After converting heart-rate data into drums and HRV energy into melodic tracks, I needed a tiny helper that outputs nothing but automation. The idea was to pull every physiologic stream—HR, SDNN, RMSSD, VLF, LF, HF plus the LF / HF ratio—and stamp each one into its own MIDI track as CC-1 so that in the DAW every signal can be mapped to a knob, filter or layer-blend. The script must first look at all CSV files in a session, find the global minimum and maximum for every column, and apply those bounds consistently. Timing stays on the same 75 BPM / 0.1 s grid we used for the drums and notes, making one CSV row equal one 1⁄32-note. With that in mind, the core design is just constants, a value-to-CC rescaler, a loop that writes control changes, and a batch driver that walks the folder.
If you want to see the full, visit: https://github.com/ninaeba/EmbodiedResonance
# ─── Default Configuration ───────────────────────────────────────────
DEF_BPM = 75 # Default tempo
CSV_GRID = 0.1 # Time between CSV samples (s) ≙ 1/32-note @75 BPM
SIGNATURE = "8/8" # Eight-cell bar; enough for pure CC data
CC_NUMBER = 1 # We store everything on Mod Wheel
CC_TRACKS = ["HR", "SDNN", "RMSSD", "VLF", "LF", "HF", "LF_HF"]
BEAT_PER_GRID = 1 / 32 # Grid resolution in beats
The first helper, map_to_cc, squeezes any value into the 0-127 range. It is the only place where scaling happens, so if you ever need logarithmic behaviour you change one line here and every track follows.
def map_to_cc(val: float, vmin: float, vmax: float) -> int:
norm = np.clip((val - vmin) / (vmax - vmin), 0, 1)
return int(round(norm * 127))generate_cc_tracks loads a single CSV, back-fills gaps, creates one PrettyMIDI container and pins the bar length with a time-signature event. Then it iterates over CC_TRACKS; if the column exists it opens a fresh instrument named after the signal and sprinkles CC messages along the grid. Beat-to-second conversion is the same one-liner used elsewhere in the project.
for name in CC_TRACKS:
if name not in df.columns:
continue
vals = df[name].to_numpy()
vmin, vmax = minmax[name]inst = pm.Instrument(program=0, is_drum=False, name=f"{name}_CC1")
for i in range(len(vals) - 1):
beat = i * BEAT_PER_GRID * 4 # 1/32-note → quarter-note space
t = beat * 60.0 / bpm
cc_val = map_to_cc(vals[i], vmin, vmax)
inst.control_changes.append(
pm.ControlChange(number=CC_NUMBER, value=cc_val, time=t)
)
midi.instruments.append(inst)The wrapper main is pure housekeeping: parse CLI flags, list every *.csv, compute global min-max per signal, and then hand each file to generate_cc_tracks. Consistent scaling is guaranteed because min-max is frozen before any writing starts.
minmax: dict[str, tuple[float, float]] = {}
for name in CC_TRACKS:
vals = []
for f in csv_files:
df = pd.read_csv(f, usecols=lambda c: c.upper() == name)
if name in df.columns:
vals.append(df[name].to_numpy())
if vals:
all_vals = np.concatenate(vals)
minmax[name] = (np.nanmin(all_vals), np.nanmax(all_vals))Each CSV turns into *_cc_tracks.mid containing seven tracks—HR, SDNN, RMSSD, VLF, LF, HF, LF_HF—each packed with CC-1 data at 1⁄32-note resolution. Drop the file into Ableton, assign a synth or effect per track, map the Mod Wheel to whatever parameter makes sense, and the physiology animates the mix in real time.
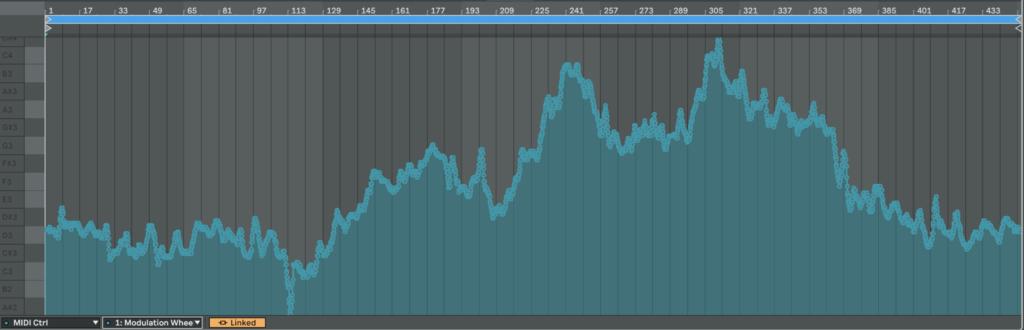
As a result, we get CC automation that we can easily map to something else or just copy automation somewhere else:
Here is an example of HR from patient 115 mapped from 0 to 127 in CC: