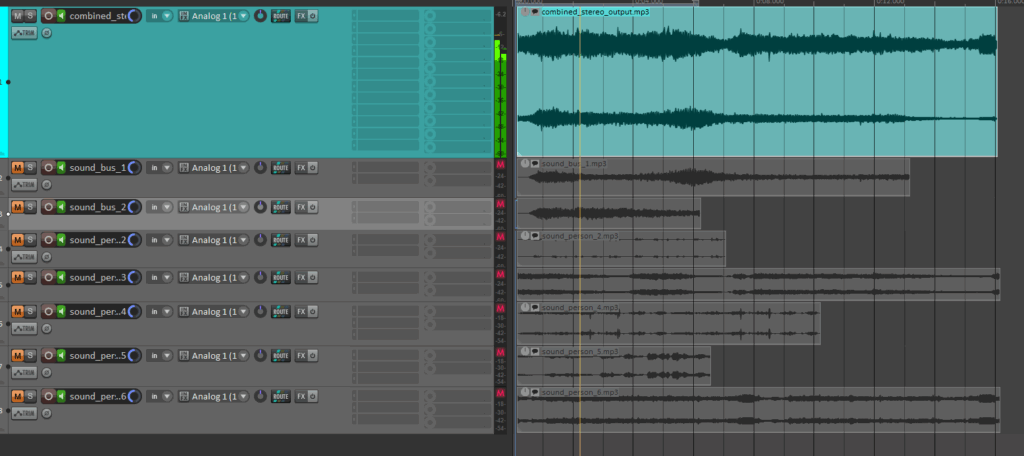
Mixing of the automatically searched audio files into one combined stereo file:
In this latest update, I’ve implemented several new features to create the first layer of an automated sound mixing system for the object recognition tool. The tool now automatically adjusts pan values and applies attenuation to ensure a balanced stereo mix, while seamlessly handling multiple tracks. This helps avoid overload and guarantees smooth audio mixing.
check of the automatically searched and downloaded files + the automatically generated combined audiofile
A key new feature is the addition of a sound_pannings array, which holds unique panning values for each sound based on the position of the object’s bounding box within an image. This ensures that each sound associated with a recognized object gets an individualized panning, calculated from its horizontal position within the image, for a more dynamic and immersive experience.
display of the sound panning values [-1 left, 1 right]
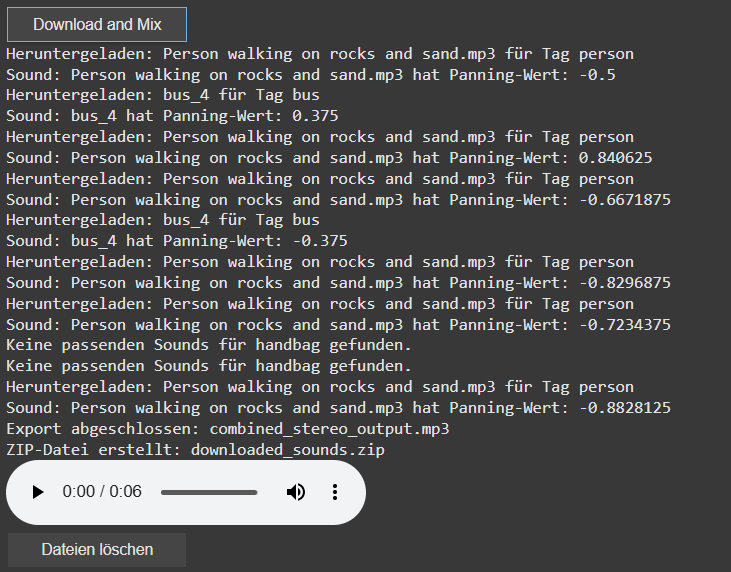
I’ve also introduced a system to automatically download sound files directly into Google Colab’s file system. This eliminates the need for managing local folders. Users can now easily preview audio within the notebook, which adds interactivity and helps visualize the results instantly.
The sound downloading process has also been revamped. The filters for the search can now be saved via a buttonclick to apply for the search and download for the audiofile. Currently for each tags there are 10 sounds per tag preloaded, with each sound randomly selected to avoid duplication but ensure the use of multiple times of the same tag. A sound is only downloaded if it hasn’t been used before. If all sound options for a tag are exhausted, no sound will be downloaded for that tag.
Additionally, I’ve added the ability to create a ZIP file that includes all the downloaded sounds as well as the final mixed audio output. This makes it easy to download and share the files. To keep things organized, I’ve also introduced a delete button that removes all downloaded files once they are no longer needed. The interface now includes buttons for controlling the download, file cleanup, and audio playback, simplifying the process for users.
Looking ahead, I plan to continue refining the system by working on better mixing techniques, focusing on aspects like spectrum, frequency, and the overall importance of the sounds. Future updates will also look at integrating volume control and more far in the future an LLM Model that can check the correctness of the found file title.
New features in the object recognition and test run for images:
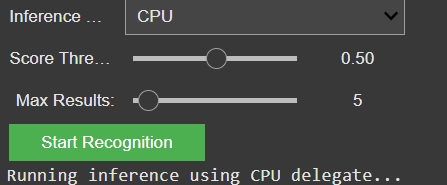
Since the initial freesound.org and GeminAI setup, I have added several improvements. You can now choose between different object recognition models and adjust settings like the number of detected objects and the minimum confidence threshold.
GUI for the settings of the model
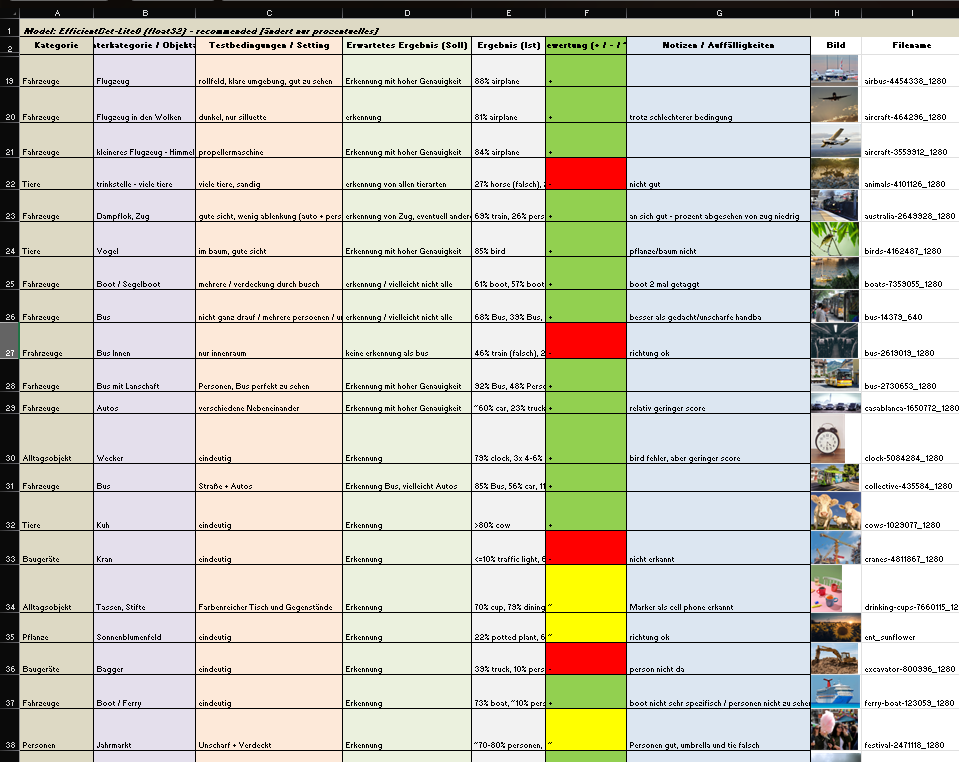
I also created a detailed testing matrix, using a wide range of images to evaluate detection accuracy. Due to that there might be the change of the model later on, because it seems the gemini api only has a very basic pool of tags and is also not a good training in every category.
Test of images for the object recognition
It is still reliable for these basic tags like “bird”, “car”, “tree”, etc. And for these tags it also doesn’t really matter if theres a lot of shadow, you only see half of the object or even if its blurry. But because of the lack of specific tags I will look into models or APIs that offer more fine-grained recognition.
Coming up: I’ll be working on whether to auto-play or download the selected audio files including layering sounds, adjusting volumes, experimenting with EQ and filtering — all to make the playback more natural and immersive. Also, I will think about categorization and moving the tags into a layer system. Beside that I am going to check for other object recognition models, but I might stick to the gemini api for prototyping a bit more and change the model later.
Integration of AI-Object Recognition in the automated audio file search process:
After setting up the initial interface for the freesound.org API and confirming everything works with test tags and basic search filters, the next major milestone is now in motion: AI-based object recognition using the GeminAI API.
The idea is to feed in an image (or a batch of them), let the AI detect what’s in it, and then use those recognized tags to trigger an automated search for corresponding sounds on freesound.org. The integration already loads the detected tags into an array, which is then automatically passed on to the sound search. This allows the system to dynamically react to the content of an image and search for matching audio files — no manual tagging needed anymore.
So far, the detection is working pretty reliably for general categories like “bird”, “car”, “tree”, etc. But I’m looking into models or APIs that offer more fine-grained recognition. For instance, instead of just “bird”, I’d like it to say “sparrow”, “eagle”, or even specific songbird species if possible. This would make the whole sound mapping feel much more tailored and immersive.
A list of test images will be prepared, but there’s already a testing matrix for different objects, situations, scenery and technical differences
On the freesound side, I’ve got the basic query parameters set up: tag search, sample rate, file type, license, and duration filters. There’s room to expand this with additional parameters like rating, bit depth, and maybe even a random selection toggle to avoid repetition when the same tag comes up multiple times.
Coming up: I’ll be working on whether to auto-play or download the selected audio files, and starting to test how the AI-generated tags influence the mood and quality of the soundscape. The long-term plan includes layering sounds, adjusting volumes, experimenting with EQ and filtering — all to make the playback more natural and immersive.
Shift of intention of the project due to time plan:
By narrowing down the topic to ensure the feasibility of this project the focus or main purpose of the project will be the artistic approach. The tool will still combine the use of direct image to audio translation and the translation via sonification into a more abstract form. The main use cases will be generating unique audio samples for creative applications, such as sound design for interactive installations, brand audio identities, or matching image soundscapes and the possibility to be a versatile instrument for experimental media artists and display tool for image information.
By further research on different possibilities of sonification of image data and development of the sonification language itself the translation and display purpose is going to get more clear within the following weeks.
Testing of Google Gemini API for AI Object and Image Recognition:
The first testing of the Google Gemini Api started well. There are different models for dedicated object recognition and image recognition itself which can be combined to analyze pictures in terms of objects and partly scenery. These models (SSD, EfficientNET,…) create similar results but not always the same. It might be an option to make it selectable for the user (so that in a failure case a different model can be tried and may give better results). The scenery recognition itself tends to be a problem. It may be a possibility to try out different apis.
The data we get from this AI model is a tag for the recognized objects or image content and a percentage of the probability.
The next steps for the direct translation of it into realistic sound representations will be to test the possibility of using the api of freesound.org to search directly and automated for the recognized object tags and load matching audio files. These search calls also need to filter by copyright type of the sounds and a choosing rule / algorithm needs to be created.
object recognition: efficient float 16 model (Photo by Jason Oh on unsplash)object recognition: image splice test – recognition fail (Photo by Jason Oh on unsplash)object recognition: accurate but low score (Photo: https://lernen.zoner.de/)object recognition (photo: zdf.de)
Research on sonification of images / video material and different approaches:
The world of image sonification is rich with diverse techniques, each offering unique ways to transform visual data into auditory experiences. The world of image sonification is rich with diverse techniques, each offering unique ways to map visual data into auditory experiences. One of the most straightforward methods is raster scanning, introduced by Yeo and Berger. This technique maps the brightness values of grayscale image pixels directly to audio samples, creating a one-to-one correspondence between visual and auditory data. By scanning an image line by line, from top to bottom, the system generates a sound that reflects the texture and patterns of the image. For example, a smooth gradient might produce a steady tone, while a highly textured image could result in a more complex, evolving soundscape. The process is fully reversible, allowing for both image sonification and sound visualization, making it a versatile tool for artists and researchers alike. This method is particularly effective for sonifying image textures and exploring the auditory representation of visual filters, such as “patchwork” or “grain” effects.(Yeo and Berger, 2006)
Principle raster scanning (Yeo and Berger, 2006)
In contrast, Audible Panorama (Huang et al. 2019) automates sound mapping for 360° panorama images used in virtual reality (VR). It detects objects using computer vision, estimates their depth, and assigns spatialized audio from a database. For example, a car might trigger engine sounds, while a person generates footsteps, creating an immersive auditory experience that enhances VR realism. A user study confirmed that spatial audio significantly improves the sense of presence. It contains a interesting concept regarding to choosing a random audio file from a sound library to avoid producing similar or same results. Also it mentions the aspect of postprocessing the audios which also would be a relevant aspect for the image extender project.
principle audible panorama (Huang et al. 2019)
Another approach, HindSight (Schoop, Smith, and Hartmann 2018), focuses on real-time object detection and sonification in 360° video. Using a head-mounted camera and neural networks, it detects objects like cars and pedestrians, then sonifies their position and danger level through bone conduction headphones. Beeps increase in tempo and pan to indicate proximity and direction, providing real-time safety alerts for cyclists.
Finally, Sonic Panoramas (Kabisch, Kuester, and Penny 2005) takes an interactive approach, allowing users to navigate landscape images while generating sound based on their position. Edge detection extracts features like mountains or forests, mapping them to dynamic soundscapes. For instance, a mountain ridge might produce a resonant tone, while a forest creates layered, chaotic sounds, blending visual and auditory art. It also mentions different approaches for sonification itself. For example the idea of using micro (timbre, pitch and melody) and macro level (rhythm and form) mapping.
principle sonic panoramas (Kabisch, Kuester, and Penny 2005)
Each of these methods—raster scanning, Audible Panorama, HindSight, and Sonic Panoramas—demonstrates the versatility of sonification as a tool for transforming visual data into sound and lead keeping these different approaches in mind for developing my own sonification language or mapping method. It also leads to further research by checking some useful references they used in their work for a deeper understanding of sonification and extending the possibilities.
References
Huang, Haikun, Michael Solah, Dingzeyu Li, and Lap-Fai Yu. 2019. “Audible Panorama: Automatic Spatial Audio Generation for Panorama Imagery.” In Proceedings of the 2019 CHI Conference on Human Factors in Computing Systems, 1–11. Glasgow, Scotland: ACM. https://doi.org/10.1145/3290605.3300851.
Kabisch, Eric, Falko Kuester, and Simon Penny. 2005. “Sonic Panoramas: Experiments with Interactive Landscape Image Sonification.” In Proceedings of the 2005 International Conference on Artificial Reality and Telexistence (ICAT), 156–163. Christchurch, New Zealand: HIT Lab NZ.
Schoop, Eldon, James Smith, and Bjoern Hartmann. 2018. “HindSight: Enhancing Spatial Awareness by Sonifying Detected Objects in Real-Time 360-Degree Video.” In Proceedings of the 2018 CHI Conference on Human Factors in Computing Systems, 1–12. Montreal, QC, Canada: ACM. https://doi.org/10.1145/3173574.3173717.
Yeo, Woon Seung, and Jonathan Berger. 2006. “Application of Raster Scanning Method to Image Sonification, Sound Visualization, Sound Analysis and Synthesis.” In Proceedings of the 9th International Conference on Digital Audio Effects (DAFx-06), 311–316. Montreal, Canada: DAFx.