Integration of AI-Object Recognition in the automated audio file search process:
After setting up the initial interface for the freesound.org API and confirming everything works with test tags and basic search filters, the next major milestone is now in motion: AI-based object recognition using the GeminAI API.
The idea is to feed in an image (or a batch of them), let the AI detect what’s in it, and then use those recognized tags to trigger an automated search for corresponding sounds on freesound.org. The integration already loads the detected tags into an array, which is then automatically passed on to the sound search. This allows the system to dynamically react to the content of an image and search for matching audio files — no manual tagging needed anymore.
So far, the detection is working pretty reliably for general categories like “bird”, “car”, “tree”, etc. But I’m looking into models or APIs that offer more fine-grained recognition. For instance, instead of just “bird”, I’d like it to say “sparrow”, “eagle”, or even specific songbird species if possible. This would make the whole sound mapping feel much more tailored and immersive.
A list of test images will be prepared, but there’s already a testing matrix for different objects, situations, scenery and technical differences
On the freesound side, I’ve got the basic query parameters set up: tag search, sample rate, file type, license, and duration filters. There’s room to expand this with additional parameters like rating, bit depth, and maybe even a random selection toggle to avoid repetition when the same tag comes up multiple times.
Coming up: I’ll be working on whether to auto-play or download the selected audio files, and starting to test how the AI-generated tags influence the mood and quality of the soundscape. The long-term plan includes layering sounds, adjusting volumes, experimenting with EQ and filtering — all to make the playback more natural and immersive.
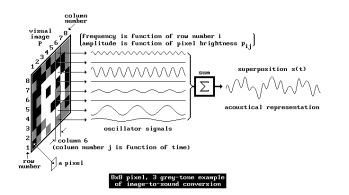
Research on sonification of images / video material and different approaches – focus on RGB
The paper by Kopecek and Ošlejšek presents a system that enables visually impaired users to perceive color images through sound using a semantic color model. Each primary color (such as red, green, or blue) is assigned a unique sound, and colors in an image are approximated by the two closest primary colors. These are represented through two simultaneous tones, with volume indicating the proportion of each color. Users can explore images by selecting pixels or regions using input devices like a touchscreen or mouse. The system calculates the average color of the selected area and plays the corresponding sounds. Distinct audio cues indicate image boundaries, and sounds can be either synthetic or instrument-based, with timbre and pitch helping to differentiate them. Users can customize colors and sounds for a more personalized experience. This approach allows for dynamic, efficient exploration of images and supports navigation via annotated SVG formats.
image seperation by Kopecek and Ošlejšek
The review by Sarkar, Bakshi, and Sa offers an overview of various image sonification methods designed to help visually impaired users interpret visual scenes through sound. It covers techniques such as raster scanning, query-based, and path-based approaches, where visual data like pixel intensity and position are mapped to auditory cues. Systems like vOICe and NAVI use high and low-frequency tones to represent image regions vertically. The paper emphasizes the importance of transfer functions, which link image properties to sound attributes such as pitch, volume, and frequency. Different rendering methods—like audification, earcons, and parameter mapping—are discussed in relation to human auditory perception. Special attention is given to color sonification, including the semantic color model introduced by Kopecek and Ošlejšek, which improves usability through clearly distinguishable tones. The paper also explores applications in fields such as medical imaging, algorithm visualization, and network analysis, and briefly touches on sound-to-image conversions.
Principles of the image-to-sound mapping
Matta, Rudolph, and Kumar propose the theoretical system “Auditory Eyes,” which converts visual data into auditory and tactile signals to support blind users. The system comprises three main components: an image encoder that uses edge detection and triangulation to estimate object location and distance; a mapper that translates features like motion, brightness, and proximity into corresponding sound and vibration cues; and output generators that produce sound using tools like Csound and tactile feedback via vibrations. Motion is represented using effects like Doppler shift and interaural time difference, while spatial positioning is conveyed through head-related transfer functions. Brightness is mapped to pitch, and edges are conveyed through tone duration. The authors emphasize that combining auditory and tactile information can create a richer and more intuitive understanding of the environment, making the system potentially very useful for real-world navigation and object recognition.
References
Kopecek, Ivan, and Radek Ošlejšek. 2008. “Hybrid Approach to Sonification of Color Images.” In Third 2008 International Conference on Convergence and Hybrid Information Technology, 721–726. IEEE. https://doi.org/10.1109/ICCIT.2008.152.
Sarkar, Rajib, Sambit Bakshi, and Pankaj K Sa. 2012. “Review on Image Sonification: A Non-visual Scene Representation.” In 1st International Conference on Recent Advances in Information Technology (RAIT-2012), 1–5. IEEE. https://doi.org/10.1109/RAIT.2012.6194495.
Matta, Suresh, Heiko Rudolph, and Dinesh K Kumar. 2005. “Auditory Eyes: Representing Visual Information in Sound and Tactile Cues.” In Proceedings of the 13th European Signal Processing Conference (EUSIPCO 2005), 1–5. Antalya, Turkey. https://www.researchgate.net/publication/241256962.